
多标签学习的新趋势(2020 Survey)

极市导读
随着Deep learning领域的不断发展,我们面对的问题也越发的复杂,也需要考虑高度结构化的输出空间,本文总共分为了六个部分,整理了近年多标签学习在各大会议的工作,对多标签学习的发展领域和方向提供了一些思考。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
这里给大家带来一篇武大刘威威老师、南理工沈肖波老师和UTS Ivor W. Tsang老师合作的2020年多标签最新的Survey,我也有幸参与其中,负责了一部分工作。
论文:《The Emerging Trends of Multi-Label Learning》
链接:https://arxiv.org/abs/2011.11197
作者:Weiwei Liu, Xiaobo Shen, Haobo Wang, Ivor W. Tsang
上半年在知乎上看到有朋友咨询多标签学习是否有新的Survey,我搜索了一下,发现现有的多标签Survey基本在2014年之前,主要有以下几篇:
Tsoumakas的《Multi-label classification: An overview》(2007) https://www.igi-global.com/article/multi-label-classification/1786 周志华老师的《A review on multi-label learning algorithms》(2013) https://ieeexplore.ieee.org/abstract/document/6471714/ 一篇比较小众的,Gibaja 《Multi‐label learning: a review of the state of the art and ongoing research》2014
时过境迁,从2012年起,AI领域已经发生了翻天覆地的变化,Deep Learning已经占据绝对的主导地位,我们面对的问题越来越复杂,CV和NLP朝着各自的方向前行。模型越来越强,我们面对的任务的也越来越复杂,其中,我们越来越多地需要考虑高度结构化的输出空间。多标签学习,作为一个传统的机器学习任务,近年来也拥抱变化,有了新的研究趋势。因此,我们整理了近年多标签学习在各大会议的工作,希望能够为研究者们提供更具前瞻性的思考。
本文的主要内容有六大部分:
Extreme Multi-Label Classification Multi-Label with Limited Supervision Deep Multi-Label Classification Online Multi-Label Classification Statistical Multi-Label Learning New Applications
接下去我们对这些部分进行简单的介绍,更多细节大家也可以进一步阅读Survey原文。另外,由于现在的论文迭代很快,我们无法完全Cover到每篇工作。我们的主旨是尽量保证收集的工作来自近年已发表和录用的、高质量的期刊或会议,保证对当前工作的整体趋势进行把握。如果读者有任何想法和意见的话,也欢迎私信进行交流。
1. Extreme Multi-Label Learning (XML)
在文本分类,推荐系统,Wikipedia,Amazon关键词匹配[1]等等应用中,我们通常需要从非常巨大的标签空间中召回标签。比如,很多人会po自己的自拍到FB、Ins上,我们可能希望由此训练一个分类器,自动识别谁出现在了某张图片中。对XML来说,首要的问题就是标签空间、特征空间都可能非常巨大,例如Manik Varma大佬的主页中给出的一些数据集[2],标签空间的维度甚至远高于特征维度。其次,由于如此巨大的标签空间,可能存在较多的Missing Label(下文会进一步阐述)。最后,标签存在长尾分布[3],绝大部分标签仅仅有少量样本关联。现有的XML方法大致可以分为三类,分别为:Embedding Methods、Tree-Based Methods、One-vs-All Methods。近年来,也有很多文献使用了深度学习技术解决XML问题,不过我们将会在Section 4再进行阐述。XML的研究热潮大概从2014年开始,Varma大佬搭建了XML的Repository后,已经有越来越多的研究者开始关注,多年来XML相关的文章理论和实验结果并重,值得更多的关注。

Fig. 2. An extreme multi-label learning example. This picture denotes an instance, the faces denote the labels.
