
ICCV2021 | Tokens-to-Token ViT:在ImageNet上从零训练Vision Transformer
前言 本文介绍一种新的tokens-to-token Vision Transformer(T2T-ViT),T2T-ViT将原始ViT的参数数量和MAC减少了一半,同时在ImageNet上从头开始训练时实现了3.0%以上的改进。通过直接在ImageNet上进行训练,它的性能也优于ResNet,达到了与MobileNet相当的性能。

论文:Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
Background
Vision Transformer(ViT)是第一个可以直接应用于图像分类的全Transformer模型。具体地说,ViT将每个图像分割成固定长度的14×14或16×16块(也称为tokens);然后ViT应用Transformer层对这些tokens之间的全局关系进行建模以进行分类。
尽管ViT证明了全Transformer架构在视觉任务中很有前途,但在中型数据集(例如ImageNet)上从头开始训练时,其性能仍逊于类似大小的CNN对等架构(例如ResNets)。
论文假设,这种性能差距源于ViT的两个主要局限性:
1)通过硬分裂对输入图像进行简单的tokens化,使得ViT无法对图像的边缘和线条等局部结构进行建模,因此它需要比CNN多得多的训练样本(如JFT-300M用于预训练)才能获得类似的性能;
2)ViT的注意力骨干没有很好地像用于视觉任务的CNN那样的设计,如ViT具有冗余性和特征丰富度有限的缺点,导致模型训练困难。
为了验证论文的假设,论文进行了一项初步研究,通过图2中的可视化来调查ViTL/16和ResNet5的获知特征的差异。论文观察ResNet的功能,捕捉所需的局部结构(边、线、纹理等)。从底层(Cv1)逐渐向中间层(Cv25)递增。
然而,ViT的特点却截然不同:结构信息建模较差,而全局关系(如整条狗)被所有的注意块捕获。这些观察结果表明,当直接将图像分割成固定长度的tokens时,原始 ViT忽略了局部结构。此外,论文发现ViT中的许多通道都是零值(在图2中以红色突出显示),这意味着ViT的主干不如ResNet高效,并且在训练样本不足的情况下提供有限的特征丰富度。

图2.在ImageNet上训练的ResNet50、ViT-L/16和论文提出的T2T-VIT-24的功能可视化。绿色框突出显示学习的低级结构特征,如边和线;红色框突出显示值为零或过大的无效要素地图。注意:这里为ViT和T2T-ViT可视化的特征图不是attention图,而是从tokens重塑的图像特征。
