
通过卫星图像预测区域内降雨范围和降雨量

来源:DeepHub IMBA 本文约3000字,建议阅读5分钟
本文介绍了如何通过模型预测区域内降雨范围和降雨量。
介绍
数据收集与分析
wget "https://api.meteomatics.com/2021-07-13T20:15:02Z/sat_ir_108:K/65,-15_35,20:800x600/png"
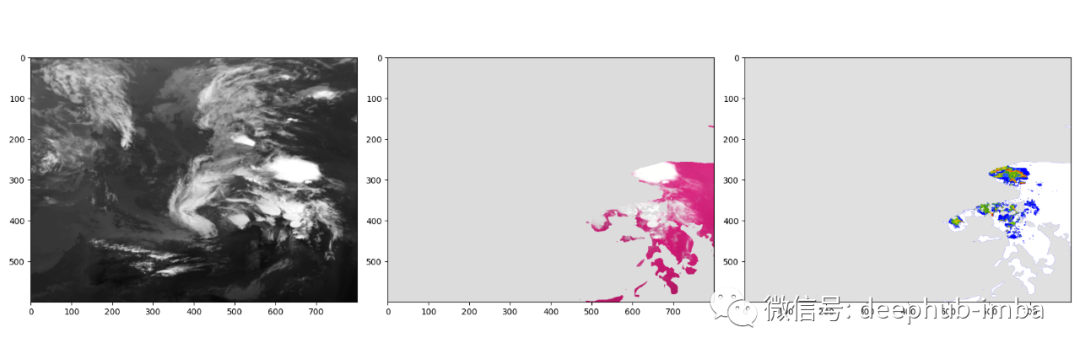
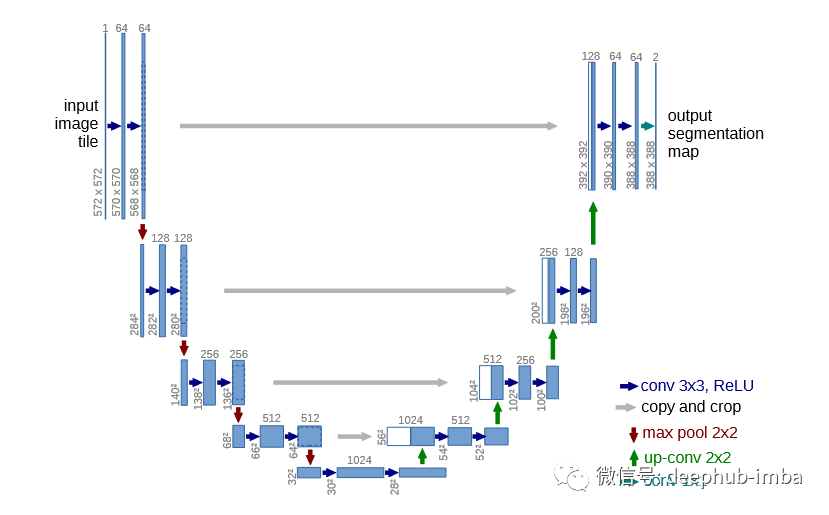
神经网络和语义分割
未标记(如果存在,则掩盖图像的一部分) 0.00mm(无雨) 0.04mm — 0.07mm 0.07mm — 0.15mm 0.15mm — 0.30mm 0.30mm — 0.60mm 0.60mm — 1.20mm 1.20mm — 2.40mm 2.40mm — 4.80mm > 4.80mm
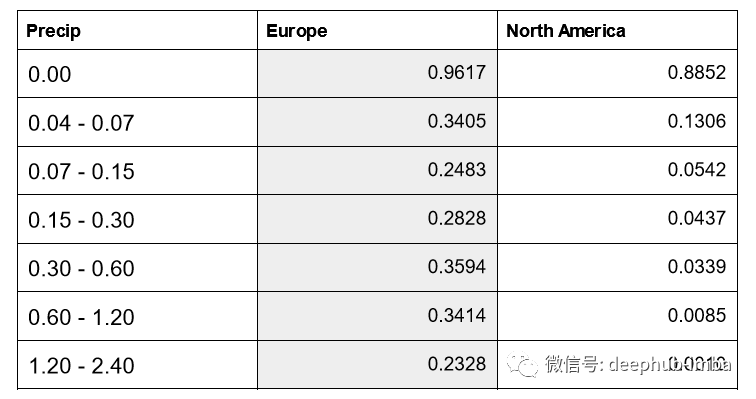
结果展示
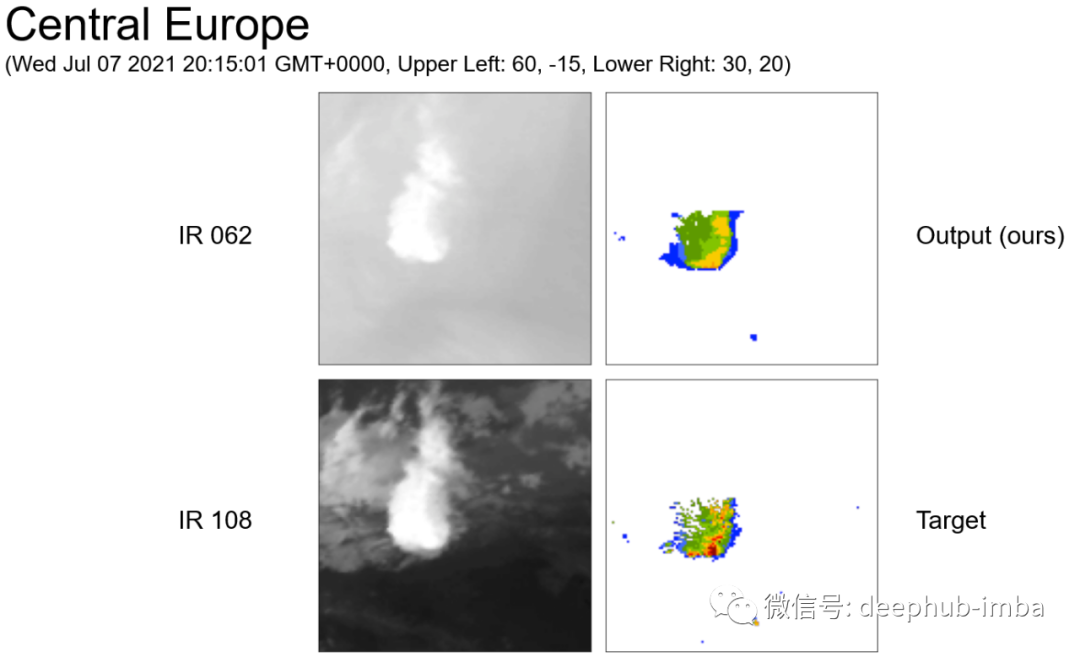
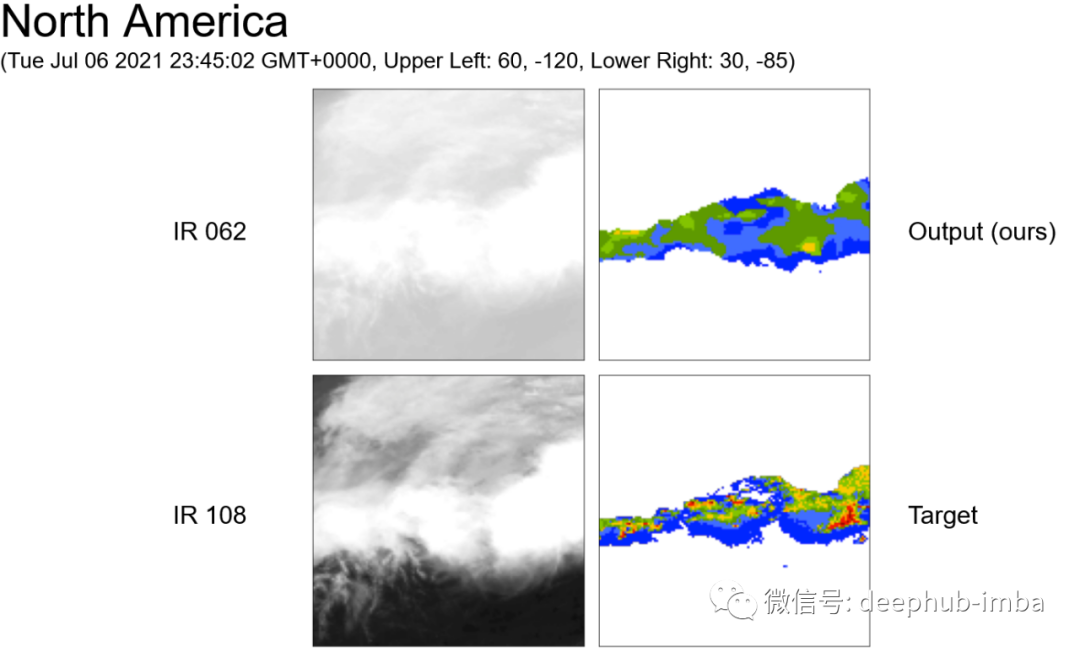

总结
或者去原文看看:
https://towardsdatascience.com/predicting-rain-from-satellite-images-c9fec24c3dd1
编辑:王菁
评论