
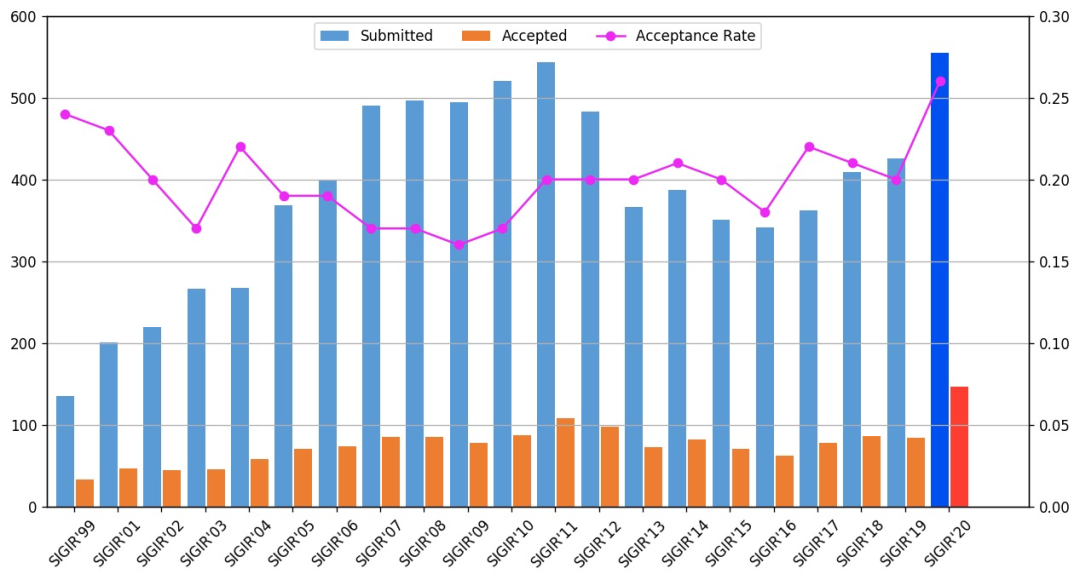
SIGIR 2020最佳论文公布,清华大学揽多个奖项,大三学生摘得最佳短论文奖

新智元报道
新智元报道
来源:智源研究院
编辑:白峰
【新智元导读】7月29日晚,第43届国际 「信息检索研究与发展」 年会(SIGIR - The International ACM SIGIR Conference on Research and Development in Information Retrieval)最佳论文正式公布。

排序算法在很多在线平台将用户和项目(比如新闻产品音乐等)进行匹配,在用户和项目双边考虑中,用户不仅评估排序算法的效益,而且排序算法本身也影响了项目提供端(比如出版商)的效益(比如曝光度)。目前的排序算法中并没有考虑到在项目提供端的效益。基于这些考虑,本文提出了显性的基于组(比如相同出版商出版的文章)的公平排序算法。在保证公平的同时,本文的算法可以有效的优化排序算法的效果。
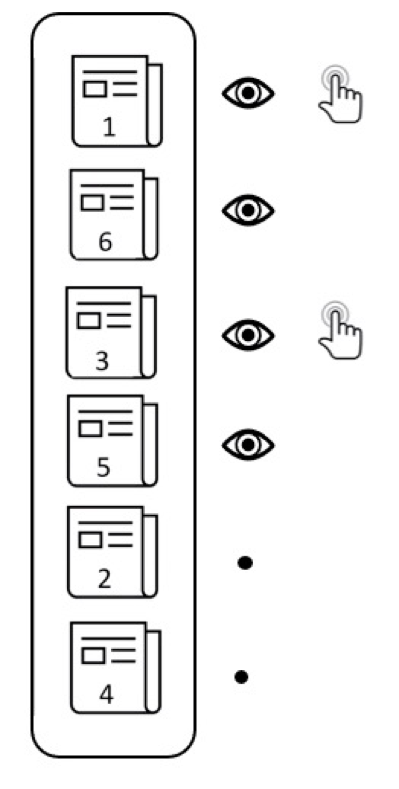
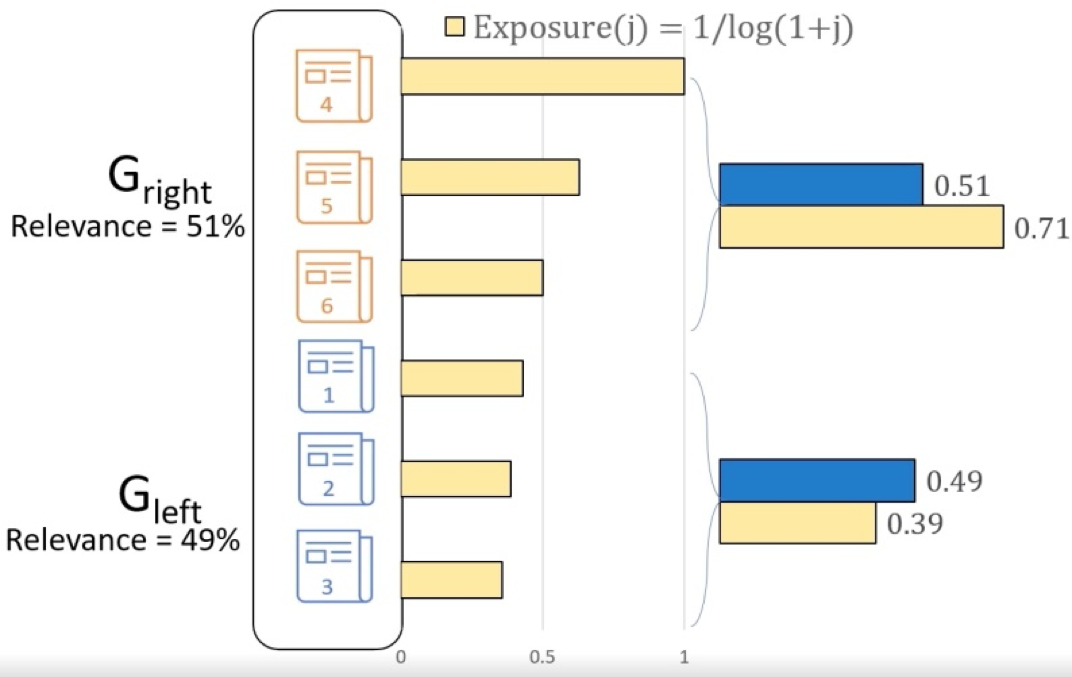 公平性示意图(图中左右排序项目的曝光度与相关度并不是正比的,所以是不公平的)
公平性示意图(图中左右排序项目的曝光度与相关度并不是正比的,所以是不公平的)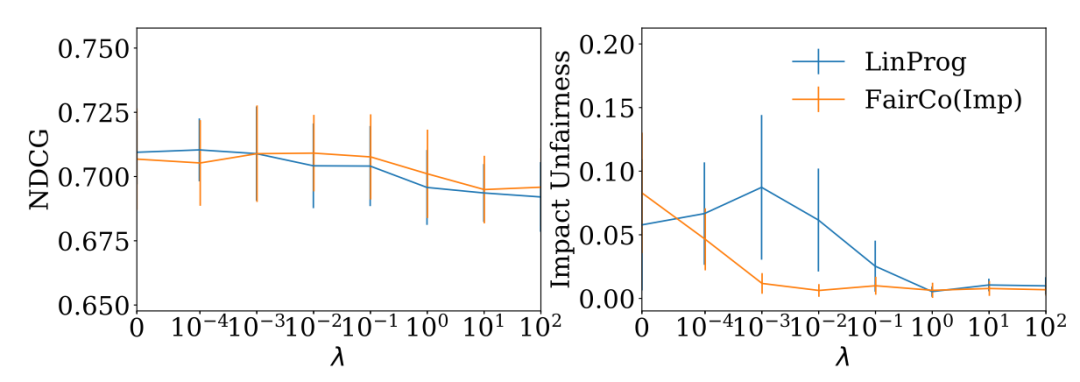 实验结果图(左图排序算法表现,右图公平表现)
实验结果图(左图排序算法表现,右图公平表现)
最佳论文荣誉提名奖

