
DynamicViT:动态Token稀疏化ViT 论文解读
及时获取最优质的CV内容

【Vision Transformer 解读】仅代表个人理解,如果有理解错误的地方欢迎纠正~
原文地址:DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
github源码:raoyongming/DynamicViT
文中提出了一种动态token稀疏化的视觉Transformer,通过分层剪枝的操作,即在ViT的不同层中动态地筛选所需要传入下一层的token数量,来达到加速inference的目的。文中的分层剪枝策略,最终剪枝了约66%的token数量,可以减少31%~37%的FLOPs,提高40%左右的模型运行速度。并且准确率只下降了0.5%不到。
01
Motivation
文中通过可视化发现,在Vision Transformer的视觉推理过程中,Attention主要集中在一部分信息丰富的patch上,如图1所示。这意味着在prediction的过程中,我们可以只保留重要性较大的token,动态地去除重要性较低的token,不会对最终的预测结果带来较大的影响。

文中的可视化使用的以下paper中的Attention可视化方法,收录于CVPR2021,感兴趣的可以去看看源码。
论文地址:
Transformer Interpretability Beyond Attention Visualization
源码地址:
hila-chefer/Transformer-Explainability
在传统的卷积神经网络中,为了加速模型的计算,往往会用到池化等方法来减少输入的feature map大小,也就是一种结构化的下采样方法,而对于Transformer模型来说,以往的加速工作侧重点在于,如何降低Attention Map计算的复杂度,例如Reformer、Linformer、Performer等,但由于Transformer本身的结构,可以处理动态长度的输入序列,因此可以从另外一个思路去进行剪枝加速,即针对输入的token,将对于prediction贡献度不大的token减去,如图2中的(b)所示,只保留重要的token,将不重要的token去除。并且针对不同的样本,包含重要information的token不一致,因此需要实现一个data-dependent的sparsification策略,根据不同的样本,自适应地去选择包含重要information的token

02
Method
02
Method
基于以上的motivation及对应分析,文中提出了一个data-dependent的predictor模块,来自适应地选择出重要的token。

整体架构如图3所示,包含一个主干的网络,例如:DeiT,LV-ViT等,另外包含了额外插入的预测模块,来动态稀疏化token。
为了减少预测的成本开销:文中使用的prediction模块是比较轻量化的MLP网络
对于输入包含N个C维Token的
然后在通过简单的全局池化,得到一个包含全局信息的向量:
对于该公式中的几个部分说明,其中
最终将全局向量与每个token拼接,输入到轻量化的MLP模块中预测出一个二值化的Mask来表示这一层中sparse策略所保留的token。
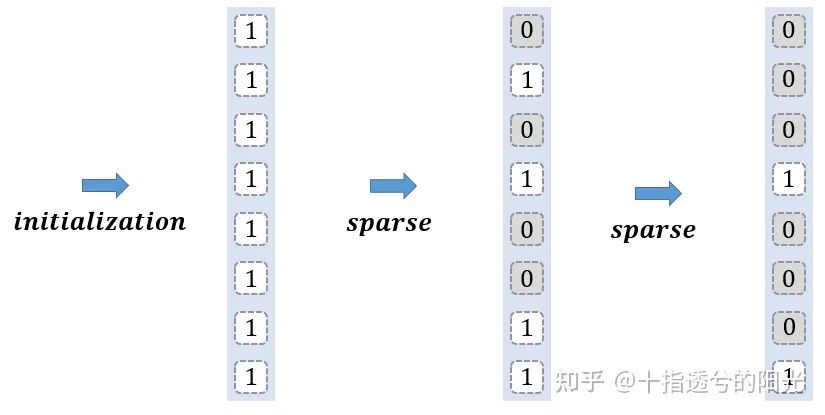
需要注意的是,在整个网络中都维护着一个初始化全为1的二值mask,在文中用
可视化流程如下所示:

