
Python机器学习-线性模型


from sklearn import linear_model
导入linear_model 模块后,在程序中就可以使用相关函数实现线性回归分析。1、最小二乘法回归
线性回归是数据挖掘中的基础算法之一,线性回归的思想其实就是解一组方程,得到回归系数。不过在出现误差项之后,方程的解法就存在了改变,一般使用最小二乘法进行计算,所谓“二乘”就是平方的意思,最小二乘法也称为最小平方和,其目的是通过最小化误差的平方和,使得预测值与真值无限接近。linear_model 模块中的LinearRegression 函数用于实现最小二乘法回归。LinearRegression 函数拟合一个带有回归系数的线性模型,使得真实数据和预测数据(估计值)之间的残差平方和最小,与真实数据无限接近。
LinearRegression 函数的语法如下:linear_model.LinearRegression(fit_intercept=True,normalize=False,copy_X=True,n_jobs=None)
参数说明:
● fit_intercept:布尔型值,是否需要计算截距,默认值为True。
● normalize:布尔型值,是否需要标准化,默认值为False,和参数fit_intercept有关。当fit_intercept参数值为False 时,将忽略该参数;当fit_intercept 参数值为True 时,则回归前,对回归量X 进行归一化处理,取均值相减,再除以L2 范数(L2 范数是指向量各元素的平方和,然后开方)。
● copy_X :布尔型值,选择是否复制X 数据,默认值True,如果为False,则覆盖X 数据。
● n_jobs:整型,代表CPU 工作效率的核数,默认值1,-1 表示跟CPU 的核数一致。
主要属性:
● coef_:数组或形状,表示线性回归分析的回归系数。
● intercept_:数组,表示截距。
主要方法:
● fit(X,y,sample_weight=None):拟合线性模型。
● predict(X):使用线性模型返回预测数据。
● score(X,y,sample_weight=None):返回预测的确定系数R^2。LinearRegression 函数调用fit 方法来拟合数组X、y,并且将线性模型的回归系数存储在其成员变量的coef_ 属性中。
快速示例01 智能预测房价
实现智能预测房价,假设某地的房屋面积和价格关系如图2 所示,下面使用LinearRegression 函数预测面积为170 平方米的房屋的单价。 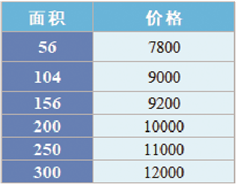
图2 房屋价格表
程序代码如下:
from sklearn import linear_model
import numpy as np
x=np.array([[1,56],[2,104],[3,156],[4,200],[5,250],[6,300]])
y=np.array([7800,9000,9200,10000,11000,12000])
clf = linear_model.LinearRegression()
clf.fit (x,y) #拟合线性模型
k=clf.coef_ #回归系数
b=clf.intercept_ #截距
x0=np.array([[7,170]])
#通过给定的x0预测y0,y0=截距+X值*回归系数
y0=clf.predict(x0) #预测值
print('回归系数:',k)
print('截距:',b)
print('预测值:',y0)
运行程序,输出结果为:
回归系数: [1853.37423313 -21.7791411 ]
截距:7215.950920245397
预测值: [16487.11656442]
2、岭回归
岭回归是在最小二乘法回归的基础上,加入了对表示回归系数的L2 范数约束。岭回归是缩减法的一种,相当于对回归系数的大小施加了限制。岭回归主要使用linear_model 模块的Ridge 函数实现,语法如下: linear_model.Ridge(alpha=1.0,fit_intercept=True,normalize=False,copy_X=True,max_iter=None,tol=0.001,solver='auto',random_state=None)参数说明:
● alpha:权重。
● fit_intercept:布尔型值,是否需要计算截距,默认值为True。
● normalize:输入的样本特征归一化,默认值为False。
● copy_X :复制或者重写。
● max_iter:最大迭代次数。
● tol:浮点型,控制求解的精度。
● solver:求解器,其值包括auto、svd、cholesky、sparse_cg和lsqr,默认值为auto。
主要属性:
● coef_:数组或形状,表示线性回归分析的回归系数。
主要方法:
● fit(X,y):拟合线性模型。
● predict(X):使用线性模型返回预测数据。
● Ridge 函数使用fit 方法将线性模型的回归系数存储在其成员变量的coef_ 属性中。
快速示例02 使用岭回归函数实现智能预测房价
使用岭回归函数Ridge 实现智能预测房价,程序代码如下:
from sklearn.linear_model import Ridge
import numpy as np
x=np.array([[1,56],[2,104],[3,156],[4,200],[5,250],[6,300]])
y=np.array([7800,9000,9200,10000,11000,12000])
clf = Ridge(alpha=1.0)
clf.fit(x, y)
k=clf.coef_ #回归系数
b=clf.intercept_ #截距
x0=np.array([[7,170]])
#通过给定的x0预测y0,y0=截距+X值*斜率
y0=clf.predict(x0) #预测值
print('回归系数:',k)
print('截距:',b)
print('预测值:',y0)
运行程序,输出结果为:
回归系数: [10.00932795 16.11613094]
截距:6935.001421210872
预测值: [9744.80897725]
