
解析 Vision Transformer
【GiantPandaCV导语】Vision Transformer将CV和NLP领域知识结合起来,对原始图片进行分块,展平成序列,输入进原始Transformer模型的编码器Encoder部分,最后接入一个全连接层对图片进行分类。在大型数据集上表现超过了当前SOTA模型
前言
当前Transformer模型被大量应用在NLP自然语言处理当中,而在计算机视觉领域,Transformer的注意力机制attention也被广泛应用,比如Se模块,CBAM模块等等注意力模块,这些注意力模块能够帮助提升网络性能。而我们的工作展示了不需要依赖CNN的结构,也可以在图像分类任务上达到很好的效果,并且也十分适合用于迁移学习。
这里的代码引用自 https://github.com/lucidrains/vit-pytorch,大家有兴趣也可以跑跑demo。
方法
首先结构上,我们采取的是原始Transformer模型,方便开箱即用。
如果对Transformer模型不太了解的可以参考这篇文章 解析Transformer模型
整体结构如下
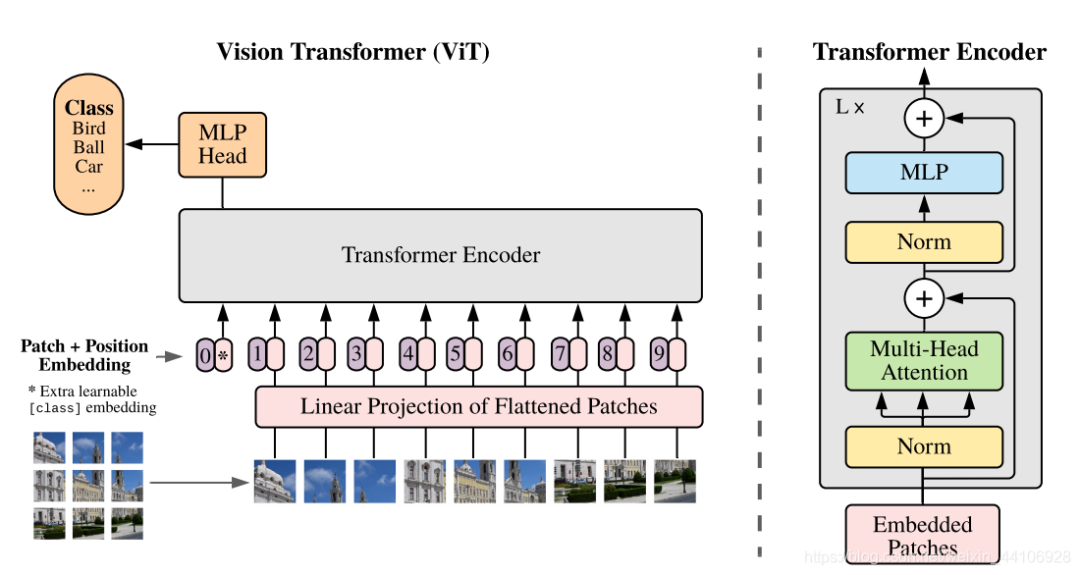
数据处理部分
原始输入的图片数据是 H x W x C,我们先对图片作分块,再进行展平。假设每个块的长宽为(P, P),那么分块的数目为
然后对每个图片块展平成一维向量,每个向量大小为
总的输入变换为
这里的代码如下:
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=p, p2=p)
它使用的是一个einops的拓展包,完成了上述的变换工作
Patch Embedding
接着对每个向量都做一个线性变换(即全连接层),压缩维度为D,这里我们称其为 Patch Embedding。
在代码里是初始化一个全连接层,输出维度为dim,然后将分块后的数据输入
self.patch_to_embedding = nn.Linear(patch_dim, dim)
# forward前向代码
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=p, p2=p)
x = self.patch_to_embedding(x)
Positional Encoding
还记得在解析Transformer那篇文章内有说过,原始的Transformer引入了一个 Positional encoding 来加入序列的位置信息,同样在这里也引入了pos_embedding,是用一个可训练的变量替代。
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
文章也提供了可视化图

