
清华大学刘知远组:文本分类任务中,将知识融入Prompt-tuning过程
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
前两天看到刘知远老师组在 arxiv 上放出来了 Prompt-tuning 相关的新工作,这篇文章是将外部知识融入 Prompt-tuning 过程的一个尝试,引起了我的兴趣。于是,我在拜读了这篇文章之后,写成本文做一个简单总结。

论文标题:
Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification
论文作者:
Shengding Hu, Ning Ding, Huadong Wang, Zhiyuan Liu, Juanzi Li, Maosong Sun
论文链接:
https://arxiv.org/abs/2108.02035

Main Idea & Motivation
之前的 Prompt-tuning 方法可被用于文本分类任务,具体方式是通过构建标签词表,将分类问题转化为一个预测和标签相关词的问题。因此,这样的问题可以构建一个含有 [MASK] 的模板,然后让 MLM(掩码语言模型)去预测 [MASK] 位置的单词。至此,分类任务被转化为了一个掩码语言建模问题。
下面给出一个例子,当我们要对一个句子进行分类时,可以尝试构建下面的模板:
A [MASK] question: x
比如 MLM 预测出在 [MASK] 位置概率最高的词是 science,那该句可以被分类为 SCIENCE 类别。
然而我们很快就认识到,MLM 在 [MASK] 位置可以预测出的单词是很多的,然而类别数只有特定数量的,因此该问题很重要的一个部分是如何构建一个单词表到类别标签的映射。这个映射能让 MLM 在预测到类别标签的相关词时,就可以被分到指定类别去。
这样的一个映射,通常是由人来手工编辑或使用梯度下降搜索。但显然这样会带来覆盖范围不全导致的高偏差和高方差。知识库的组织结构,天然的带有范围关系,在知识库的图结构中,相关联的实体会有边相连,不相关的实体可能要经过很多跳才能找到关联,或无关联。因此如果能将外部的知识库信息融入,构建一个映射器(本文称语言表达器),就可以一定程度上避免手工构造和梯度下降带来的高偏差和高方差问题。