在初始阶段,默认所有token参与计算。
在经过一次sparsification操作后,模型会根据输入的data,predict出一个新的二值mask,并与当前的mask合并,经过predict出来不重要的token不参与计算,如下图所示,不重要的部分用0表示。
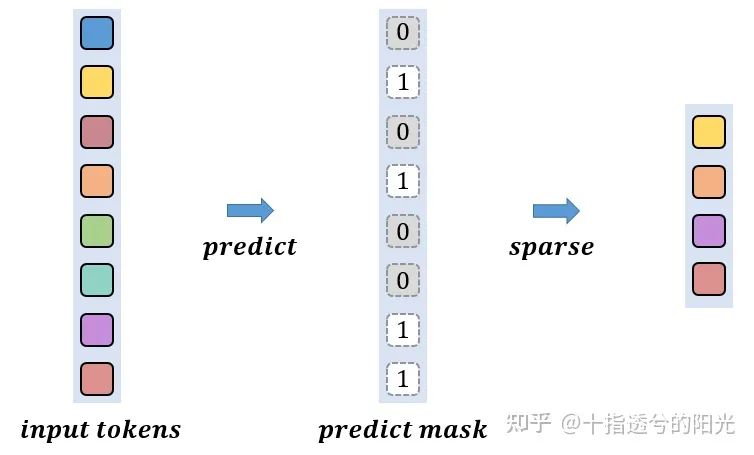
整个mask的稀疏化过程可以用下图表示:需要注意的是,每个阶段中所被放弃的token,在之后的阶段不会再参与更深层次中的attention的计算,所以这个二值化mask中为0的部分是不会变化的,在每一层中都会保留。
整个predictor模块的代码说明如下:从官方代码拷贝下来的,感兴趣的可以去阅读源码~
class PredictorLG(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, embed_dim=384):
super().__init__()
# local建模
self.in_conv = nn.Sequential(
nn.LayerNorm(embed_dim),
nn.Linear(embed_dim, embed_dim),
nn.GELU()
)
# 为每个token预测一个两维的向量,来表示当前token是否需要被mask掉
self.out_conv = nn.Sequential(
nn.Linear(embed_dim, embed_dim // 2),
nn.GELU(),
nn.Linear(embed_dim // 2, embed_dim // 4),
nn.GELU(),
nn.Linear(embed_dim // 4, 2),
nn.LogSoftmax(dim=-1)
)
def forward(self, x, policy):
# x 表示当前输入的tokens
# policy表示当前的mask,由0和1组成,0表示不需要参与后序计算的token
x = self.in_conv(x) # 对于输入的每一个token先经过一层linear projection对局部信息进行建模
B, N, C = x.size()
local_x = x[:,:, :C//2]
# 在计算全局向量的时候,只对参与后序计算的token进行全局池化操作
global_x = (x[:,:, C//2:] * policy).sum(dim=1, keepdim=True) / torch.sum(policy, dim=1, keepdim=True)
# 将全局向量与局部向量拼接
x = torch.cat([local_x, global_x.expand(B, N, C//2)], dim=-1)
# 通过简单的MLP来输出每个token是否需要保留的一个分数,一组score
return self.out_conv(x)在进行local向量的linear projection和预测每个token是否需要保留的score的时使用MLP的原因是为了让整个predictor模块轻量化。
笔者用随机的数据进行测试的结果如下:
x = torch.randn(2, 14, 384) # 随机初始化一个batch size为2,token数量为14,每个token维度为384的输入数据
prev_decision = torch.ones(2, 14 ,1) # 初始化一个全为1的mask
pred_score = predictor(x, prev_decision) # 将policy和x同时输入到predictor模块中,得到一个score向量
print(pred_score)所输出的pred_score如下:
tensor([[[-0.6901, -0.6963],
[-0.6839, -0.7025],
[-0.6914, -0.6949],
[-0.6991, -0.6873],
[-0.6854, -0.7009],
[-0.6829, -0.7035],
[-0.7014, -0.6849],
[-0.7043, -0.6821],
[-0.6982, -0.6881],
[-0.6844, -0.7020],
[-0.7058, -0.6806],
[-0.6888, -0.6975],
[-0.6916, -0.6947],
[-0.7000, -0.6863]],
[[-0.7011, -0.6853],
[-0.6940, -0.6923],
[-0.6988, -0.6875],
[-0.6869, -0.6994],
[-0.6981, -0.6882],
[-0.6957, -0.6906],
[-0.6889, -0.6974],
[-0.7022, -0.6841],
[-0.7027, -0.6837],
[-0.6872, -0.6991],
[-0.6941, -0.6922],
[-0.6915, -0.6948],
[-0.6931, -0.6932],
[-0.6863, -0.7000]]], grad_fn=<LogSoftmaxBackward>)对于输出的score,文中使用了Gumbel-Softmax trick进行了二值化操作,之所以使用Gumbel-Softmax操作是为了让整个二值化的过程是可导的。
hard_keep_decision = F.gumbel_softmax(pred_score, hard=True)[:, :, 0:1] * prev_decision
print(hard_keep_decision)二值化后的mask输出如下:
tensor([[[0.],
[0.],
[1.],
[0.],
[1.],
[1.],
[0.],
[0.],
[0.],
[1.],
[1.],
[1.],
[1.],
[1.]],
[[1.],
[1.],
[1.],
[1.],
[1.],
[0.],
[1.],
[1.],
[0.],
[1.],
[1.],
[1.],
[0.],
[0.]]], grad_fn=<MulBackward0>)预测出了一个稀疏的二值化mask,其中1的位置表示需要保留的token,0表示不重要的token,不参与后序计算。
Training Details
在网络的训练过程中,为了实现并行化,不会将无用的token剪去,而是采用了一个注意力masking策略,注意力masking策略的意思是,在self-attention中计算attention map时,加上一个mask,来显示地切断token之间的联系,已经被稀疏化的token不参与attention的计算。让模型的训练更加稳定。
稍加注释的源码如下:
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def softmax_with_policy(self, attn, policy, eps=1e-6):
# 将输入的policy转化为对应的mask,保证mask中值为0的token不参与attention的计算
B, N, _ = policy.size()
B, H, N, N = attn.size()
attn_policy = policy.reshape(B, 1, 1, N) # * policy.reshape(B, 1, N, 1)
eye = torch.eye(N, dtype=attn_policy.dtype, device=attn_policy.device).view(1, 1, N, N)
attn_policy = attn_policy + (1.0 - attn_policy) * eye
max_att = torch.max(attn, dim=-1, keepdim=True)[0]
attn = attn - max_att
# attn = attn.exp_() * attn_policy
# return attn / attn.sum(dim=-1, keepdim=True)
# for stable training
attn = attn.to(torch.float32).exp_() * attn_policy.to(torch.float32)
attn = (attn + eps/N) / (attn.sum(dim=-1, keepdim=True) + eps)
return attn.type_as(max_att)
def forward(self, x, policy):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
if policy is None:
attn = attn.softmax(dim=-1)
else:
attn = self.softmax_with_policy(attn, policy)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x可视化过程如下所示:其中被稀疏化的token只与自身作Attention计算
首先将当前的二值化mask转化为attention mask:

