VIT 的复仇 !!
作者:Adam Zewe 机器之心编译
大家好,我是DASOU。
之前VIT横空出世,我写过一个解读文章:VIT:如何将Transformer更好的应用到CV领域
最近发现一个新出的论文,提出三种数据增强方法:灰度、过度曝光、高斯模糊,以及一种简单的随机修剪方法 (SRC)。实验结果表明,这些新方法在效果上大大优于 ViT 此前的全监督训练方法。
Transformer 模型 [55] 及其衍生模型在 NLP 任务中取得巨大成功后,在计算机视觉任务中也越来越受欢迎。这一系列的模型越来越多地用于图像分类 [13]、检测与分割 [3]、视频分析等领域。尤其是 Dosovistky 等人 [13] 提出的视觉 Transformer(ViT)成为了卷积结构的合理替代模型。这些现象说明 Transformers 模型已经可以作为一种通用架构,来通过注意力机制学习卷积以及更大区间的操作 [5,8]。相比之下,卷积网络 [20,27,29,41] 本就具备了平移不变性,不用再通过训练来获取。因此,包含卷积的混合体系结构比普通 Transformers 收敛得更快也就不足为奇了 [18]。
因为 Transformer 仅将多个 patch 中相同位置的像素合并,所以 Transformer 必须了解图像的结构,同时优化模型,以便它处理用来解决给定任务目标的输入。这些任务可以是在监督情况下产生标签,或者在自监督方法下的其他代理任务。然而,尽管 Transformer 取得了巨大的成功,但在计算机视觉方面研究如何有效训练视觉 Transformer 的工作却很少,特别是在像 ImageNet1k 这样的中型数据集上。从 Dosovistky 等人的工作 [13] 开始,训练步骤大多是使用 Touvron 等人 [48] 和施泰纳等人 [42] 提出的方法的变体。相比之下,有许多工作通过引入池化、更有效的注意力机制或者重新结合卷积和金字塔结构的混合架构提出了替代架构。这些新设计虽然对某些任务特别有效,但不太通用。所以研究者们会困惑,性能的提高到底是由于特定的架构设计,还是因为它按照 ViT 卷积所提出的方式改进了优化过程。
最近,受时下流行的基于 BerT 预训练启发的自监督方法为计算机视觉中的 BerT 时代带来了希望。从 Transformer 架构本身出发,NLP 和 CV 领域之间存在一些相似之处。然而,并非在所有方面都是相同的:处理的模态具有不同的性质(连续与离散)。CV 提供像 ImageNet [40] 这样的大型带有注释的数据库,并且在 ImageNet 上进行全监督的预训练对于处理不同的下游任务(例如迁移学习 [37] 或语义分割)是有效的。
