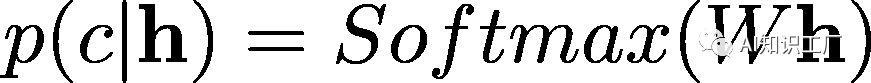问 题
问 题
BERT在许多自然语言理解(NLU)任务中取得了惊人的成果,但它的潜力还有待充分挖掘。目前很少有如何能进一步提高BERT性能的研究,因此,如何通过一些技巧和方法最大限度的提升BERT在文本分类任务中的性能是此次研究的重点。 目 标在使用BERT做 text classification的时候,我们利用[CLS]的hidden state输出做为整个输入文本的representation,通过一层task specific层(通常是Linear Layer),再经过Softmax层得到概率,输出概率如下所示,其中的
目 标在使用BERT做 text classification的时候,我们利用[CLS]的hidden state输出做为整个输入文本的representation,通过一层task specific层(通常是Linear Layer),再经过Softmax层得到概率,输出概率如下所示,其中的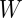 是task specific层的参数,最后通过最大化log-probability of correct label优化模型参数。
是task specific层的参数,最后通过最大化log-probability of correct label优化模型参数。 方 法
方 法How to Fine-Tune BERT for Text Classification?[1]这篇论文从四个方面对BERT(BERT base)进行不同形式的pretrain和fine-tune,并通过实验展示不同形式的pretrain和fine-tune之间的效果对比。
