
5种数据同分布的检测方法!
在数据挖掘比赛中,很重要的一个技巧就是要确定训练集与测试集特征是否同分布,这也是机器学习的一个很重要的假设。但很多时候我们知道这个道理,却很难有方法来保证数据同分布,这篇文章就分享一下我所了解的同分布检验方法。
一、KS检验
KS是一种非参数检验方法,可以在不知道数据具体分布的情况下检验两个数据分布是否一致。当然这样方便的代价就是当检验的数据分布符合特定的分布事,KS检验的灵敏度没有相应的检验来的高。在样本量比较小的时候,KS检验作为非参数检验在分析两组数据之间是否不同时相当常用。
1. 画出数据的累积分段图
2. 对于累积分布图取Log变换
3. 通过两个数据的累积分布图直接最大垂直距离描述两数据的差异
实际操作中并不建议自己手写,可以直接调用Python scipy库中封装好的函数:
from scipy.stats import ks_2samp
ks_2samp(train[col],test[col]).pvalue
二、Overlap Rate
对于连续型变量我们可以使用KS检验来检测数据分布是否一致,对于类别型变量我们可以对其进行编码然后检测,或者选择通过特征重合率来进行检测,在高基数变量中此方法经常被用到。
通过特征重合率检测的思想是检测训练集特征在测试集中出现的比率,举个例子:
训练集特征:[猫,狗,狗,猫,狗,狗,狗,猫]
测试集特征:[猫,猫,鱼,猪,鱼,鱼,猪,猪]
即使该特征在训练集表现很好,但在测试集上的用处并不大,因为重合率仅有1/4,反而会导致过拟合或者模型忽略到其他更有用的特征。
三、KL散度
虽然特征重合率可以筛掉一些不好的特征,但是在下面这种情况下,覆盖率虽然是100%,但是特征的作用并不大:
训练集特征:[猫,猫,鱼,猪,鱼,鱼,猪,猪]
测试集特征:[猫,狗,狗,狗,狗,狗,狗,狗]
该特征在训练集可能有很大的作用,但在测试集无法有效的划分样本,因为在测试集大多是一样的取值。在这种情况下,我第一个想法是在用Overlap Rate筛选过后,再计算测试集的信息熵(在决策树中我们提到过,信息熵更大代表着可以更好的对样本进行划分)。今天发现有个更好的end-to-end的方法,那就是KL散度。


KL 散度是一种衡量两个概率分布的匹配程度的指标,两个分布差异越大,KL散度越大。注意如果要查看测试集特征是否与训练集相同,P代表训练集,Q代表测试集,这个公式对于P和Q并不是对称的。
四、KDE 核密度估计
KDE核密度估计,看起来好像是统计学里面一个高端的非参数估计方法。我简单的理解下哈,大概就是通过一个核函数把一个频率分布直方图搞成平滑的了。具体核函数是啥,问就是不知道,我不是学统计的,自己看看叭。
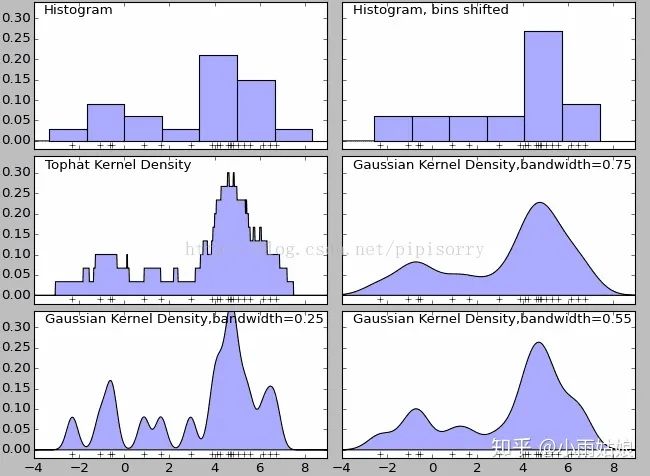
我一般都是这么用的,从seaborn中找到KDE plot这个方法,然后把测试集和训练集的特征画出来,看看图像不像,不像的直接扔了就行/敷衍。
>>> import numpy as np; np.random.seed(10)
>>> import seaborn as sns; sns.set(color_codes=True)
>>> mean, cov = [0, 2], [(1, .5), (.5, 1)]
>>> x, y = np.random.multivariate_normal(mean, cov, size=50).T
>>> ax = sns.kdeplot(x)
五、机器学习模型检测
然后就是这个月我从Kaggle了解的一个惊为天人的方法,听完我就惊了,用机器学习模型检测分布是否一致。
中心思想就是使用特征训练模型来分辨测试集与测试集,若模型效果好的话代表训练集和测试集存在较大差异,否则代表训练集和测试集分布比较相似。
具体做法是构建一个二分类模型,对train-set打上0,测试集打上1,然后shuffle一下进行训练,若分类效果好,代表训练集和测试集区分度很高,那么分布差异就较大。
我感觉它最大的价值是,针对不同的模型检测分布会得到不同的效果,在实践中由于选定了预测模型,它对于某个特定场景的适应效果应该比常规的检测方法好很多。
由此延申出来,我们用训练好的二分类模型对训练集进行预测,然后输出预测概率,根据这个概率为训练集设置权重(概率越接近1代表训练集分布更接近测试集),这样就可以强行过拟合到测试集上!对于非线上测试型的数据挖掘比赛应该会有比较大的提升!
六、参考
为什么要同分布:https://zhuanlan.zhihu.com/p/52530189 KS检验:https://www.cnblogs.com/arkenstone/p/5496761.html Scipy KS检验:https://docs.scipy.org/doc/scipy-0.19.1/reference/generated/scipy.stats.ks_2samp.html 离散变量编码:https://zhuanlan.zhihu.com/p/87203369 特征重合率: https://zhuanlan.zhihu.com/p/82435050 KDE:https://blog.csdn.net/pipisorry/article/details/53635895 KDE Drawer:http://seaborn.pydata.org/generated/seaborn.kdeplot.html Kaggle Adversarial validation: https://www.kaggle.com/kevinbonnes/adversarial-validation