如果没有对 ImageNet 上全监督方法的进一步研究,很难断定像 BeiT [2] 这样的自监督方法的性能是否该归因于网络的训练过程,例如数据增强、正则化、优化,或能够学习更一般的隐式表示的底层机制。在本文中,研究者们没有强行回答这个难题,而是通过更新常规 ViT 架构的训练程序来探讨这个问题。

论文地址:https://arxiv.org/pdf/2204.07118.pdf
研究者们希望这个工作能有助于更好地理解如何充分利用 Transformer 的潜力以及说明类似 BerT 的预训练的重要性。他们的工作建立在最新的全监督和自监督方法的基础上,并对数据增强提出了新的见解。作者为 ImageNet-1k 和 ImageNet-21k 上的 ViT 提出了新的训练方法。主要构成如下:
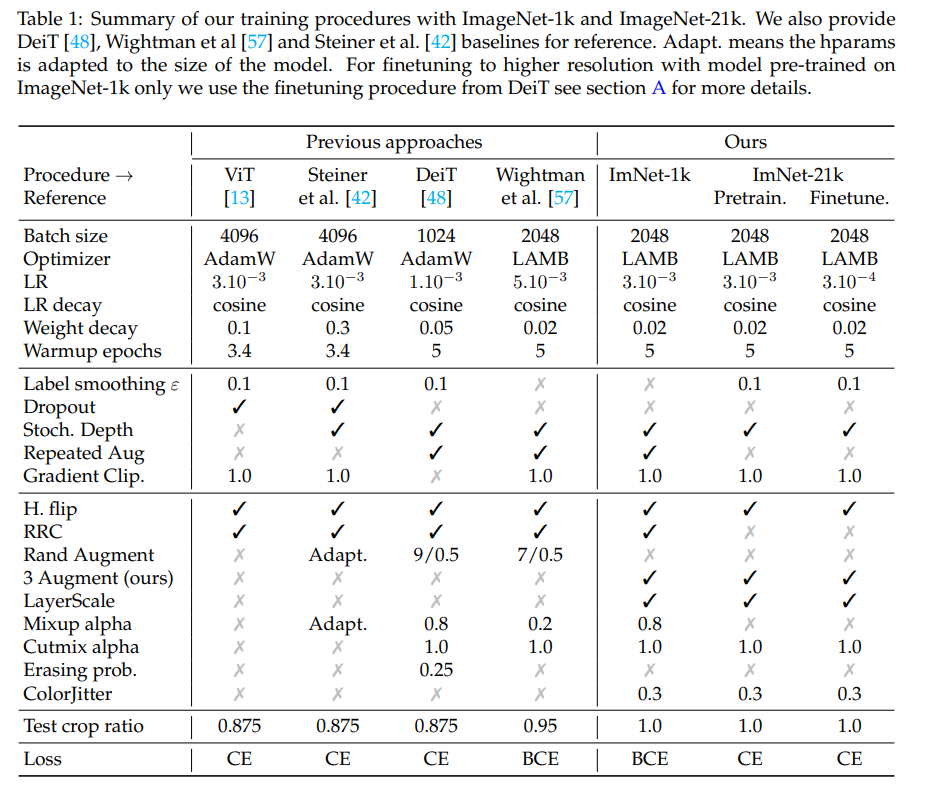
作者以 Wightman 等人的工作 [57] 为基础,同样使用 ResNet50 。特别之处在于,仅对 Imagenet1k 的训练过程采用二元交叉熵损失,这一步可以通过引入一些显着改善大型 ViT [51] 训练的方法,即 stochastic depth [24] 和 LayerScale [51],来实现。
3-Augment:这是一种简单的数据增强方式,灵感来自于自监督学习。令人惊讶的是,在使用 ViT 时,作者观察到这种方法比用于训练 ViT 的常用自动 / 学习数据增强(如 RandAugment [6])效果更好。
在像 ImageNet-21k 这样的更大数据集上进行预训练时,简单随机裁剪的方式比调整大小后再随机裁剪的方式更有效。
训练时降低分辨率。这种选择减少了训练和测试过程的差异 [53],而且还没有被 ViT 使用。作者观察到这样做还能通过防止过拟合,来使得对最大的模型产生正则化效果。例如,目标分辨率是 224 × 224 ,在分辨率 126 × 126(81 个 token)下预训练的 ViT-H 在 ImageNet-1k 上的性能比在分辨率 224 × 224(256 个 token)下预训练时更好。并且在预训练时的要求也较低,因为 token 数量减少了 70%。从这个角度来看,这样做提供了与掩码自编码器 [19] 类似的缩放属性。
这种 “新” 训练策略不会因最大模型而饱和,这比 Touvron 等人的 Data-Efficient Image Transformer (DeiT) [48] 又多迈出了一步。至此,研究者们在图像分类和分割方面都获得了具有竞争力的性能,即使是与最近流行的架构(如 SwinTransformers [31] 或现代卷积网络架构(如 ConvNext [32])相比也是如此。下面阐述一些作者认为有趣的结果。
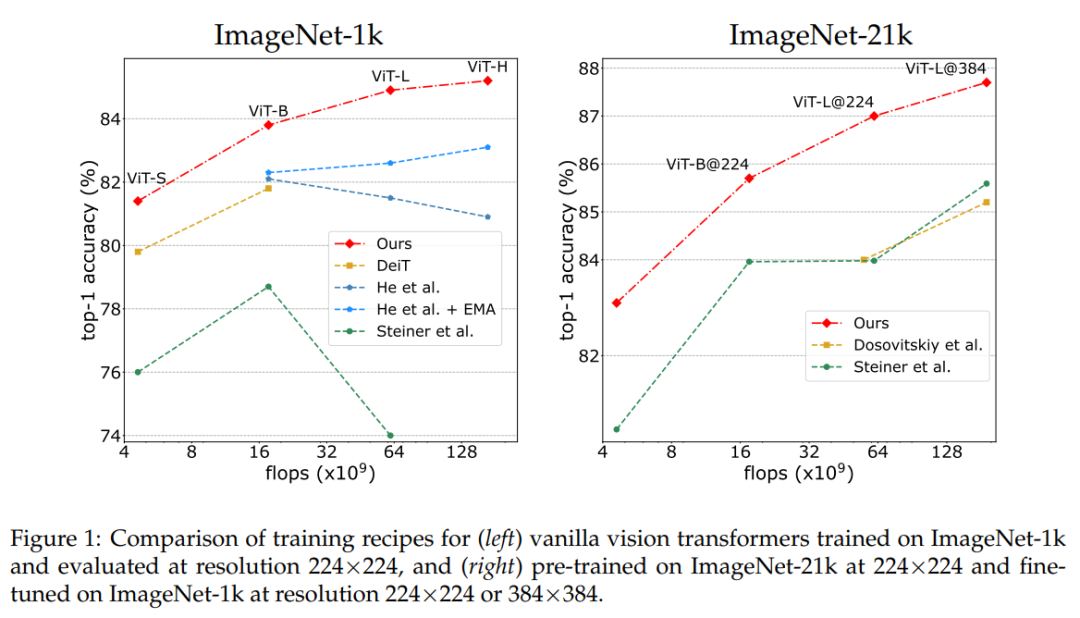
即使在中等规模的数据集上,研究者也会利用具有更多能力的模型。例如,仅在 ImageNet1k 上训练 ViT-H 时, top-1 准确率达到 85.2%,这比文献中报道的分辨率为 224×224 的监督训练过程的最佳 ViT-H 提高了 +5.1%。
ImageNet-1k 训练程序允许训练十亿参数的 ViT-H(52 层),无需任何超参数适应,只需使用与 ViT-H 相同的随机深度下降率。在 224×224 时达到 84.9%,即比在相同设置下训练的相应 ViT-H 高 +0.2%。
在不牺牲性能的情况下,将所需的 GPU 数量和 ViT-H 的训练时间都能减少一半 以上,从而可以在不减少资源的情况下有效地训练此类模型。这要归功于研究者以较低分辨率进行的预训练,从而减少了峰值记忆。
对于 ViT-B 和 Vit-L 模型,作者提出的监督训练方法与具有默认设置的类似 BerT 的自监督方法 [2, 19] 相当,并且在使用相同级别的注释和更少的 epoch 时,两者都适用于图像分类和语义分割任务。
通过这种改进的训练过程,vanilla ViT 缩小了与最近最先进架构的差距,同时通常能提供更好的计算 / 性能权衡。作者提出的模型在附加测试集 ImageNet-V2 [39] 上也相对更好,这表明他们训练的模型比先前的大多数工作能更好地泛化到另一个验证集上。
对迁移学习分类任务中使用的裁剪比率的影响进行消融实验。研究者观察到裁剪结果对性能有显着影响,但最佳值很大程度上取决于目标数据集 / 任务。
Vision Transformers 重温训练和预训练
在本节中,研究者介绍了视觉 Transformers 的训练过程,并将其与现有方法进行比较。他们在表 1 中详细说明了不同的成分。基于 Wightman 等人 [57] 和 Touvron 等人 [48] 的工作,作者介绍了几个对最终模型精度有重大影响的改动。
数据增强
自从 AlexNet 出现以来,用于训练神经网络的数据增强流程有几次重大的修改。有趣的是,相同的数据增强,如 RandAugment [6],被广泛用于 ViT,而他们的策略最初是为了卷积网络学习而产生的。鉴于这些架构中的架构先验和偏差是完全不同的,增强策略可能无法适应,并且考虑到选择中涉及的大量选择,可能会过拟合。因此,研究者重新审视了这个先验步骤。
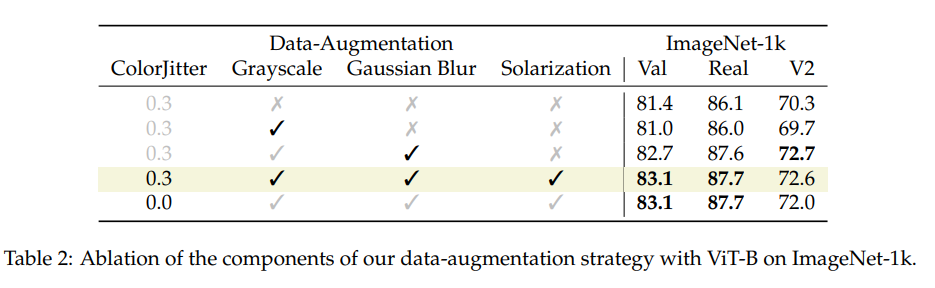
3-Augment:作者提出了一个简单的数据增强,灵感来自监督学习 (SSL) 中使用的内容。作者提出应该考虑以下三种变形:
灰度:有利于颜色不变性并更加关注形状。
过度曝光:会在颜色上添加强烈的噪点,以更加适应颜色强度的变化,从而更加关注形状。
高斯模糊:为了稍微改变图像中的细节。