2. Multi-Label with Limited Supervision
相比于传统学习问题,对多标签数据的标注十分困难,更大的标签空间带来的是更高的标注成本。随着我们面对的问题越来越复杂,样本维度、数据量、标签维度都会影响标注的成本。因此,近年多标签的另一个趋势是开始关注如何在有限的监督下构建更好的学习模型。本文将这些相关的领域主要分为三类:
MLC with Missing Labels(MLML):多标签问题中,标签很可能是缺失的。例如,对XML问题来说,标注者根本不可能遍历所有的标签,因此标注者通常只会给出一个子集,而不是给出所有的监督信息。文献中解决该问题的技术主要有基于图的方法、基于标签空间(或Latent标签空间)Low-Rank的方法、基于概率图模型的方法。
Semi-Supervised MLC:MLML考虑的是标签维度的难度,但是我们知道从深度学习需要更多的数据,在样本量上,多标签学习有着和传统AI相同的困难。半监督MLC的研究开展较早,主要技术和MLML也相对接近,在这一节,我们首先简要回顾了近年半监督MLC的一些最新工作。但是,近年来,半监督MLC开始有了新的挑战,不少文章开始结合半监督MLC和MLML问题。毕竟对于多标签数据量来说,即使标注少量的Full Supervised数据,也是不可接受的。因此,许多文章开始研究一类弱监督多标签问题[4](Weakly-Supervised MLC,狭义),也就是数据集中可能混杂Full labeled/missing labels/unlabeled data。我们也在文中重点介绍了现有的一些WS-MLC的工作。
Partial Multi-Label Learning(PML):PML是近年来多标签最新的方向,它考虑的是一类“难以标注的问题”。比如,在我们标注下方的图片(Zhang et. al. 2020[5])的时候,诸如Tree、Lavender这些标签相对是比较简单的。但是有些标签到底有没有,是比较难以确定的,对于某些标注者,可能出现:“这张图片看起来是在法国拍的,好像也可能是意大利?”。这种情况称之为Ambiguous。究其原因,一是有些物体确实难以辨识,第二可能是标注者不够专业(这种多标签的情况,标注者不太熟悉一些事物也很正常)。但是,很多情况下,标注者是大概能够猜到正确标签的范围,比如这张风景图所在国家,很可能就是France或者Italy中的一个。我们在不确定的情况下,可以选择不标注、或者随机标注。但是不标注意味着我们丢失了所有信息,随机标注意味着可能带来噪声,对学习的影响更大。所以PML选择的是让标注者提供所有可能的标签,当然加了一个较强的假设:所有的标签都应该被包含在候选标签集中。在Survey中,我们将现有的PML方法划分为Two-Stage Disambiguation和End-to-End方法(我们IJCAI 2019的论文DRAMA[6]中,就使用了前者)。关于PML的更多探讨,我在之前的知乎回答(https://www.zhihu.com/question/418818026/answer/1454922545)里面也已经叙述过,大家也可以在我们的Survey中了解更多。

Other Settings:前文说过,多标签学习的标签空间纷繁复杂,因此很多研究者提出了各种各样不同的学习问题,我们也简单摘要了一些较为前沿的方向:
MLC with Noisy Labels (Noisy-MLC). MLC with Unseen Labels. (Streaming Labels/Zero-Shot/Few-Shot Labels) Multi-Label Active Learning (MLAL). MLC with Multiple Instances (MIML).
3. Deep Learning for MLC
相信这一部分是大家比较关心的内容,随着深度学习在越来越多的任务上展现了自己的统治力,多标签学习当然也不能放过这块香饽饽。不过,总体来说,多标签深度学习的模型还没有十分统一的框架,当前对Deep MLC的探索主要分为以下一些类别:
Deep Embedding Methods:早期的Embedding方法通常使用线性投影,将PCA、Compressed Sensing等方法引入多标签学习问题。一个很自然的问题是,线性投影真的能够很好地挖掘标签之间的相关关系吗?同时,在SLEEC[3]的工作中也发现某些数据集并不符合Low-Rank假设。因此,在2017年的工作C2AE[7]中,Yeh等将Auto-Encoder引入了多标签学习中。由于其简单易懂的架构,很快有许多工作Follow了该方法,如DBPC[8]等。
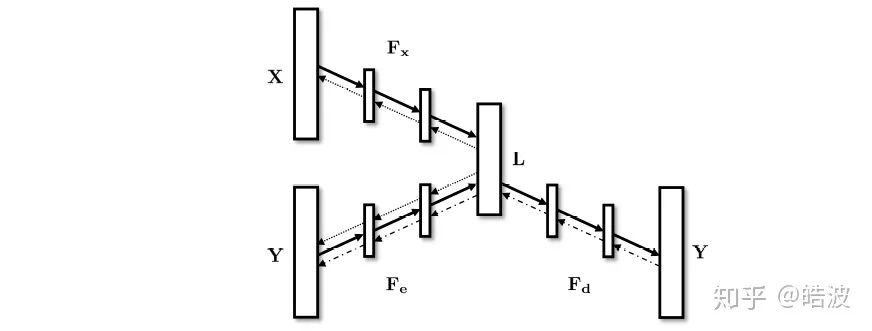
Fig. 4. The architecture of Canonical-Correlated Autoencoder (C2AE).C2AE learns a latent space L via NN mappings of Fx, Fe, and Fd. X and Y are the instance and label matrices respectively.