创新思路
论文决意设计一种新的full-Transformer视觉模型来克服上述限制。
1)与ViT中使用的朴素tokens化不同,论文提出了一种渐进式tokens化模块,将相邻tokens聚合为一个tokens(称为tokens-to-token模块),该模块可以对周围tokens的局部结构信息进行建模,并迭代地减少tokens的长度。具体地说,在每个tokens-to-token(T2T)步骤中,transformer层输出的tokens被重构为图像(restructurization),然后图像被分割成重叠(soft split)的tokens,最后周围的tokens通过flatten分割的patches被聚集在一起。因此,来自周围patches的局部结构被嵌入要输入到下一transformer层的tokens中。通过迭代进行T2T,将局部结构聚合成tokens,并通过聚合过程减少tokens的长度。
2)为了寻找高效的Vision Transformer主干,论文借鉴了CNN的一些架构设计来构建Transformer层,以提高功能的丰富性,论文发现ViT中通道较少但层数较多的“深度窄”架构设计在同等型号和MAC(Multi-Adds)的情况下性能要好得多。具体地说,论文研究了宽ResNet(浅宽VS深窄结构)、DenseNet(密集连接)、ResneXt结构、Ghost操作和通道注意。论文发现其中,深窄结构对于ViT是最有效和最有效的,在几乎不降低性能的情况下显著地减少了参数数目和MACs。这也表明CNNs的体系结构工程可以为Vision Transformer的骨干设计提供帮助。
基于T2T模块和深度窄骨干网架构,论文开发了tokens-to-token Vision Transformer(T2T-ViT),它在ImageNet上从头开始训练时显著提高了性能,而且比普通ViT更轻便。
Methods
T2T-ViT由两个主要部分组成(图4):
1)一个层次化的“Tokens-to-Token模块”(T2T模块),用于对图像的局部结构信息进行建模,并逐步减少tokens的长度;
2)一个有效的“T2T-ViT骨干”,用于从T2T模块中提取对tokens的全局关注关系。
在研究了几种基于CNN的体系结构设计后,对主干采用深窄结构,以减少冗余度,提高特征丰富性。

