
ACL2022 | KPT: 文本分类中融入知识的Prompt Verbalizer

来源:TsinghuaNLP、深度学习自然语言处理 本文约2400字,建议阅读5分钟
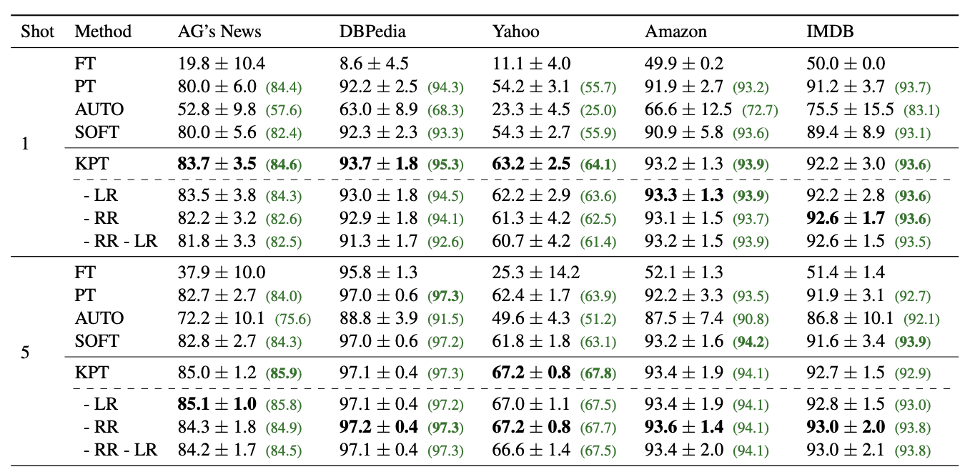
本文使用了知识库来进行标签词的扩展和改善,取得了更好的文本分类效果。

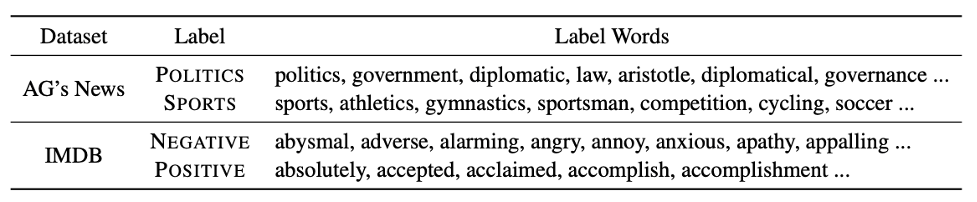
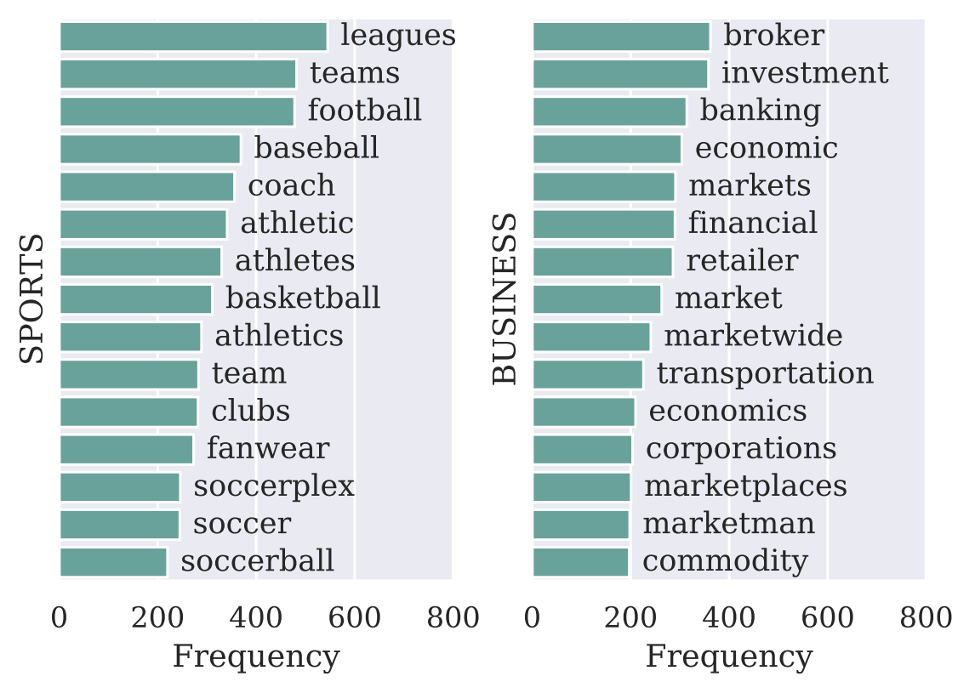
表1: 基于知识库扩展出的标签词。
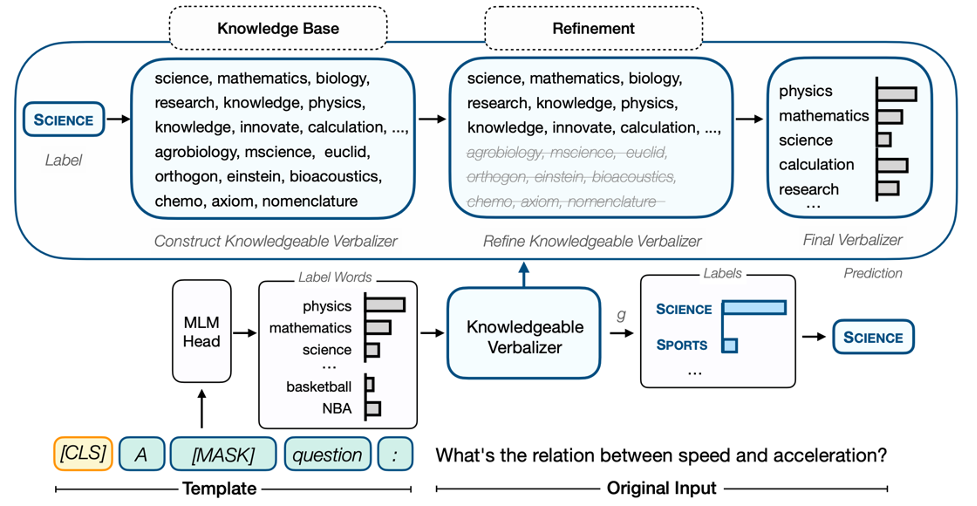
01、频率精调
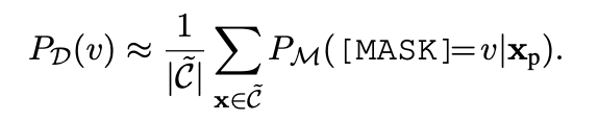
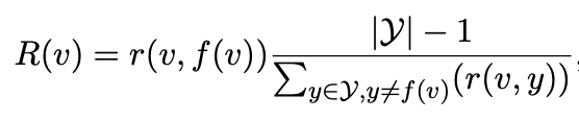
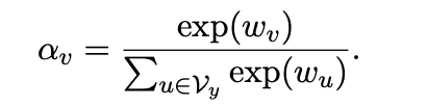
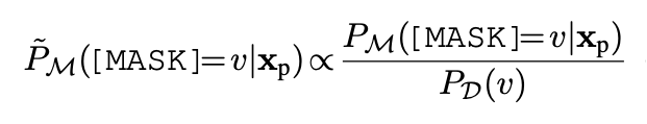

论文链接:
https://arxiv.org/abs/2108.02035
代码地址:
https://github.com/thunlp/KnowledgeablePromptTuning
编辑:于腾凯
评论