对于每张图像,他们以均值概率来选择其中一个数据增强。除了这 3 个增强选项之外,还包括常见的颜色抖动和水平翻转。图 2 说明了 3-Augment 方法中使用的不同增强。

在表 2 中,他们提供了对不同数据增强组件的消融实验结果。
裁剪
GoogleNet [43] 中介绍了 Random Resized Crop (RRC)。它是一种限制模型过度拟合的正则化,同时有利于模型所做的决策对于某一类转换是不变的。这种数据增强在 Imagenet1k 上被认为很重要,能防止过度拟合,这种情况恰好在现代大型模型中较为常见。
然而,这种裁剪策略在训练图像和测试图像之间引入了一些长宽比和物体的明显尺寸方面的差异 [53]。由于 ImageNet-21k 包含更多的图像,不太容易过度拟合。因此,研究者质疑强 RRC 正则化的优势是否能够弥补在更大数据集上训练时的缺点。
简单随机裁剪 (SRC) 是一种更简单的裁剪提取方法。它类似于 AlexNet [27] 中提出的原始裁剪选择:调整图像的大小,使最小的边与训练分辨率相匹配。然后在所有边应用一个 4 像素的反射填充,最后应用一个沿图像 x 轴随机选择训练图形大小的正方形裁剪机制
图 3 显示 RRC 和 SRC 采样的裁剪框。RRC 提供了很多不同大小和形状的裁剪框。相比之下,SRC 覆盖了整个图像的更多部分并保留了纵横比,但提供的形状多样性较少:裁剪框显着重叠。因此,在 ImageNet1k 上进行训练时,使用常用的 RRC 性能更好。举个例子来说,如果不使用 RRC,ViT-S 上的 top-1 准确率会降低 0.9%。

然而,在 ImageNet-21k(比 ImageNet-1k 大 10 倍)中,过拟合的风险较小,并且增加 RRC 提供的正则化和多样性并不重要。在这种情况下,SRC 具有了减少外观尺寸和纵横比差异的优势。更重要的是,它使图像的实际标签与裁剪后的标签相匹配的可能性更高:RRC 在裁剪方面相对激进,在许多情况下,标记的对象甚至不存在于作物中,如图 4 所示,其中一些裁剪不包含标记的对象。例如,对于 RRC,左侧示例中的裁剪图片没有斑马,或者中间示例中的三个裁剪图片中没有火车。SRC 不太可能发生这种情况,因为 SRC 覆盖了图像像素的大部分。

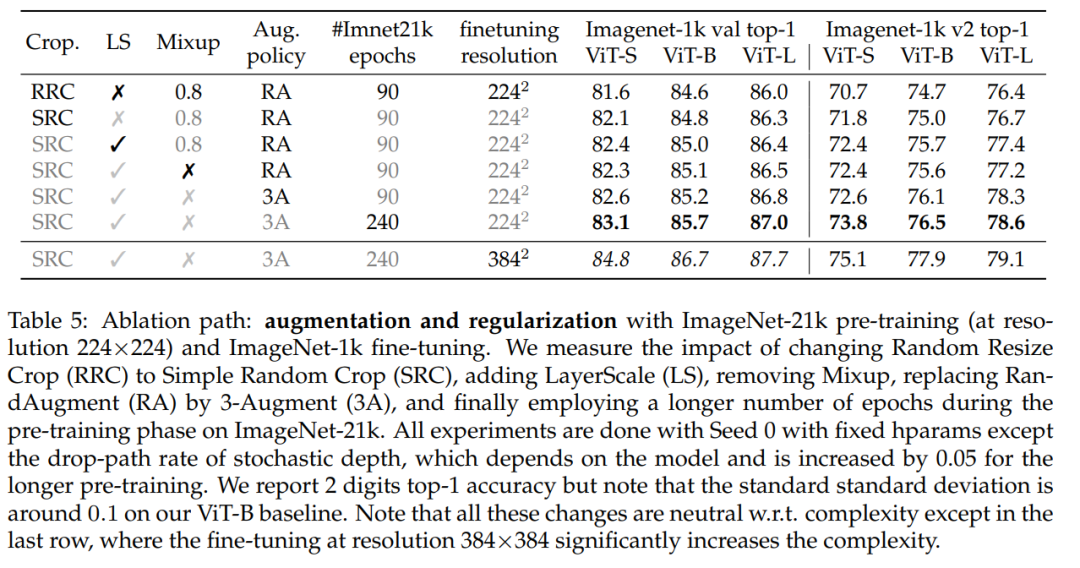
在表 5 中,研究者提供了 ImageNet-21k 上随机调整裁剪大小的消融实验结果,可以看到这些裁剪方式能转化为性能方面的显着提升。
实验结果
研究者对图像分类(在 ImageNet-21k 上进行和不进行预训练的 ImageNet-1k)、迁移学习和语义分割的评估表明,他们的程序大大优于以前针对 ViT 的全监督训练方案。该研究还表明,经过监督训练的 ViT 的性能与最近的架构性能相当。这些结果可以作为最近在 ViT 上使用的自监督方法的更好基准模型。