当我们在特定任务上fine-tune BERT的时候,往往会有多种方法利用Bert,举个例子:BERT的不同层往往代表着对不同语义或者语法特征的提取,并且对于不同的任务,不同层表现出来的重要性和效果往往不太一样。因此如何利用类似于这些信息,以及如何选择一个最优的优化策略和学习率将会影响最终fine-tune 的效果。
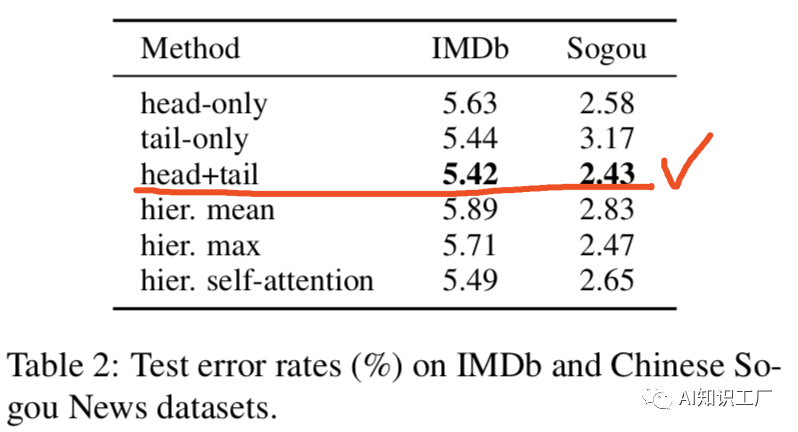
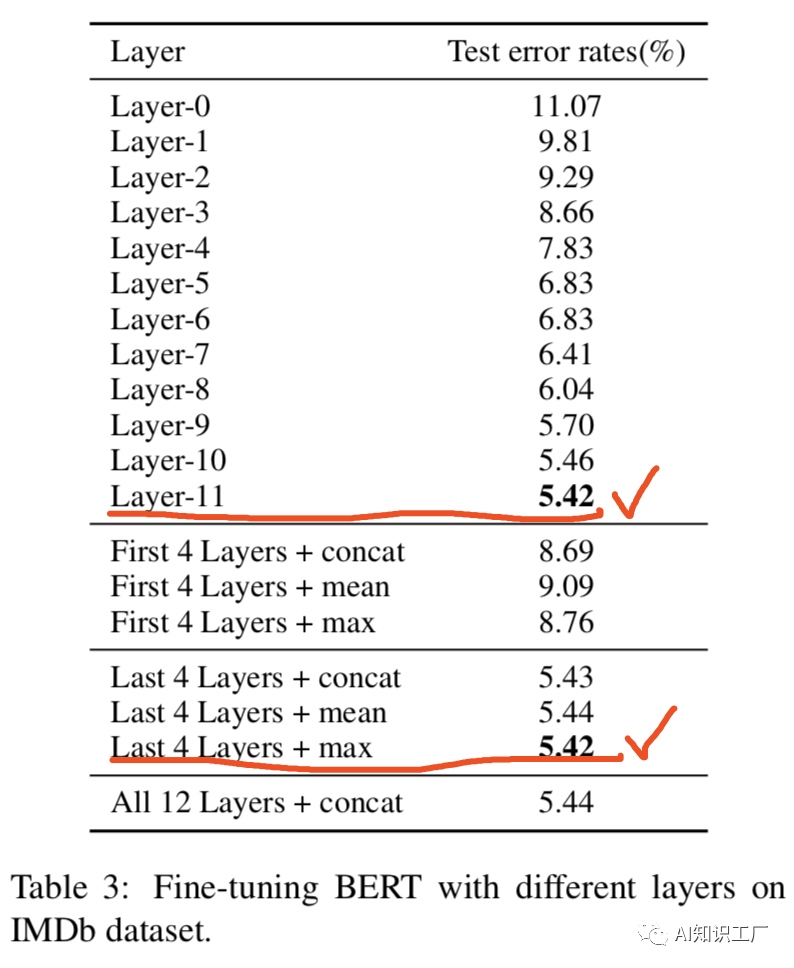
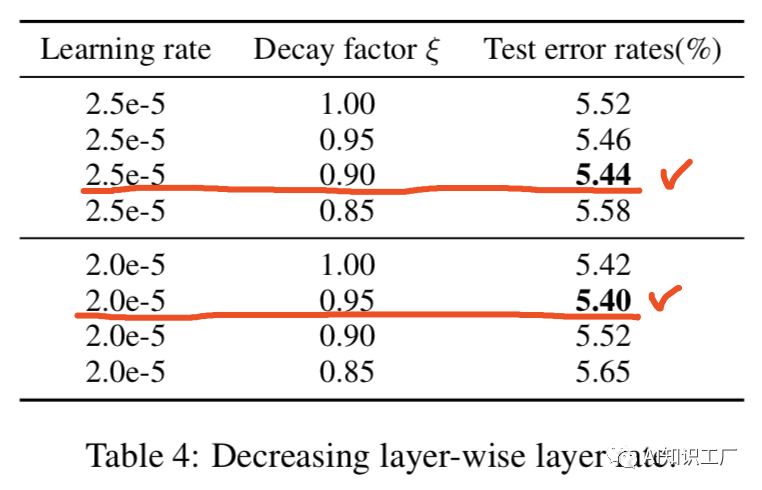
1.保留头部(head-only):保留头部最开始的510个tokens2.保留尾部(tail-only):保留尾部最后的510个tokens3.头部加尾部(head+tail):头部128+尾部382首先将输入文本(长度为L)分成k = L/510个小段落,将它们依次输入BERT得到k个文本段落的表示。每个段落的representation是最后一层[CLS]的hidden state,并分别使用mean pooling, max pooling and self-attention来合并所有段落的representation。上述两种处理方法在IMDb和Chinese Sougou News datasets上的实验效果如下所示,实验结果表明,采取head+tail的方式处理长文本更具优势。