
数据科学家必备的5种离群点/异常检测方法
什么是异常/异常值?
在统计学中,离群值是不属于某个总体的数据点,它是一种与其他值相差甚远的异常观察,是一种与其他结构良好的数据不同的观察值。
例如,您可以清楚地看到列表中的异常值:[20,24,22,19,29,184300,30,18]。当观察值只是一组数字并且是一维时,很容易识别它,但是当你有数千个观察值或多维值时,你需要更聪明的方法来检测这些值。这就是本文将要介绍的内容。
为什么我们关心异常?
离群点的检测是数据挖掘的核心问题之一。数据的不断扩展和持续增长以及物联网设备的普及,使我们重新思考我们处理异常的方式,以及通过观察这些异常情况可以构建的用例。
我们现在有智能手表和腕带,可以每隔几分钟检测我们的心跳。检测心跳数据中的异常有助于预测心脏病。交通模式的异常有助于预测事故。它还可以用来识别网络基础设施和服务器之间的通信瓶颈。因此,建立在检测异常之上的用例和解决方案是无限的。
我们需要检测异常的另一个原因是,在为机器学习模型准备数据集时,检测所有异常值非常重要,要么去掉它们,要么分析它们,以了解为什么会有异常。
现在,让我们从最简单的方法开始探索5种常见的异常检测方法。
方法1 - 标准差:
在统计学中,如果一个数据分布近似正态分布,那么大约68%的数据值在平均值的一个标准差内,约95%在两个标准差内,约99.7%在三个标准差内。
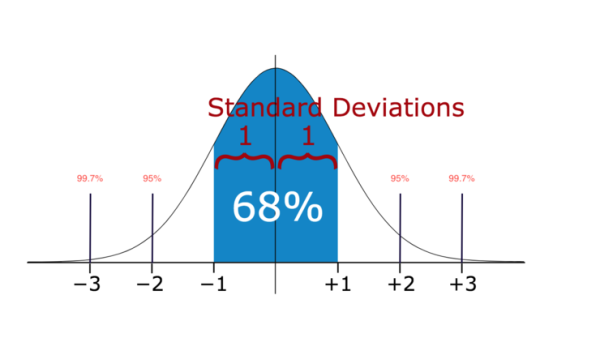
因此,如果有任何数据点超过标准偏差的3倍,那么这些点很可能是异常或异常值。
让我们看看代码。
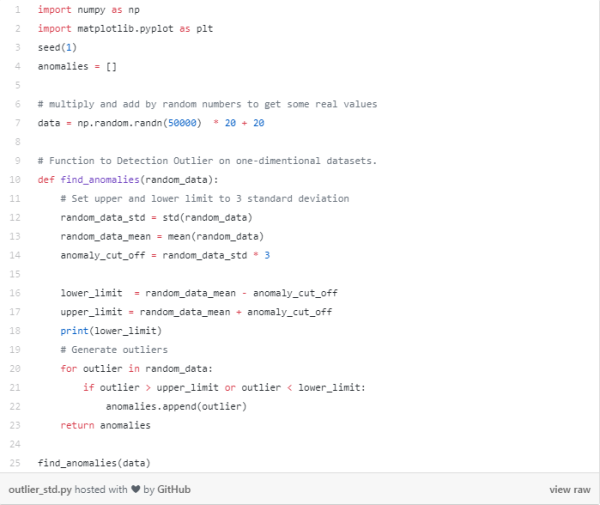
此代码的输出是一个值大于80小于-40的值的列表。请注意,我传递的数据集是一维数据集。现在,让我们探索多维数据集的更高级方法。
方法2 - 箱体图
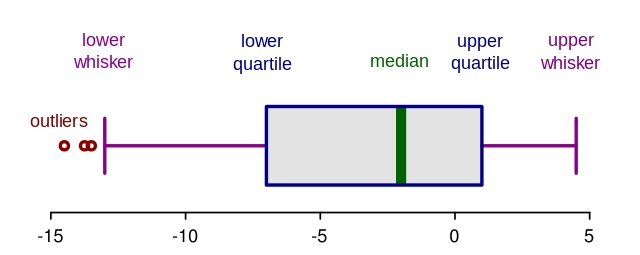
箱体图是通过分位数对数值数据的图形化描述。这是一种非常简单但有效的方法来可视化异常值。把上下胡须(whisker)看作是数据分布的边界。任何显示在胡须上方或下方的数据点都可以被视为异常值或异常值。下面是绘制箱体图的代码:
import seaborn as sns
import matplotlib.pyplot as plt