图4.T2T-ViT的整体网络架构。在T2T模块中,首先将输入图像soft split为patches,然后将其展开为token T0序列。在T2T模块中,token的长度逐渐减小(在这里使用两次迭代和输出Tf)。然后,T2T-VIT主干将固定token作为输入并输出预测。两个T2T块与图3相同,PE为位置嵌入。
Tokens-to-Token
Tokens-to-Token(T2T)模块旨在克服ViT中简单tokens化的限制。它将图像逐步结构化为表征,并对局部结构信息进行建模,这样可以迭代地减少表征的长度。每个T2T流程有两个步骤:重组和Soft Split(SS)(图3)。
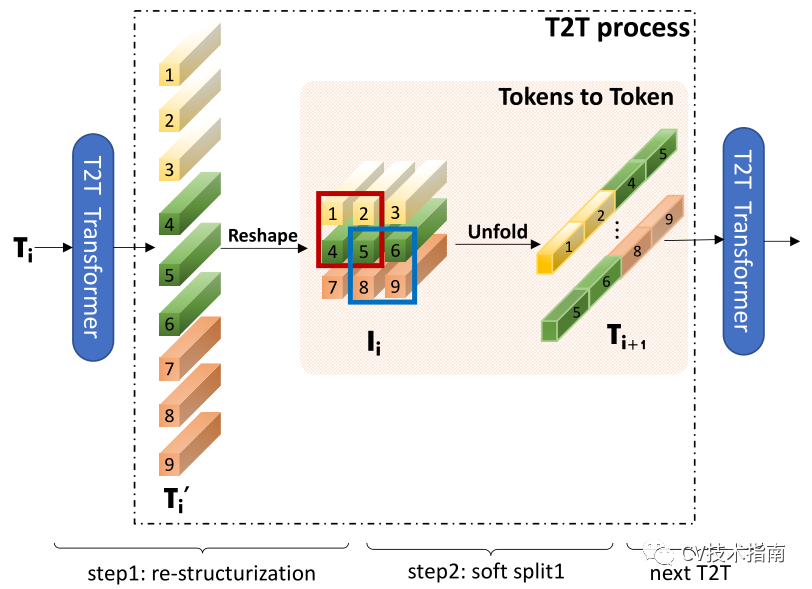
图3.T2T流程图解。
经过变换和reshape后,tokens Ti被重构为图像Ii,然后重叠split为tokens Ti+1。具体地说,如粉色面板中所示,输入Ii的四个tokens(1、2、4、5)被串联以形成一个tokens 在Ti+1。T2T transformer可以是普通的transformer 层或有限GPU存储器中的像Performer层这样的其他高效transformer。
在进行soft split时,每个块的大小为k×k,在图像上叠加s个,其中k−类似于卷积运算中的步长。因此,对于重建图像I_∈_rh×w×c,soft split后的输出tokens的长度为
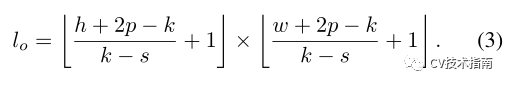
每个分割patches的大小为k×k×c。将空间维度上的所有patches展平,以To表示。在soft split之后,为下一个T2T过程馈送输出tokens。
通过迭代进行上述重构和soft split,T2T模块可以逐步减少tokens的长度,并转换图像的空间结构。T2T模块中的迭代过程可以表示为
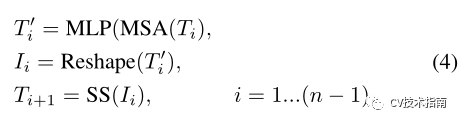
对于输入image I0,首先应用soft split将其分割为tokens:T1=SS(I0)。在最终迭代后,T2T模块的输出tokens Tf具有固定的长度,因此T2T-ViT的主干可以对Tf上的全局关系进行建模。
T2T-ViT Backbone
论文探索了不同的VIT体系结构设计,并借鉴了CNN的一些设计,以提高骨干网的效率,增强学习特征的丰富性。由于每个transformer层都有跳跃连接,一个简单的想法是采用如DenseNet的密集连接来增加连通性和特征丰富性,或者采用Wide-ResNets或ResNeXt结构来改变VIT主干中的通道尺寸和头数。
论文探讨了从CNN到VIT的五种架构设计:
