
使用PyTorch实现对花朵的分类
PyTorch是一个非常适合初学者的高度可靠且强大的机器学习库。自2016年10月以来,它已经开源并由Facebook维护,并被开发人员用于研究其原型,以部署最先进的深度学习应用程序。与TensorFlow等其他机器学习库相比,PyTorch更加直观,并具有实现模型的Python方式。
 决定要分类什么?
决定要分类什么?
识别花朵的类型需要某种形式关于花朵的知识,人必须事先看过花朵才能识别花朵。同样,对于计算机,很难对算法进行硬编码以识别花朵的类型。到目前为止,机器学习是从给定的大量花朵图片中识别花朵名称的唯一选择。这使得使用深度学习实现花识别任务对于每个初学者来说都非常有趣。

花朵识别数据集对于像我这样的初学者而言,是一个很好的数据集,可用于实施和练习各种机器学习模型。
使用什么数据集?
我们将使用Kaggle上可用的花朵识别数据集。数据集链接:https ://www.kaggle.com/alxmamaev/flowers-recognition
预处理数据集
我们将使用神经网络对花朵进行分类。神经网络是深度学习的一种形式,最适合当今的图像分类。我们首先导入所有需要的模块以运行我们的代码。
import numpy as np # linear algebraimport pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)import osimport torchimport torchvisionfrom torchvision.datasets.utils import download_urlfrom torch.utils.data import random_splitfrom torchvision.datasets import ImageFolderfrom torchvision import transformsfrom torchvision.transforms import ToTensorfrom torch.utils.data.dataloader import DataLoaderimport torch.nn as nnimport torch.nn.functional as F
我们导入了PyTorch的组件以及NumPy和Pandas等数据科学库。图片是非结构化数据,为了将其输入到我们的深度学习模型中,我们必须将其转换为张量。我们需要对图像进行预处理,然后才能为模型做好准备。我们首先使用ImageFolder 存在于torchvision.datasets 来准备数据集。ImageFolder是一个非常有用的工具当图像存储在不同的文件夹中,其中每个文件夹都充当类名。PyTorch还具有其他更简单的准备数据集的方式,我们可以在其中准备自己的自定义数据集。
transformer = torchvision.transforms.Compose([ # Applying Augmentationtorchvision.transforms.Resize((224, 224)),torchvision.transforms.RandomHorizontalFlip(p=0.5),torchvision.transforms.RandomVerticalFlip(p=0.5),torchvision.transforms.RandomRotation(30),torchvision.transforms.ToTensor(),torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])dataset = ImageFolder(base_dir, transform=transformer)
我们还习惯于transforms.Compose将图像转换为张量并应用其他图像增强技术。此外,在将各种图像加载到数据集时,请阅读各种变换技术并应用于图像。我们应该使用程序加载图像,以便可以每次分批添加数据集,并且可以优化效率。
定义模型
我们可以使用从PyTorch类继承的类来定义深度学习模型的框架 nn.Module.
def accuracy(outputs, labels): _, preds = torch.max(outputs, dim=1)return torch.tensor(torch.sum(preds == labels).item() / len(preds))class ImageClassificationModel(nn.Module):def training_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossreturn lossdef __init__(self):super().__init__()self.network = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2), # output: 64 x 16 x 16nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2), # output: 128 x 8 x 8nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2), # output: 256 x 4 x 4nn.Flatten(),nn.Linear(256*28*28, 1024),nn.ReLU(),nn.Linear(1024, 512),nn.ReLU(),nn.Linear(512, 5))def forward(self, xb):return self.network(xb)def validation_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossacc = accuracy(out, labels) # Calculate accuracyreturn {'val_loss': loss.detach(), 'val_acc': acc}def validation_epoch_end(self, outputs):batch_losses = [x['val_loss'] for x in outputs]epoch_loss = torch.stack(batch_losses).mean() # Combine lossesbatch_accs = [x['val_acc'] for x in outputs]epoch_acc = torch.stack(batch_accs).mean() # Combine accuraciesreturn {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}def epoch_end(self, epoch, result):print("Epoch [{}], train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(epoch, result['train_loss'], result['val_loss'], result['val_ac']))
训练模型
首先训练模型,让我们将超参数设置为:
num_epochs = 10opt_func = torch.optim.Adamlr = 0.001
现在,在将模型运行10个epoach后,我们可以看到使用基本的卷积神经网络(CNN)模型达到了约65%。
测试模型
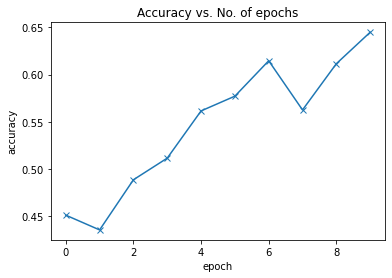
65%是一个很好的结果,因为我以前曾尝试过使用带有一些隐藏层的简单神经网络(NN),结果仅为40%左右。因此,CNN非常适合对图像进行分类,因为它们有比其他形式的机器学习更好的检测模式。
使用转移学习
现在让我们再次尝试使用已经定义的模型(如Resnet-18)进行转移学习,以改善模型的预测。使用相同的超参数集,我们的测试集中可以达到82%左右,这是非常令人印象深刻的。如果我们使用其他更好的CNN架构,例如Resnet50,Inception V3等,则可以进一步改善结果。
plot_accuracies(history)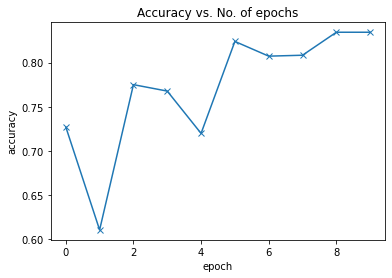
保存模型
训练完成后,我们必须保存我们的模型,以便我们可以使用它来根据模型生成预测,甚至将来可以进行更多训练。
weights_fname = 'flower-resnet.pth'torch.save(model.state_dict(), weights_fname)
产生预测
每个机器学习周期的目标是创建一个可被用于对常规数据进行分类的模型。这可以通过几行python代码为最终用户实现模型。
def predict_image(img, model):# Convert to a batch of 1xb = to_device(img.unsqueeze(0), device)# Get predictions from modelyb = model(xb)# Pick index with highest probability_, preds = torch.max(yb, dim=1)# Retrieve the class labelreturn dataset.classes[preds[0].item()]img, label = test_ds[2]plt.imshow(img.permute(1, 2, 0))print('Label:', dataset.classes[label], ', Predicted:', predict_image(img, model))Label: sunflower , Predicted: sunflower

我们还可以使用服务器上的模型来识别花朵的类型。该模型可以轻松部署在服务器上,以供最终用户识别不同类型的花朵。
· END ·