sns.boxplot(data=random_data)
上面的代码显示下面的图。如您所见,它认为高于75或低于-35的所有数据都是异常值。结果与上述方法1非常接近。
箱体图剖析:
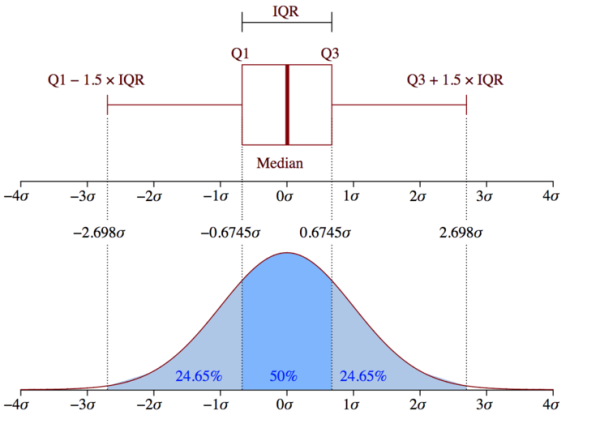
四分位间距(IQR)的概念用于构建箱线图。IQR是统计学中的一个概念,通过将数据集分成四分位数来衡量统计离散度和数据可变性。
简单地说,根据数据的值以及它们与整个数据集的比较,任何数据集或任何一组观测值被划分为四个定义的区间。四分位数将数据分为三个点和四个区间。
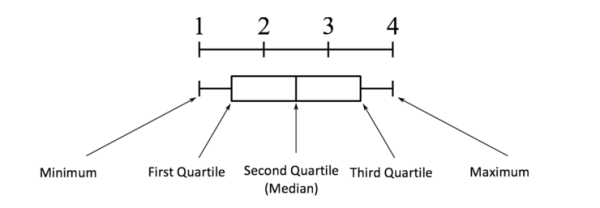
四分位间距(IQR)很重要,因为它用于定义异常值。它是第三个四分位数和第一个四分位数之间的差值(IQR=Q3-Q1)。这种情况下的异常值定义为低于(Q1−1.5x IQR)或boxplot下须或以上(Q3+1.5x IQR)或boxplot上须的观测值。
方法3-DBScan聚类:
DBScan是一种将数据分组的聚类算法。它也可以作为一种基于密度的异常检测方法,无论是单维数据还是多维数据。其他的聚类算法,如k-means 和hierarchal聚类也可以用来检测异常值。在本例中,我将向您展示一个使用DBScan的示例,但是在开始之前,让我们先介绍一些重要的概念。DBScan有三个重要概念:
核心点:为了理解核心点的概念,我们需要关注一些用于定义DBScan作业的超参数。第一个超参数(HP)是min_samples。这只是组成集群所需的最小核心点数量。第二重要的超参数HP是eps。eps是两个样本被视为在同一个聚类之间的最大距离。
边界点与核心点在同一个集群中,但距离集群中心远得多。
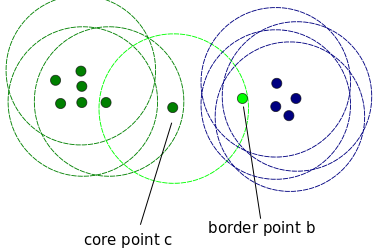
其他的一切都被称为噪声点,那些是不属于任何簇的数据点。它们可以是异常的或非异常的,需要进一步的研究。现在,让我们看看代码。
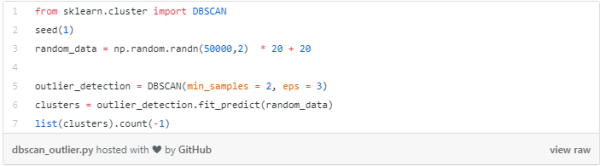
以上代码的输出是94。这是噪声点的总数。SKLearn将噪波点标记为(-1)。这种方法的缺点是维数越高,精度就越低。你还需要做一些假设,比如估计eps的确切值,这可能很有挑战性。
方法4-孤立森林:
孤立森林是一种无监督学习算法,属于集成决策树家族。这种方法不同于以往的所有方法。之前所有的方法都是试图找到数据的正常区域,然后识别出这个定义区域之外的任何异常值或异常值。
这种方法的效果不同。它显式地隔离异常值,而不是通过为每个数据点分配分数来分析和构造正常点和区域。它利用了一个事实,即异常是少数数据点,并且它们的属性值与正常实例的属性值大不相同。该算法适用于高维数据集,是一种非常有效的异常检测方法。由于本文关注的是实现,而不是技术诀窍,因此我将不再进一步讨论算法的工作原理。此文将详细介绍它的工作原理。
现在,让我们探索一下代码:
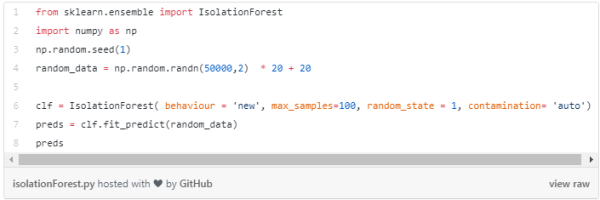
此代码将输出数组中每个数据点的预测。如果结果为-1,则表示此特定数据点为异常值。如果结果为1,则表示数据点不是异常值。
方法5-随机森林:
随机森林(RCF)算法是亚马逊用于检测异常的无监督算法。它也通过关联异常分数来工作。低分值表示数据点被视为“正常”。高值表示数据中存在异常。“低”和“高”的定义取决于应用,但通常的做法是,分数超过平均分的三个标准差被视为异常。详细的算法可以在此文中找到。
这个算法的优点在于它可以处理非常高维的数据。它还可以处理实时流数据(内置于AWS Kinesis分析)以及离线数据。
我将在下面的视频中更详细地解释这个概念:
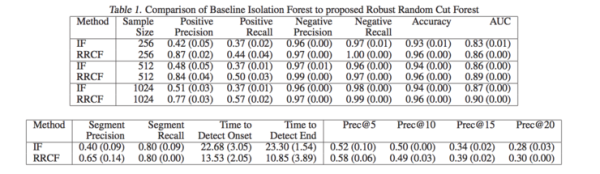
这篇论文中给出了一些与孤立森林比较的性能指标。本文的结果表明,RCF比孤立森林更准确、更快速。
完整的示例代码可以在这里找到:
awslabs/amazon-sagemaker-examplesExample notebooks that show how to apply machine learning and deep learning in Amazon SageMaker …github.com
结论:
我们生活在一个数据以秒为单位变大的世界。如果使用不当,数据的价值会随着时间的推移而减少。在流中在线或离线在数据集中发现异常对于识别业务中的问题或构建一个在问题发生之前就潜在地发现问题的主动解决方案,或者甚至在为ML准备数据集的探索性数据分析(EDA)阶段,都是至关重要的。我希望您能发现本文有用,请告诉我您的想法在下面的评论部分思考。
来自:
https://bigdata.51cto.com/art/202009/625436.htm
猜你喜欢