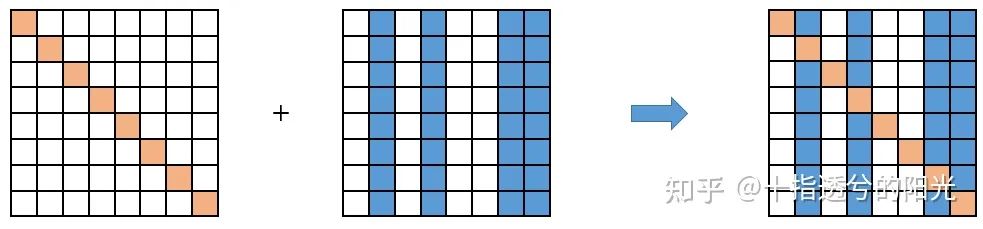
将最终的attention mask加到计算后的attention map上,这样就可以显示地切断已经被筛选掉的token与其他token之间的交互,保证最后prediction的结果只与保留下来的token有关。
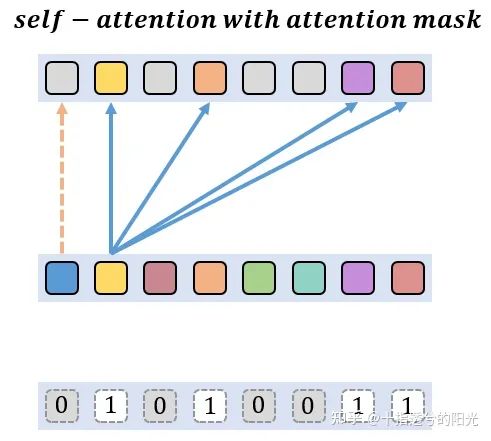
Testing Details
在测试阶段,为了加速推理速度,DynamicViT的做法是,对每个token,按照PredictorLG模块所输出的保留概率进行排序,每次保留排序靠前的,固定比率的token。假设有12层的Vision Transformer,文中的做法是将PredictorLG模块分别放在第4层,第7层,第9层之前,在训练阶段不直接剔除token,而是采用attention masking策略,而在测试阶段每层剔除一定比率的token,如果文中设置的比率为0.7,那么经过三个PredictorLG模块后,所保留的token数量大约为:
Training and Inference
为了最小化 token sparsification对模型性能带来的影响,文中以original ViT backbone作为teacher model,并且希望DynamicViT的behavior能尽可能地接近original ViT backbone。
First
让最终保存下来的token特征尽可能地接近teacher model对应同样位置的token特征,不需要考虑在之前的sparsification stage未保存下来的token。可以看作是一种自蒸馏的方式。