Deep Learning for Challenging MLC:深度神经网络强大的拟合能力使我们能够有效地处理更多更困难的工作。因此我们发现近年的趋势是在CV、NLP和ML几大Community,基本都会有不同的关注点,引入DNN解决MLC的问题,并根据各自的问题发展出自己的一条线。
XML的应用:对这个方面的关注主要来自与数据挖掘和NLP领域,其中比较值得一提的是Attention(如AttentionXML[9])机制、Transformer-Based Models(如X-Transformer[10])成为了最前沿的工作。 弱监督MLC的应用:这一部分和我们弱监督学习的部分相对交叉,特别的,CVPR 2019的工作[11]探索了多种策略,在Missing Labels下训练卷积神经网络。 DL for MLC with unseen labels:这一领域的发展令人兴奋,今年ICML的工作DSLL[12]探索了流标签学习,也有许多工作[13]将Zero-Shot Learning的架构引入MLC。
Advanced Deep Learning for MLC:有几个方向的工作同样值得一提。首先是CNN-RNN[14]架构的工作,近年有一个趋势是探索Orderfree的解码器[15]。除此之外,爆火的图神经网络GNN同样被引入MLC,ML-GCN[16]也是备受关注。特别的,SSGRL[17]是我比较喜欢的一篇工作,结合了Attention机制和GNN,motivation比较强,效果也很不错。
总结一下,现在的Deep MLC呈现不同领域关注点和解决的问题不同的趋势:
从架构上看,基于Embedding、CNN-RNN、CNN-GNN的三种架构受到较多的关注。 从任务上,在XML、弱监督、零样本的问题上,DNN大展拳脚。 从技术上,Attention、Transformer、GNN在MLC上的应用可能会越来越多。
4. Online Multi-Label Learning
面对当前这么复杂而众多的学习问题,传统的全数据学习的方式已经很难满足我们现实应用的需求了。因此,我们认为Online Multi-Label Learning可能是一个十分重要,也更艰巨的问题。当前Off-line的MLC模型一般假设所有数据都能够提前获得,然而在很多应用中,或者对大规模的数据,很难直接进行全量数据的使用。一个朴素的想法自然是使用Online模型,也就是训练数据序列地到达,并且仅出现一次。然而,面对这样的数据,如何有效地挖掘多标签相关性呢?本篇Survey介绍了一些已有的在线多标签学习的方法,如OUC[18]、CS-DPP[19]等。在弱监督学习的部分,我们也回顾了近年一些在线弱监督多标签的文章[20](在线弱监督学习一直是一个很困难的问题)。Online MLC的工作不多,但是已经受到了越来越多的关注,想要设计高效的学习算法并不简单,希望未来能够有更多研究者对这个问题进行探索。
5. Statistical Multi-Label Learning
近年,尽管深度学习更强势,但传统的机器学习理论也在稳步发展,然而,多标签学习的许多统计性质并没有得到很好的理解。近年NIPS、ICML的许多文章都有探索多标签的相关性质。一些值得一提的工作例如,缺失标签下的低秩分类器的泛化误差分析[21]、多标签代理损失的相合性质[22]、稀疏多标签学习的Oracle性质[23]等等。相信在未来,会有更多工作探索多标签学习的理论性质。
6. New Applications
讲了这么多方法论,但追溯其本源,这么多纷繁复杂的问题依然是由任务驱动的,正是有许许多多现实世界的应用,要求我们设计不同的模型来解决尺度更大、监督更弱、效果更强、速度更快、理论性质更强的MLC模型。因此,在文章的最后一部分,我们介绍了近年多标签领域一些最新的应用,如Video Annotation、Green Computing and 5G Applications、User Profiling等。在CV方向,一个趋势是大家开始探索多标签领域在视频中的应用[24]。在DM领域,用户画像受到更多关注,在我们今年的工作CMLP[25]中(下图),就探索了对刷单用户进行多种刷单行为的分析。不过,在NLP领域,似乎大家还是主要以文本分类为主,XML-Repo[2]中的应用还有较多探索的空间,所以我们没有花额外的笔墨。
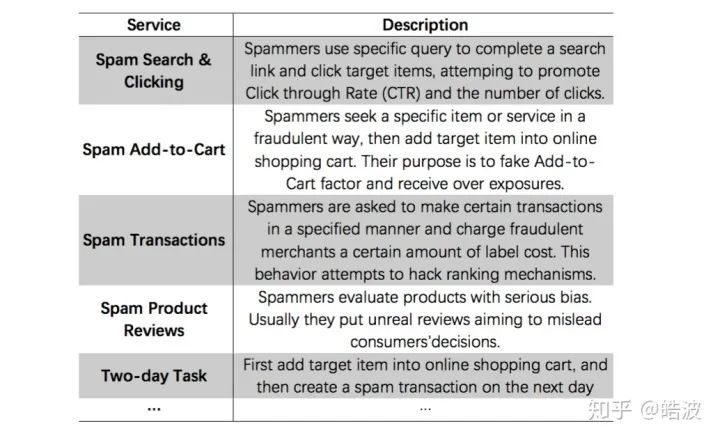
Figure 6: Some services that a malicious service platform provides. The dishonest merchants can freely select different combinations of these services, e.g. Two-day Task.
总结
写这篇文章的过程中,我跟着几位老师阅读了很多文章,各个领域和方向的工作都整理了不少,尽管无法cover到所有工作,但是我们尽可能地把握了一些较为重要的探索的方向,也在文中较为谨慎地给出了一些我们的思考和建议,希望能够给想要了解多标签学习领域的研究者一点引领和思考。
参考
推荐阅读
