
【机器学习】关于机器学习模型可解释(XAI),再分享一招!
随着时间的推移,学习模型变得越来越复杂,很难直观地分析它们。人们经常听说机器学习模型是"黑匣子",从某种意义上说,它们可以做出很好的预测,但我们无法理解这些预测背后的逻辑。这种说法是正确的,因为大多数数据科学家发现很难从模型中提取见解。然而,我们可以使用一些工具从复杂的机器学习模型中提取见解。
上一篇文章中我已分享了一篇文章:再见"黑匣子模型"!SHAP 可解释 AI (XAI)实用指南来了!该篇文章主要介绍了关于回归问题的模型可解释性。
本文是关于如何使用sklearn.tree.plot_tree ,来获得模型可解释性的方法说明。决策树本身就是一种可解释的机器学习算法,广泛应用于线性和非线性模型的特征重要性。它是一个相对简单的模型,通过可视化树很容易解释。
import numpy as np
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pylab as plt
from sklearn import datasets, ensemble, model_selection
from sklearn.ensemble import RandomForestClassifier
在此示例中,我们将使用来自 sklearn 数据集的乳腺癌示例。这是一个简单的二进制(恶性,良性)分类问题,从乳腺肿块的细针抽吸(FNA)的数字化图像计算特征,它们描述了图像中细胞核的特征。
# import data and split
cancer = datasets.load_breast_cancer()
X_train, X_test, y_train, y_test = model_selection.train_test_split(cancer.data, cancer.target, random_state=0)
拆分数据集进行训练和测试后,使用tree.DecisionTreeClassifier() 建立分类模型。
# model and fit
cls_t = tree.DecisionTreeClassifier()
cls_t.fit(X_train, y_train);
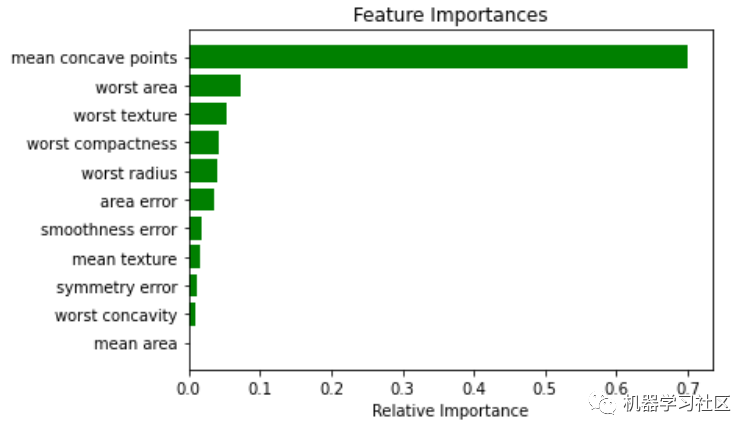
现在,为了对模型有一个基本的印象,我建议可视化特性的重要性。特征重要性的计算方法是通过节点到达该节点的概率加权节点杂质的减少量。节点概率可以通过到达节点的样本数除以样本总数来计算。值越高,特征越重要。最重要的特征将在树中更高。单个特征可以用于树的不同分支,特征重要性则是其在减少杂质方面的总贡献。
importances = cls_t.feature_importances_
indices = np.argsort(importances)
features = cancer.feature_names
plt.title('Feature Importances')
j = 11# top j importance
plt.barh(range(j), importances[indices][len(indices)-j:], color='g', align='center')
plt.yticks(range(j), [features[i] for i in indices[len(indices)-j:]])
plt.xlabel('Relative Importance')
plt.show()
cls_t.feature_importances_
在这种情况下,仅使用前 13 个特征,未使用其他特征,表明它们的重要性是零。
让我们将决策树的前三层进行可视化,max_depth=3。
# visualization
fig = plt.figure(figsize=(16, 8))
vis = tree.plot_tree(cls_t, feature_names = cancer.feature_names, class_names = ['Benign', 'Malignant'], max_depth=3, fontsize=9, proportion=True, filled=True, rounded=True)
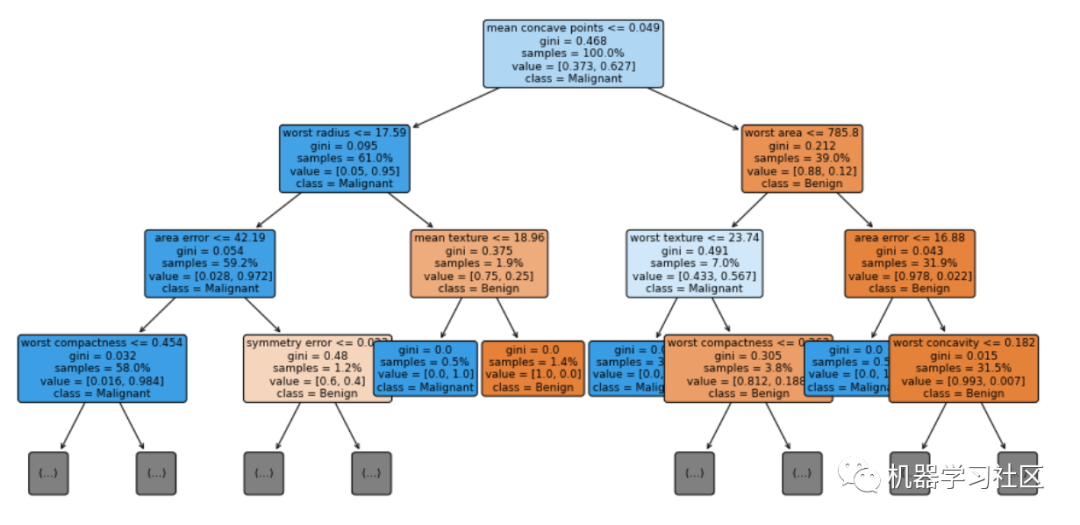
关于模型我们能了解到什么?
