
Tokens-to-token ViT: 对token做编码的纯transformer ViT,T2T算引入了CNN了吗?
【GaintPandaCV导语】
T2T-ViT是纯transformer的形式,先对原始数据做了token编码后,再堆叠Deep-narrow网络结构的transformer模块,实际上T2T也引入了CNN。
引言
一句话概括:也是纯transformer的形式,先对原始数据做了token编码后,再堆叠Deep-narrow网络结构的transformer模块。对token编码笔者认为本质上是做了局部特征提取也就是CNN擅长做的事情。
原论文作者认为ViT效果不及CNN的原因:
1、直接将图像分patch后生成token的方式没法建模局部结构特征(local structure),比如相邻位置的线,边缘;
2、在限定计算量和限定训练数据数量的条件下,ViT冗余的注意力骨架网络设计导致提取不到丰富的特征。
所以针对这俩点就提出两个解决方法:
1、找一种高效生成token的方法,即 Tokens-to-Token (T2T)
2、设计一个新的纯transformer的网络,即deep-narrow,并对比了目前的流行的CNN网络。
当然对比完后是作者提出的Deep-narrow效果最好。原文的对比实验值得去借鉴(抄)。
1). 密稠连接,Dense Connection,类比ResNet和DenseNet
2).Deep-narrow 对比shallow-Wide,类比Wide-ResNet
3).通道注意力,类比SE-ResNet
4).在多头注意力层加入更多头,类比ResNeXt
5).Ghost操作,即减少conv的输出通道后再通过DWConv和skip connect将这俩concat起来,类比GhostNet
实验的结果:给出来了炼丹配方了,这一点还是很良心的,根据现有的CNN的模型架构特征改造纯transformer
Deep-narrow能提高VIT的特征丰富性,模型大小和MACs降低,整体效果也提升了;通道注意力对ViT也有提升,但Deep-narrow结构更加高效;密稠连接会影响性能;
笔者认为最重要的token的生成,即可Tokens-to-token模块。
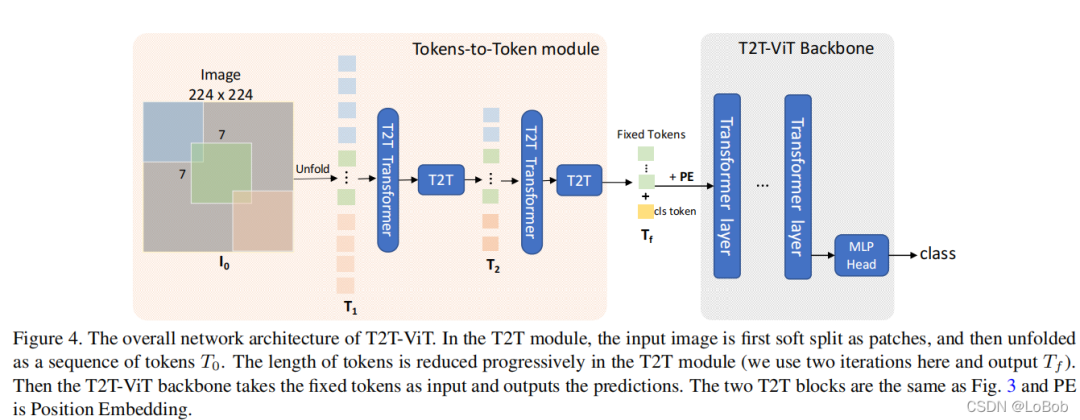
直接看图来分析分析,是怎么做T2T的,看上面Firgure 4橘黄色部分。
步骤1:有重叠地取图像的区域,实际上这个区域就是做卷积的窗口,这个窗口大小是7×7,stride为4,padding为2,然后调用nn.Unfold函数将[7,7]摊平成[49](也就是把一张饼变成一长条),其实也就是img2col,这一步命名为"soft split";
步骤2:对摊平的长条做变换,这里使用了transformer,可以用performer来降低transformer的计算复杂度,这一步命名为"re-structurization/reconstruction";
步骤3:将步骤2出来的结果(B,H×W,C)reshape成一个4维度(B,C,H,W)矩阵;
步骤4:跟步骤1一样,取一个窗口的数值,即nn.Unfold,这次窗口是3×3,stride为2,padding为1;
步骤5:跟步骤2一样,对取到的长条做变换,即可transformer或者performer;
步骤6:跟步骤3一样,reshape成一个4维度矩阵;
步骤7:跟步骤4一样,参数也一样,取出长条;
步骤8:将步骤7出来的长条做一次全连接生成固定的token数量。
整个Tokens-to-token就完成了。
代码及分析
看看代码:
class T2T_module(nn.Module):
"""
Tokens-to-Token encoding module
"""
def __init__(self, img_size=224, tokens_type='performer', in_chans=3, embed_dim=768, token_dim=64):
super().__init__()
if tokens_type == 'transformer':
print('adopt transformer encoder for tokens-to-token')
self.soft_split0 = nn.Unfold(kernel_size=(7, 7), stride=(4, 4), padding=(2, 2))
self.soft_split1 = nn.Unfold(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.soft_split2 = nn.Unfold(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.attention1 = Token_transformer(dim=in_chans * 7 * 7, in_dim=token_dim, num_heads=1, mlp_ratio=1.0)
self.attention2 = Token_transformer(dim=token_dim * 3 * 3, in_dim=token_dim, num_heads=1, mlp_ratio=1.0)
self.project = nn.Linear(token_dim * 3 * 3, embed_dim)
elif tokens_type == 'performer':
print('adopt performer encoder for tokens-to-token')
self.soft_split0 = nn.Unfold(kernel_size=(7, 7), stride=(4, 4), padding=(2, 2))
