AI框架可根据图像和触觉数据预测对象的运动
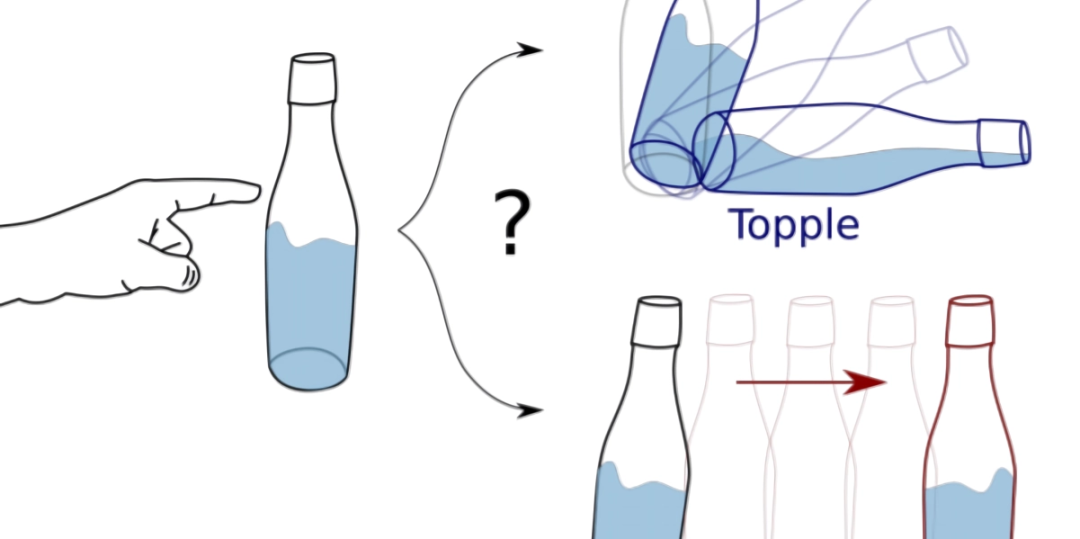


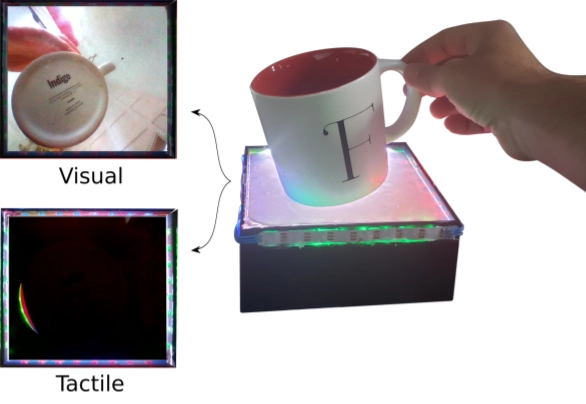
https://venturebeat.com/2021/01/18/researchers-develop-ai-framework-that-predicts-object-motion-from-image-and-tactile-data/
评论
 下载APP
下载APPhttps://venturebeat.com/2021/01/18/researchers-develop-ai-framework-that-predicts-object-motion-from-image-and-tactile-data/