其中
Second
最小化DynamicViT和Teacher Model之间的预测差异:
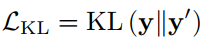
Finally
希望DynamicViT在每个sparsification stage最终保留的token比例接近我们人为预设的值

其中
最终的损失函数如下:
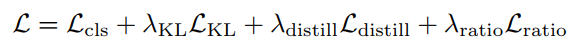
DynamicViT的实验设置为
在Inference阶段,在每一个sparsification stage给定一个所需保留token的比率
这个保留的token是根据score排序得到的,也就是以下公式,score大意味着information丰富。
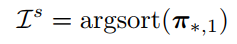
03
Experiments
03
Experiments

可以看到在每个stage都只保留
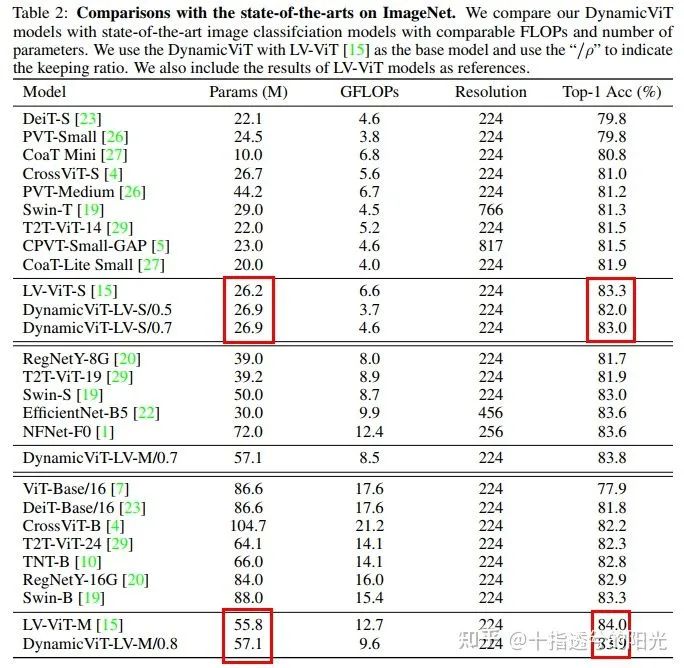
可以看出在仅增加少量参数的情况下,DynamicViT可以大幅度减少GFLOPs,并依然可以保证模型的准确率。
为了验证文中提出的动态模块的有效性,文中还对其他sparsification策略进行了比较,如下表所示:
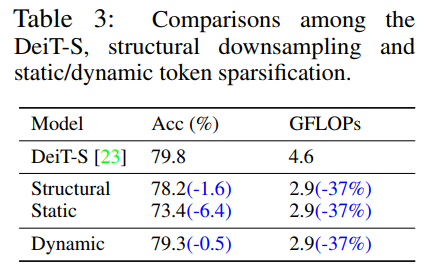
其中 Structural 表示的是 kernel size=2 和 stride=2 的 Average Pooling,文中将这个pooling操作放在网络的第6层,Static表示的是,整个网络学习出来一个统一的sparsification mask,而非数据依赖的,意味着不能根据样本动态调整所需要的舍弃的token,对于每个样本而言所舍弃的token都是相同位置的。
可以看出在同等GFLOPs下,文中的Dynamic Sparsification策略为模型带来的影响最小。
Visualization

可视化结果可以看出,经过每个stage后,包含信息量比较丰富的token都被保存了下来,不相关的背景token都被舍弃了。
Reference
[1] DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification

全新激活函数 | 详细解读:HP-x激活函数(附论文下载)

遮挡人脸问题 | 详细解读Attention-Based方法解决遮挡人脸识别问题(附论文下载)