self.soft_split1 = nn.Unfold(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.soft_split2 = nn.Unfold(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
#self.attention1 = Token_performer(dim=token_dim, in_dim=in_chans*7*7, kernel_ratio=0.5)
#self.attention2 = Token_performer(dim=token_dim, in_dim=token_dim*3*3, kernel_ratio=0.5)
self.attention1 = Token_performer(dim=in_chans*7*7, in_dim=token_dim, kernel_ratio=0.5)
self.attention2 = Token_performer(dim=token_dim*3*3, in_dim=token_dim, kernel_ratio=0.5)
self.project = nn.Linear(token_dim * 3 * 3, embed_dim)
elif tokens_type == 'convolution': # just for comparison with conolution, not our model
# for this tokens type, you need change forward as three convolution operation
print('adopt convolution layers for tokens-to-token')
self.soft_split0 = nn.Conv2d(3, token_dim, kernel_size=(7, 7), stride=(4, 4), padding=(2, 2)) # the 1st convolution
self.soft_split1 = nn.Conv2d(token_dim, token_dim, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)) # the 2nd convolution
self.project = nn.Conv2d(token_dim, embed_dim, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)) # the 3rd convolution
self.num_patches = (img_size // (4 * 2 * 2)) * (img_size // (4 * 2 * 2)) # there are 3 sfot split, stride are 4,2,2 seperately
def forward(self, x):
# step0: soft split
x = self.soft_split0(x).transpose(1, 2)
# iteration1: re-structurization/reconstruction
x = self.attention1(x)
B, new_HW, C = x.shape
x = x.transpose(1,2).reshape(B, C, int(np.sqrt(new_HW)), int(np.sqrt(new_HW)))
# iteration1: soft split
x = self.soft_split1(x).transpose(1, 2)
# iteration2: re-structurization/reconstruction
x = self.attention2(x)
B, new_HW, C = x.shape
x = x.transpose(1, 2).reshape(B, C, int(np.sqrt(new_HW)), int(np.sqrt(new_HW)))
# iteration2: soft split
x = self.soft_split2(x).transpose(1, 2)
# final tokens
x = self.project(x)
return x
接下来看怎么对生成的token做transformer,看上面Firgure 4浅灰色部分,也就是堆叠transformer layer,最后加一个MLP做分类。transformer layer就是众所周知的了。
然后就是怎么做堆叠呢?Deep-narrow的方式,也就是层数变多,维度变小,“高高瘦瘦”。这部分代码也众所周知了,就不贴代码了。而且个人觉得,虽然作者对Deep-narrow的对比实验非常丰富,但我个人主观认为,网络部分是为了结合T2T,你用其他网络堆叠也是可以的,是一个调参过程。
这里我有个疑问,所以T2T这一部分跟CNN有什么区别呢?看看Figure 3。
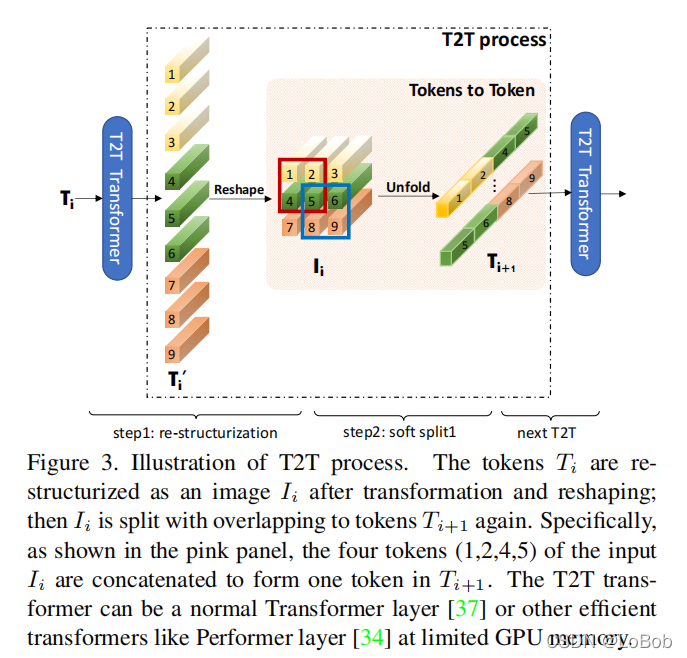
我们知道CNN = unfold + matmul + fold。那么T2T模块第一步做了unfold,然后对取出来的窗口做了transformer的非线性变化,这一步我们是不是可以理解为对窗口里面的像素点做了matmul呢?这里的matmul可能更像是做attention。然后reshape回去相当于做了fold操作。笔者认为,T2T模块,本质上就是做了局部特征提取,也就CNN擅长做的事情。
个人主观评价
T2T是一篇好文,应该是第一篇提出要对token进行处理的ViT工作,本意是为了提取更加高效的token,这样可以减少token的数量,那么堆叠transformer模块也能降低参数量和计算量。
但本质上还是隐式引入了卷积,即有unfold + matmul + fold = CNN。对比与后来者ViTAE,T2T的解决方法其实更加简洁。