首先,我们可以看到每个决策级别使用的特性的名称和条件的拆分值。如果一个样本满足条件,那么它将转到左分支,否则它将转到右分支。
每个节点中的samples行显示当前节点中正在检查的样本数。如果proporty=True,则samples行中的数字以总数据集的%为单位。
每个节点中的值行告诉我们该节点中有多少个样本属于每个类,顺序是当比例=False时,样本的比例=True时。这就是为什么在每个节点中,value中的数字加起来等于value中显示的数字,表示proportion=False,1表示proportion=True。
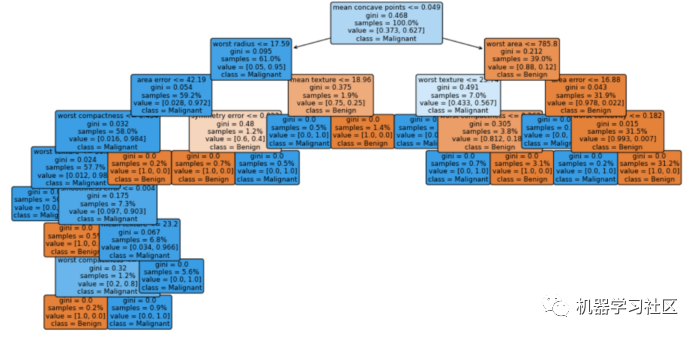
在类行中我们可以看到节点的分类结果。
基尼分数是量化节点纯度的度量,类似于熵。基尼系数大于零意味着该节点中包含的样本属于不同的类。在上图中,叶子的基尼分数为零,这意味着每个叶子中的样本属于一个类。请注意,当纯度较高时,节点/叶子的颜色较深。
决策树代理模型
一种解释“黑匣子”模型全局行为的流行方法是应用全局代理模型。全局代理模型是一种可解释的模型,经过训练以近似黑盒模型的预测。我们可以通过解释代理模型来得出关于黑盒模型的结论。通过使用更多机器学习解决机器学习可解释性问题!
训练代理模型是一种与模型无关的方法,因为它不需要关于黑盒模型内部工作的任何信息,只需要访问数据和预测函数。这个想法是我们采用我们的“黑匣子”模型并使用它创建预测。然后我们根据“黑盒”模型和原始特征产生的预测训练一个透明模型。请注意,我们需要跟踪代理模型与“黑盒”模型的近似程度,但这通常不容易确定。
随机森林分类器是一种常用的模型,用于解决决策树模型往往存在的过拟合问题。结果在测试集上具有更好的准确性,但它是
clf = RandomForestClassifier(random_state=42, n_estimators=50, n_jobs=-1)
clf.fit(X_train, y_train);
使用模型创建预测(在本例中为 RandomForestClassifier)
predictions = clf.predict(X_train)
然后使用预测将数据拟合到决策树分类器。
cls_t = tree.DecisionTreeClassifier()
cls_t.fit(X_train, predictions);
可视化
# visualization
fig = plt.figure(figsize=(16, 8))
vis = tree.plot_tree(cls_t, feature_names = cancer.feature_names, class_names = ['Benign', 'Malignant'], max_depth=3, fontsize=9, proportion=True, filled=True, rounded=True)
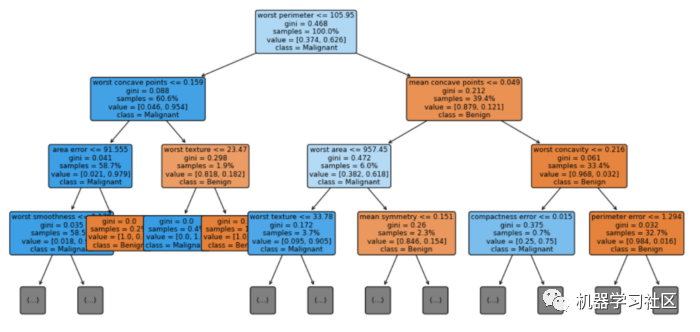 就是这样!即使我们无法轻易理解森林中数百棵树的外观,我们也可以构建一个浅层决策树,并希望了解森林的工作原理。
就是这样!即使我们无法轻易理解森林中数百棵树的外观,我们也可以构建一个浅层决策树,并希望了解森林的工作原理。
最后,测量代理模型复制黑盒模型预测的程度。衡量代理复制黑盒模型的好坏的一种方法是R平方度量。
cls_t.score(X_train, predictions)
提示
如果你使用 pycharm 创建模型,则可以使用 pickle 将其导出到jupyter notebook。
模型输出:
import pickle
# dump information to that file
with open('model','wb') as outfile:
pickle.dump(cls_t, outfile)
模型导入:
import pickle
# load information from that file
with open('model','rb') as inputfile:
modell = pickle.load(inputfile)
概括
解释“黑匣子”机器学习模型对于它们成功适用于许多现实世界问题非常重要。sklearn.tree.plot_tree 是一个可视化工具,可以帮助我们理解模型。或者换句话说,机器(模型)从这些特征中学到了什么?它符合我们的期望吗?我们能否通过使用有关问题的领域知识添加更复杂的特征来帮助机器学习?使用决策树可视化可以帮助我们直观地评估模型的正确性,甚至可能对其进行改进。
往期精彩回顾 本站qq群851320808,加入微信群请扫码: