2021年11月12日凌晨,迟迟未公布的CoRL 2021论文奖名单终于揭晓。备受关注的论文大奖全部被华人学者包揽。来自麻省理工大学的Tao Chen, Jie Xu, Pulkit Agrawal(导师)拿下最佳论文奖;来自哥伦比亚大学的Huy Ha, 宋舒然(导师)拿下最佳系统论文奖。
本次获提名奖的共有七篇论文,四篇最佳论文奖提名,三篇最佳系统论文提名。七篇佳作皆有华人学者参与。占比42.3%。
CoRL于11月8日——11日在伦敦举行。同时在网络上也开设了虚拟会场以飨诸位:PheedLoop主题演讲、指导性建议和论文演讲;gather.town 用于海报会议和交流。即使不能到现场的同学,也不用担心错过关注论文的演讲了。
官网链接:https://www.robot-learning.org/program/awards_2021
Youtube直播链接:https://www.youtube.com/watch?v=5KjpZS4_RBs
荣获CoRL 2021最佳论文奖的是:

麻省理工学院《A System for General In-Hand Object Re-Orientation》
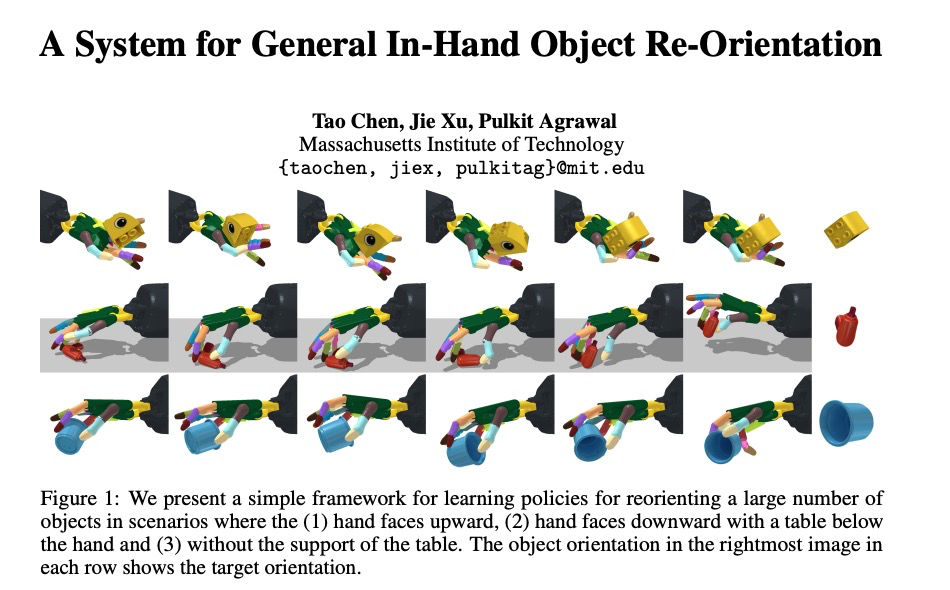
论文链接:https://openreview.net/forum?id=7uSBJDoP7tY
作者:Tao Chen, Jie Xu, Pulkit Agrawal
论文介绍:
由于高维驱动空间以及手指与物体之间接触状态的频繁变化,手持物体重新定向一直是机器人技术中难攻克的问题。Tao Chen等人提出一个简单的框架,框架的核心是无模型强化学习:可被称为“师生关系”的训练法、重力课程设置和物体稳定初始化。它可以解决复杂的问题,用机械手学习重新定向,让2000多个不同物体的系统面朝上和朝下。该系统不需要物体或机械手模型、接触动力学和任何特殊的感官观察预处理。
过去的一些方法,如使用强大轨迹优化法分析模型,虽然解决了重新定向问题,但结果主要是在模拟简单的几何形状,无法拓展到现实中推广到新对象,结果差强人意。
Tao Chen他们的研究首先在模拟中对“老师”无模型强化学习(model-free Reinforcement Learning)进行有关物体和机器人信息的训练,为了确保机器人可在现实中运作,模拟中缺失的信息如指间的位置,强化学习智能体接受的知识被转化为模拟外可用的数据,像摄像机捕获的深度图像等。为了提高性能,机器人先在零重力空间里学习,再在正常的重力环境中适应调控器。看似违反直觉,但单个控制器可以重新定向大量它以前从未见过的物体。
作者介绍:

Chen Tao, 麻省理工学院EECS & CSAIL 博士,师从Pulkit Agrawal教授。本科毕业于上海交通大学机械工程及自动化专业,期间在普渡大学机械工程学院交换。读研之前,Chen Tao曾是上海LX Robotics的研究工程师,从事目标检测、图像分割、机器人深度强化学习、SLAM等方面的研究。研究生毕业于卡内基梅隆大学机器人学院,师从Abhinav Gupta 教授。主要研究机器人学习、操作和导航的交叉领域 。
个人主页:https://taochenshh.github.io/

Jie Xu, 麻省理工学院CSAIL博士,师从计算设计和制造组(CDFG)的Wojciech Matusik教授。本科毕业于清华大学计算机科学与技术系。
研究主要方向机器人、仿真、机器学习的交叉领域。感兴趣的主题: 机器人控制、强化学习、基于可微分物理的仿真、机器人控制和设计协同优化、模拟现实。
个人主页:https://people.csail.mit.edu/jiex/
Pulkit Agrawal, 麻省理工学院EECS助理教授。所在实验室是计算机科学和人工智能实验室(CSAIL)的一部分,隶属于信息和决策系统实验室(LIDS),并与美国国家科学基金会人工智能和基本交互研究所(IAIFI)合作。
首要研究兴趣是构建能够自动且持续地了解其环境的机器。希望这种学习的最终结果将类似于人类所谓的常识的发展。Pulkit Agrawal将这方向的工作称为“计算感觉运动学习”,它包括计算机视觉、机器人技术、强化学习和其他基于学习的控制方法。个人主页:https://people.csail.mit.edu/pulkitag/哥伦比亚大学的《FlingBot: The Unreasonable Effectiveness of Dynamic Manipulation for Cloth Unfolding》论文链接:https://openreview.net/pdf?id=0QJeE5hkyFZ高速动态动作(如,乱扔或用力抛掷)通过提高自身效率和有效扩展物理接触范围,在我们与可变形物体的日常互动中发挥着至关重要的作用。但之前的大多数工作都是使用单臂准静态动作处理布料操作,这需要大量的交互来挑战初始布料配置,并严格限制机器人可及范围的最大布料尺寸。Huy Ha等人使用自监督学习框架FlingBot演示了布料展开动态投掷动作的有效性。这个方法从从视觉观察开始双臂设置,学习如何展开一块织物,从任意的初始配置使用拾取,拉伸,并投掷。最终系统在新布料上3个动作就能达到80%以上的覆盖范围,可以展开比系统覆盖范围更大的布料,虽然只在矩形布料上训练过,但可以推广到T恤上等。研究者们还在真实世界的双臂机器人平台上对FlingBot进行了微调。FlingBot的布料覆盖面积比准静态基线增加了4倍以上。FlingBot的简单性和它优于准静态基线的性能证明了动态动作对可变形物体操作是十分有效的。Huy Ha, 哥伦比亚大学计算机科学系博士。师从宋舒然教授,是哥伦比亚人大学工智能与机器人 (CAIR) 实验室的成员。个人主页:https://www.cs.columbia.edu/~huy/宋舒然, 目前是哥伦比亚大学计算机科学系的助理教授, 本科就读于香港科技大学计算机工程专业,硕士和博士均毕业于普林斯顿大学计算机科学系。研究重点是计算机视觉和机器人技术的交叉领域,研究兴趣是开发能使智能系统在与物理世界的交互中学习、并自主获得执行复杂任务和协助人们的感知和操纵技能的算法。个人主页:https://www.cs.columbia.edu/~shurans/- 达姆施塔特工业大学和华为英国研发中心合作的《Robot Reinforcement Learning on the Constraint Manifold》
论文链接:https://openreview.net/pdf?id=zwo1-MdMl1P作者:Puze Liu, Davide Tateo, Haitham Bou-Ammar and Jan Peters许多实际问题,像安全、机械约束和磨损等,在机器人技术中运用强化学习十分具有挑战性。这些问题通常在机器人学习文献中没有被充分考虑到。在现实中应用强化学习的关键点在于安全探索,在整个学习过程中满足物理和安全约束至关重要。要在这样的安全环境中探索,利用诸如机器人模型和约束条件等已知信息,能更好地提供强有力的安全保障。Puze Liu等人提出了一种在模拟中能有效学习机器人任务的方法,能满足学习过程中需要的约束条件。研究提出了作用于约束流形的切线空间新方法(ATACOM),智能体探索约束流形的切线空间,如图中所示。