Method
KPT 旨在构建一个语言表达器,在单词空间和分类标签空间做一个映射。
因此 KPT 包含以下三个步骤:
标签词的扩展
扩展标签词的去噪
语言表达器的使用
下图展示了 KPT 的整体流程:
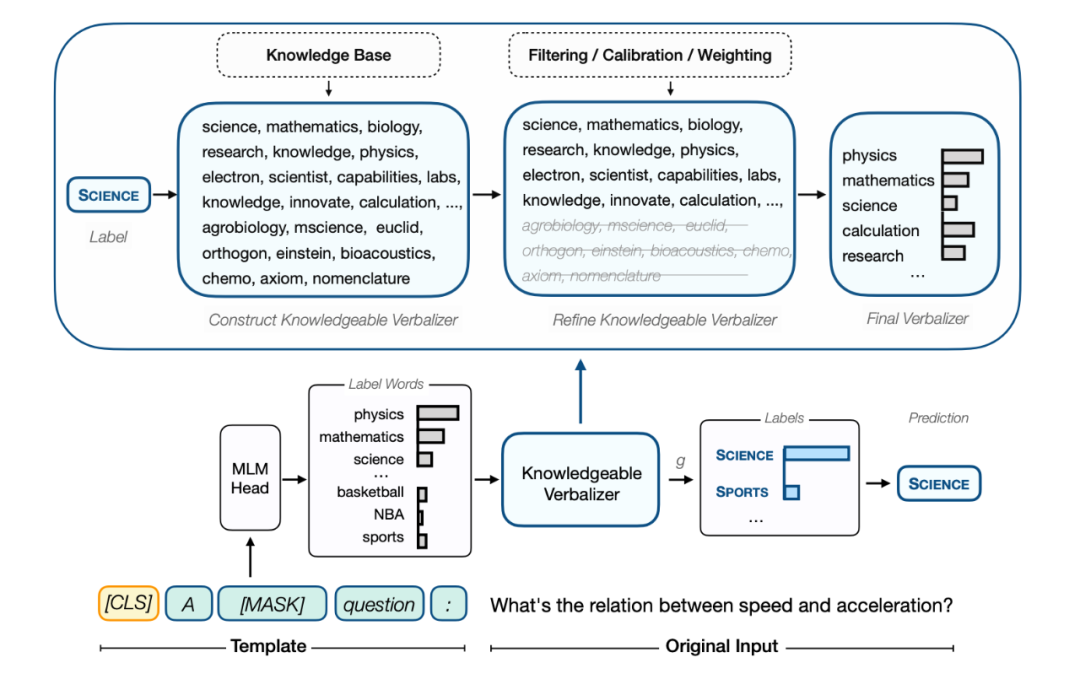
▲ KPT的结构示意图,包含语言表示器的构建、修正、使用三个阶段
3.2 扩展标签词的去噪
因此本文主要集中在数据不充分情况下的扩展标签词的去噪,也即无标注数据 zero-shot 场景和少量标注数据 few-shot 场景。
3.2.1 对于 zero-shot 场景
需要解决三个问题:
1. 知识库中得到的扩展词,并不在 PLM 的单词空间中(out-of-vocabulary);
2. PLM 中的稀有词,概率预测往往不准确;
3. 标签词的先验分布具有巨大的偏差。
对于第 1 个问题:
本文简单的将词拆分成逐 token 的多个部分,并用 PLM 逐 token 预测的平均概率,作为整个词的概率。
对于第 2 个问题:
对于一些稀有词,PLM 预测的概率不准确(其实是不稳定),且有偏差,因此,最好在扩展单词表中删去这些稀有词。然而,我们应该如何确定哪些是稀有词呢?本文使用 MLM 去预测句子上下文中这个单词的概率。
也即我们要预测的是下面这个概率的期望:
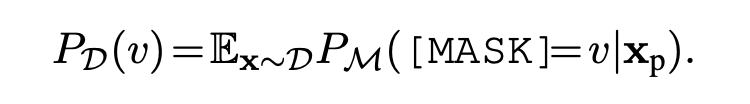