很有意思的是这里第二个维度多加了个1。下面会有讲到
class_token
这里我们再来仔细看上图的一个结构

假设我们按照论文切成了9块,但是在输入的时候变成了10个向量。这是人为增加的一个向量。
因为传统的Transformer采取的是类似seq2seq编解码的结构
而ViT只用到了Encoder编码器结构,缺少了解码的过程,假设你9个向量经过编码器之后,你该选择哪一个向量进入到最后的分类头呢?因此这里作者给了额外的一个用于分类的向量,与输入进行拼接。同样这是一个可学习的变量。
具体操作如下
# 假设dim=128,这里shape为(1, 1, 128)
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
# forward前向代码
# 假设batchsize=10,这里shape为(10, 1, 128)
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b)
# 跟前面的分块为x(10,64, 128)的进行concat
# 得到(10, 65, 128)向量
x = torch.cat((cls_tokens, x), dim=1)
知道这个操作,我们也就能明白为什么前面的pos_embedding的第一维也要加1了,后续将pos_embedding也加入到x
x += self.pos_embedding[:, :(n + 1)]
分类
分类头很简单,加入了LayerNorm和两层全连接层实现的,采用的是GELU激活函数。代码如下
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, mlp_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(mlp_dim, num_classes)
)
最终分类我们只取第一个,也就是用于分类的token,输入到分类头里,得到最后的分类结果
self.to_cls_token = nn.Identity()
# forward前向部分
x = self.transformer(x, mask)
x = self.to_cls_token(x[:, 0])
return self.mlp_head(x)
可以看到整个流程是非常简单的,下面是ViT的整体代码
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, channels=3, dropout=0.,
emb_dropout=0.):
super().__init__()
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_size // patch_size) ** 2
patch_dim = channels * patch_size ** 2
assert num_patches > MIN_NUM_PATCHES, f'your number of patches ({num_patches}) is way too small for attention to be effective (at least 16). Try decreasing your patch size'
self.patch_size = patch_size
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.patch_to_embedding = nn.Linear(patch_dim, dim)
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, mlp_dim, dropout)
self.to_cls_token = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, mlp_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(mlp_dim, num_classes)
)
def forward(self, img, mask=None):
p = self.patch_size
x = self.patch_to_embedding(x)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x, mask)
x = self.to_cls_token(x[:, 0])
return self.mlp_head(x)
实验部分
与Transformer一样,ViT也有规模不一样的模型设置,如下图所示
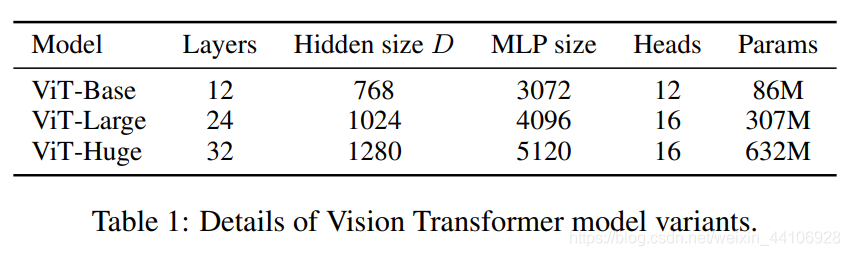
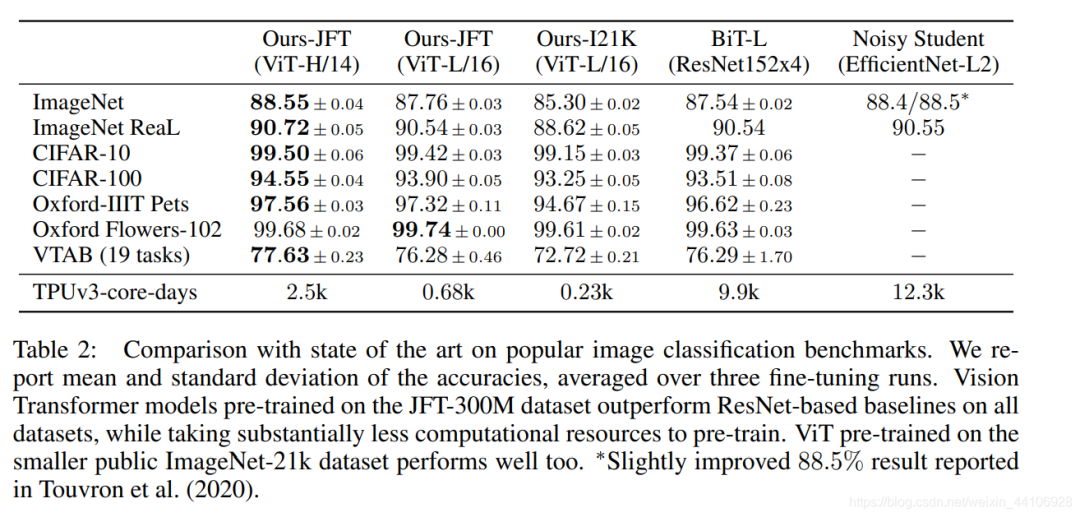
可以看到整体模型还是挺大的,而经过大数据集的预训练后,性能也超过了当前CNN的一些SOTA结果
另外作者还给了注意力观察得到的图片块,我的一点猜想是可能有利于对神经网络可解释性的研究。

总结
继DETR后,这又是一个CV和NLP结合的工作。思想非常的朴素简单,就是拿最原始的Transformer模型来做图像分类。现有的性能还需要大量的数据来训练,期待后续工作对ViT做一些改进,降低其训练时间和所需数据量,让人人都能玩得起ViT!
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。