它可以将约束强化学习问题转化为典型的无约束强化学习问题。这个方法可以让我们利用任何无模型 RL算法,同时能让约束保持在容差以下。ATACOM 的优点可以概括如下:(i) 它可以处理等式和不等式约束。每个时间步的所有约束都保持在容差以下。(ii) 不需要初始可行的策略,智能体可以从零开始学习。(iii) 不需要手动安全备份策略将系统移回安全区域。(iv)它可以应用于任何使用确定性和随机策略的无模型强化学习算法。(v) 探索可以集中在低维流形上,而不是探索原始动作空间中的等式约束。(vi) 它具有更好的学习性能,因为不等式约束仅限于较小的可行状态-动作空间。- 卡内基梅隆大学的《Learning Off-Policy with Online Planning》
论文链接:https://openreview.net/pdf?id=1GNV9SW95eJ作者:Harshit Sikchi, Wenxuan Zhou, David Held低数据和风险敏感领域中的强化学习需要灵活高性能的部署策略,这些策略可以在部署过程中轻松整合约束。一类是半参数H步前瞻策略,它使用轨迹优化对具有终值函数的固定范围的动态模型进行轨迹优化选择动作。在这项工作中,Harshit Sikchi等人研究了一种新的 H步前瞻实例化,其中包含一个学习模型和一个由无模型离策略算法学习的终端值函数,名为 Learning Off-Policy with Online Planning (LOOP)。理论分析建议模型误差和值函数误差之间进行权衡,从经验而言这种权衡有利于深度强化学习。这篇论文还确定了该框架中的“Actor Divergence”问题,提出Actor 正则化控制 (ARC),这是一种改进的轨迹优化程序。研究人员在一组用于离线和在线强化学习机器人任务上评估LOOP。LOOP 在部署期间展示了将安全约束与导航环境结合起来的灵活性。由此证明 LOOP 是一个理想的机器人应用框架,基于它在各种重要的强化设置中的强大性能。- 斯坦福大学、谷歌机器人和加州大学伯克利分校合作的《XIRL: Cross-embodiment Inverse Reinforcement Learning》
论文链接:https://openreview.net/pdf?id=RO4DM85Z4P7作者:Kevin Zakka, Andy Zeng, Pete Florence, Jonathan Tompson, Jeannette Bohg, Debidatta Dwibedi本文研究了视觉跨实体模仿设置,其中智能体从其他智能体(例如人类)的视频中学习策略,演示相同的任务,但他们在实施中存有明显差异——形状、动作、末端效应器动力学等。本文证明了从对差异具有鲁棒性的跨实体演示视频中自动发现和学习基于视觉的奖励函数。通过提出跨实体逆强化学习 (XIRL) 的自监督学习,利用时间周期一致性约束来学习深度视觉嵌入,这些嵌入可以从多个专家代理的离线演示视频中捕获任务进展,每个智能体执行相同的任务因具体化而不同。此前,从自监督嵌入产生奖励通常需要与参考轨迹对齐,在实施差异下可是很难获得的。如果嵌入了解任务进度,在学习的嵌入空间中简单地取当前状态和目标状态之间的负距离作为强化学习训练策略的奖励是有作用的。研究证明学习奖励函数不仅适用训练期间看到的实施例,更可以推广到全新的实施例。此外,当将真实世界的人类演示转移到模拟机器人时,研究发现XIRL比当前的最佳方法更有效果。- 华盛顿大学和伟英达公司合作的《SORNet: Spatial Object-Centric Representations for Sequential Manipulation》