最佳论文荣誉提名奖
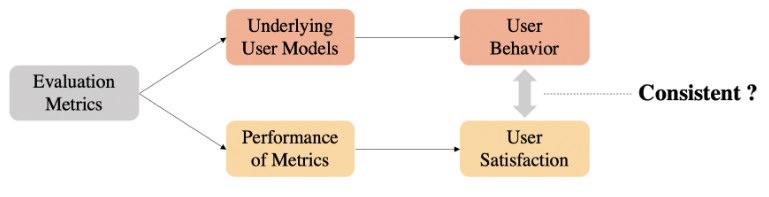
评价指标背后的用户模型能否准确地拟合用户行为; 评价指标的评价分数能否有效地衡量用户满意度。
最佳短论文奖 I

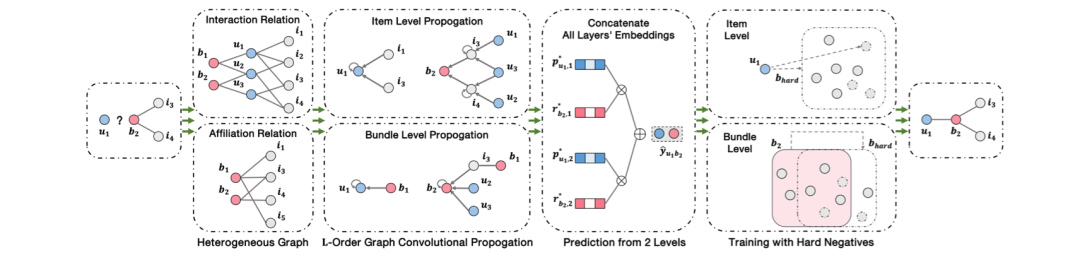
最佳短论文奖 I
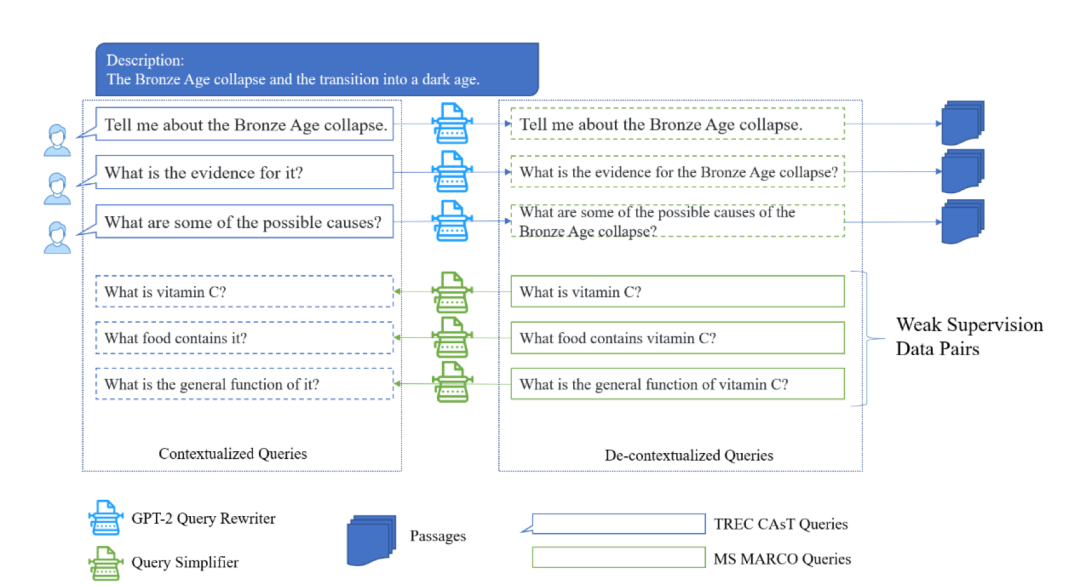
最佳短论文奖 II

Test of Time Award

Test of Time Award Honorable Mention I

Test of Time Award Honorable Mention II

附:SIGIR近5年最佳论文
评论