然而我们无法直接得到这个期望,只能用在上下文中预测的频率去估计,也即,使用这样一个近似:
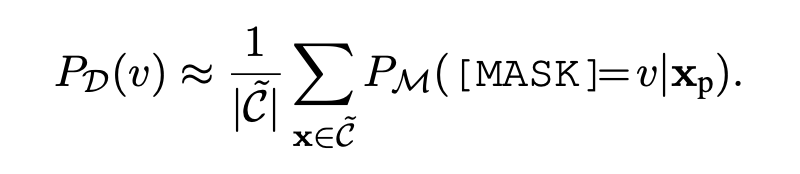
也即在上下文中用 PLM 去预测这个单词,有人可能会问,这不是zero-shot嘛,哪里来的数据上下文让你训练呢?
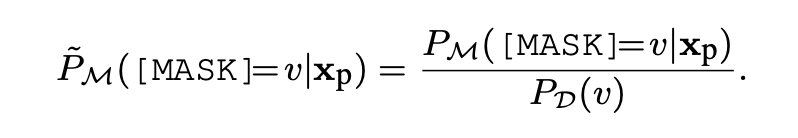
这个先验分布仍然和 2 一样,是使用少量无标注数据得到的。
3.2.2 对于 few-shot 场景
在 few-shot 中,因为有少量的标注数据,所以去噪更容易。
对于每个标签词,我们为其分配一个可学习的权重参数,然后再将其归一化,得到:
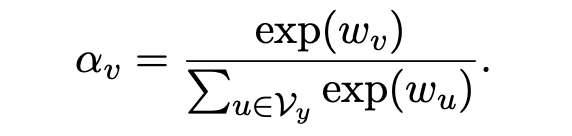
在 few-shot 情况下,我们不需要进行校准,因为训练过程中这个参数会被训练到所需的范围。
3.3 语言表达器的使用
3.3.1 在 zero-shot 情况下
我们简单地认为扩展词中每个词对于预测标签的贡献相同,因此我们对其进行简单平均,并用预测分数的均值作为该标签的预测分数,最后取出预测分数最大的类别,作为最后的结果。
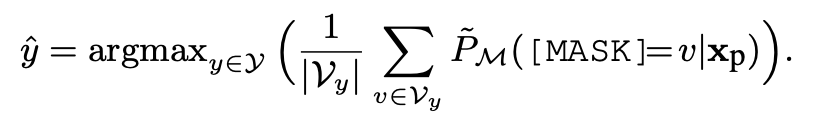
其中:
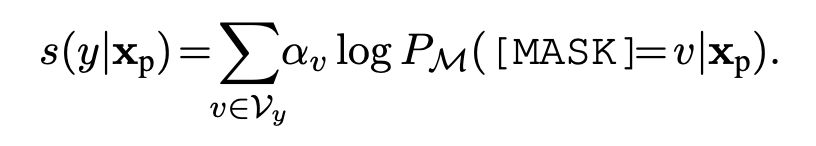