密集连接如DenseNet;
深-窄与浅-宽结构如宽ResNet];
通道注意如挤压-激励(SE)网络;
多头注意层中更多的分头如ResNeXt;
Ghost操作如Ghost
Net。
实验发现:1)采用简单降低通道维数的深窄结构来减少通道中的冗余,增加层深来提高VIT中的特征丰富度,模型尺寸和MACs都有所减小,但性能有所提高;2)SE块的通道关注度也提高了VIT,但效果不如深窄结构。
基于这些发现,论文为T2T-VIT骨干网设计了一种深窄结构。具体地说,它具有较小的通道数和隐藏维度d,但具有更多的层b。对于T2T模块最后一层定长的Token,论文在其上拼接一个类Token,然后添加正弦位置嵌入(PE),与VIT一样进行分类:
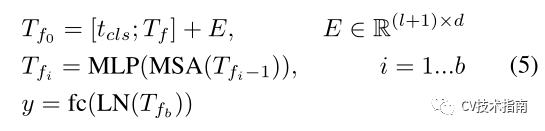
T2T-ViT Architecture

T2T-VIT的结构细节。T2T-VIT-14/19/24的型号尺寸与ResNet50/101/152相当。T2T-VIT-7/12的型号大小与MobileNetV1/V2相当。对于T2T transformer 层,在有限的GPU内存下,论文采用了T2T-VITT-14的transformer层和T2T-VIT-14的Performer层。对于VIT,‘S’表示小,‘B’表示基本,‘L’表示大。‘VIT-S/16’是原始VIT-B/16的变体,具有更小的MLP大小和层深。
Conclusion
如图1所示,论文的215M参数和5.2G MACS的T2T-ViT在ImageNet上可以达到81.5%的TOP-1准确率,远远高于ViT的48.6M参数和10.1G MACs的TOP-1准确率(78.1%)。这一结果也高于流行的类似大小的CNN,如具有25.5M参数的ResNet50(76%-79%)。此外,论文还通过简单地采用更少的层来设计T2T-ViT的精简变体,取得了与MobileNets(图1)相当的结果。
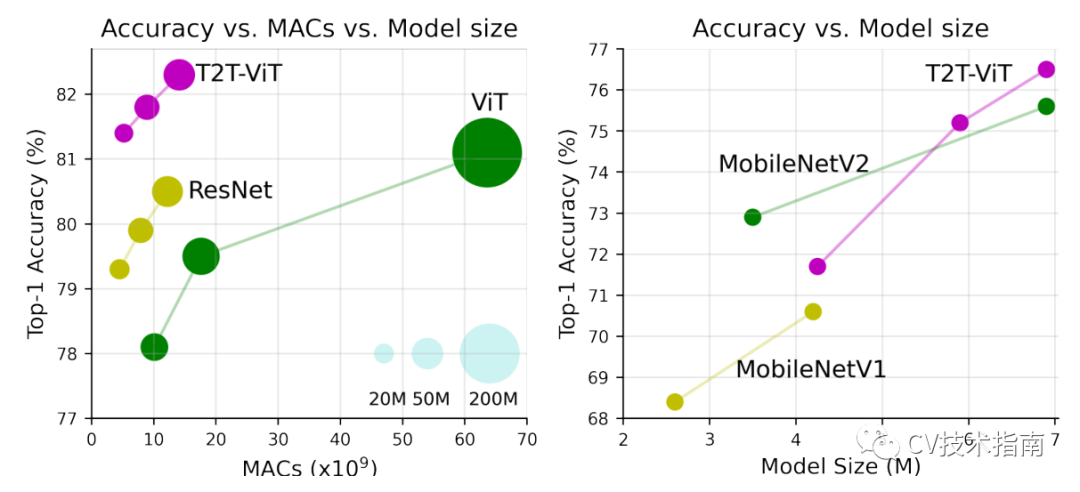
T2T-VIT与VIT在ImageNet上从头训练的比较

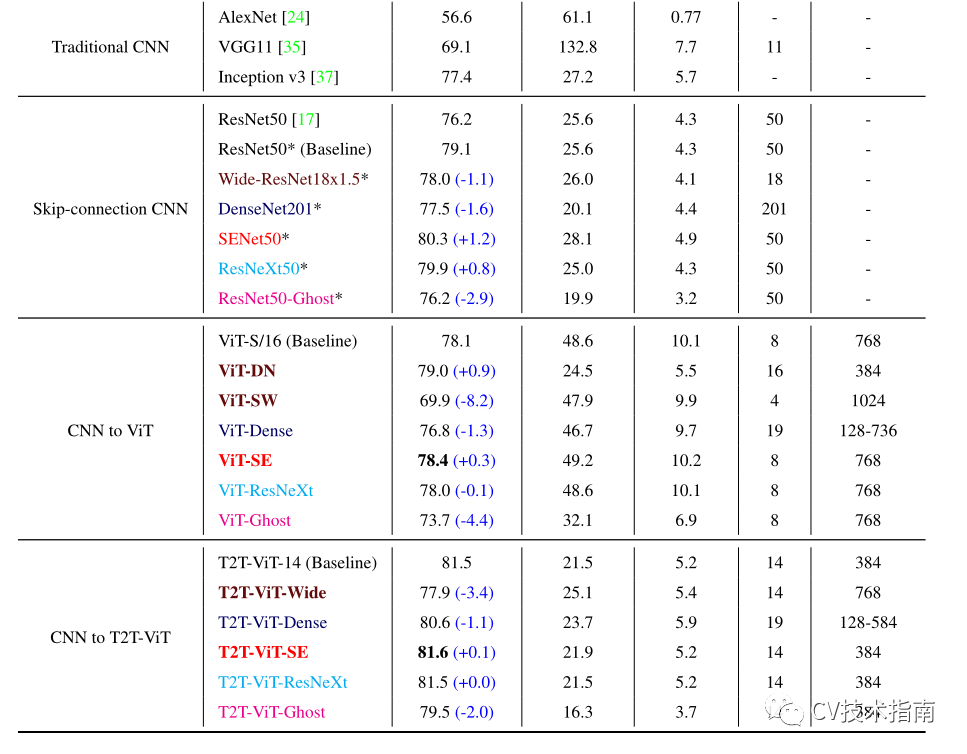
将CNN中的一些常用设计移植到VIT&T2T-VIT中,包括DenseNet、Wide-ResNet、SE模块、ResNeXt、Ghost操作。相同的颜色表示相应的迁移。所有模型都是在ImageNet上从头开始训练的。
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