论文链接:https://openreview.net/pdf?id=mOLu2rODIJF作者:Wentao Yuan, Chris Paxton, Karthik Desingh顺序操作任务要求机器人感知环境状态,并计划一系列行动以达到预期的目标状态,其中从原始传感器输入推断对象实体之间空间关系的能力至关重要。之前的工作依赖于明确的状态估测,对新任务和对象端到端地学习对抗。在这项工作中,Wentao Yuan等人提出了SORNet(空间对象中心表示网络),它从以兴趣对象的规范视图为条件的RGB 图像中提取以对象为中心的表示。结果表明,在空间关系分类、技能前提分类和相对方向回归三种空间推理任务中,通过SORNet学习的对象嵌入方法可以将零样本扩展到未见的对象实体,并显著优于基线。此外,我们进行了真实世界的机器人实验,证明了学习对象嵌入在顺序操作任务规划中的使用。- 华盛顿大学和谷歌机器人合作的《Fast and Efficient Locomotion via Learned Gait Transitions》
论文链接:https://openreview.net/pdf?id=vm8Hr9YJHZ1作者:Yuxiang Yang, Tingnan Zhang, Erwin Coumans, Jie Tan, and Byron Boots本文主要研究四足机器人节能控制器的研制问题。动物可以用不同的速度主动切换步态,以降低能量消耗。在本文中,Yuxiang Yang等人设计了一个层次学习框架,在这个框架中,独特的运动步态和自然的步态转换以能量最小化奖励自动出现。研究人员使用进化策略(ES)训练高级步态策略,指定每只脚的步态模式,而低水平凸MPC控制器优化电机命令,使机器人可以用期望步态模式的速度行走。在一个四足机器人上测试了这个学习框架,演示了随着机器人速度的增加,从步行到小跑再到飞小跑的自动步态转换。结果表明,学习层次控制器消耗的能量远少于基线控制器在大范围的运动速度。CoRL(Conference on Robot Learning/ 机器人学习大会),是一个以机器人和机器学习为主的学术会议。我们AI科技评论曾对CoRL会议做过详细的介绍:机器人学习大会CoRL 2020 最佳论文出炉!华为诺亚、上海交大获最佳系统论文奖在CoRL官网,组委会这样描述举办CoRL的缘由:CoRL是一个新的以机器人学和机器学习为主题的年度国际会议。第一次会议已于2017年11月13日至15日在加利福尼亚州山景城举行,旨在汇聚约250名从事机器人学和机器学习领域的最优秀的研究者参会。机器人技术,自主感知和控制领域正在经历一场机器学习革命,现在正是时候提供一个将机器学习的基本进展与机器人应用和理论的实证研究相结合的场所。我们的目标是使CoRL成为机器人(机器)学习研究的首选大会。
大会的组织者包括来自UC Berkrley、Google、Microsoft、CMU、MIT、ETH、Deepmind等知名院校和知名企业的研究者和从业者,同时CoRL大会的举办还得到了机器人国际机构“三巨头”之一的国际机器人研究基金会(IFRR)和机器学习领域最好的期刊之一JMLR(Journal of Machine Learning Research)的支持。机器人学习大会(CoRL)自2017年推出以来,已迅速成为机器人技术与机器学习交叉领域的全球顶级学术盛会之一:“针对机器人学习研究的大会,涵盖了机器人技术、机器学习和控制等广泛主题,包括理论和应用各方面。”