Experiment

然后对比实验包括:
Prompt-tuning (PT) Prompt-tuning + Contextualized Calibration(PT + CC) Fine-tuning (FT)
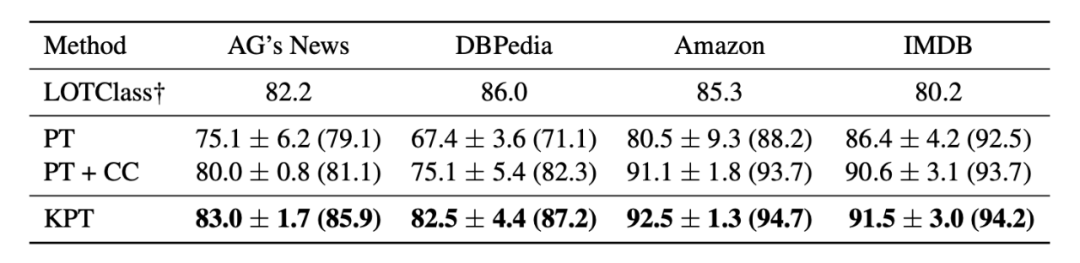
▲ zero-shot实验结果
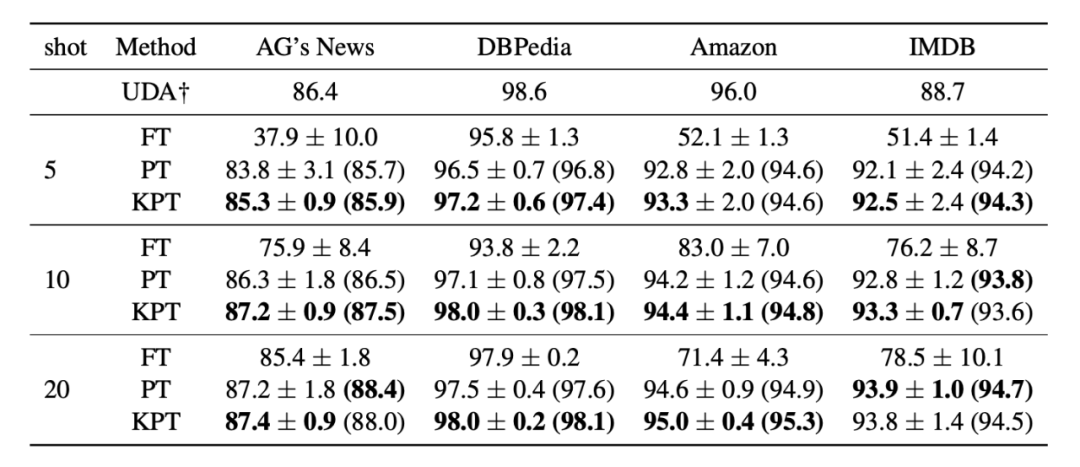
▲ few-shot实验结果
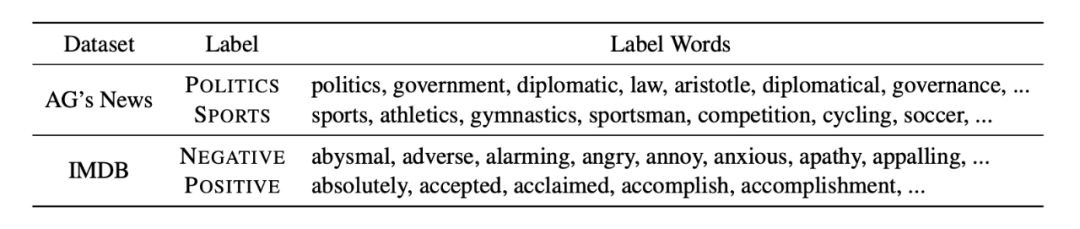
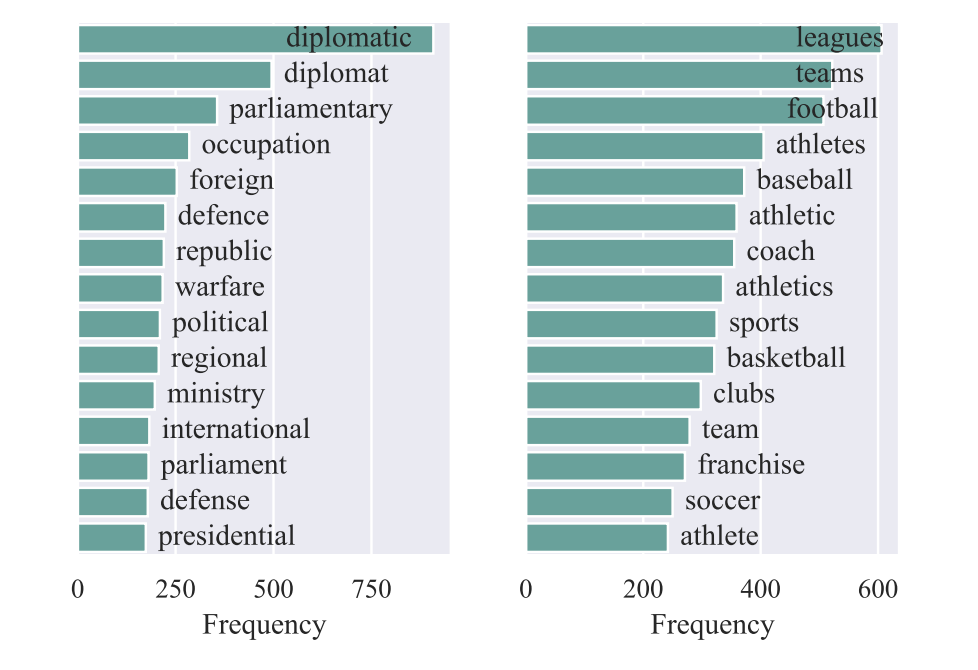
KPT 方法的其中一个显著优点是,由于引入了外部知识,因此生成的标签扩展词,是多粒度、多角度的。下图展示了一个示例:

Conclusion
未来的工作中,仍然有与本文研究相关的开放性问题。
1. 在语言表达器中选择信息丰富的标签词的复杂方法;
2. 在模板构建和语言表达器设计方面结合知识库和 Prompt-tuning 的更好方法;
3. 将外部知识结合到文本生成等其他任务的 Prompt-tuning 方法。我们期待这个方向有更多新颖的工作。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
编辑:PaperWeekly

点个在看 paper不断!