BERT的每一层捕获输入文本的不同特性,Table 3显示了在不同层Fine-tune BERT时performance的对比。实验结果表明,BERT的最后一层更能表征下游任务(Layer-11表示fit前12层),在对其进行Fine-tune时效果也是最好的。通常BERT模型的低层包含更general的信息,而靠近顶部的层偏向于学习下游任务的相关知识,因此可以在顶层赋予较大的学习率,越往低层学习率越小。因此,我们的策略如公式(1)所示,其中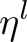 代表第l层的学习率,我们设定base learning rate为
代表第l层的学习率,我们设定base learning rate为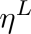 ,代表顶层的学习率,其他层的策略如公式(2)所示,其中
,代表顶层的学习率,其他层的策略如公式(2)所示,其中 是衰减系数,如果
是衰减系数,如果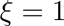 ,那么每层的学习率是一样的,如果
,那么每层的学习率是一样的,如果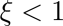 ,那么越往下的层学习率就越低。
,那么越往下的层学习率就越低。 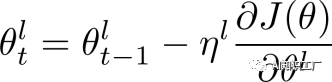 (1)
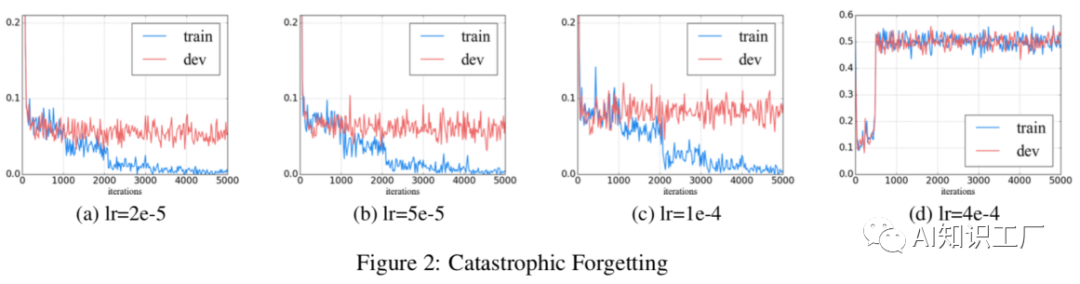
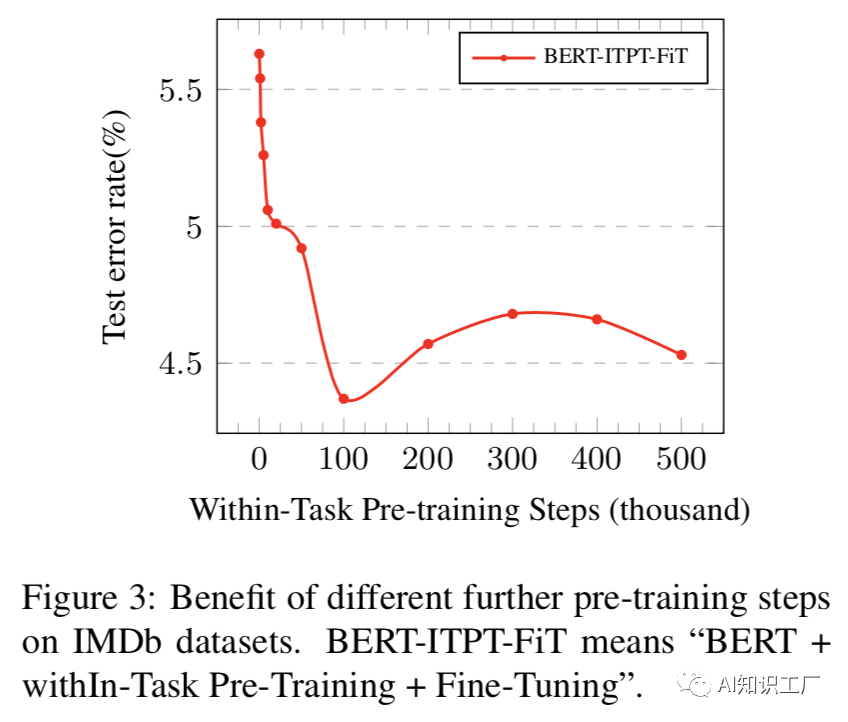
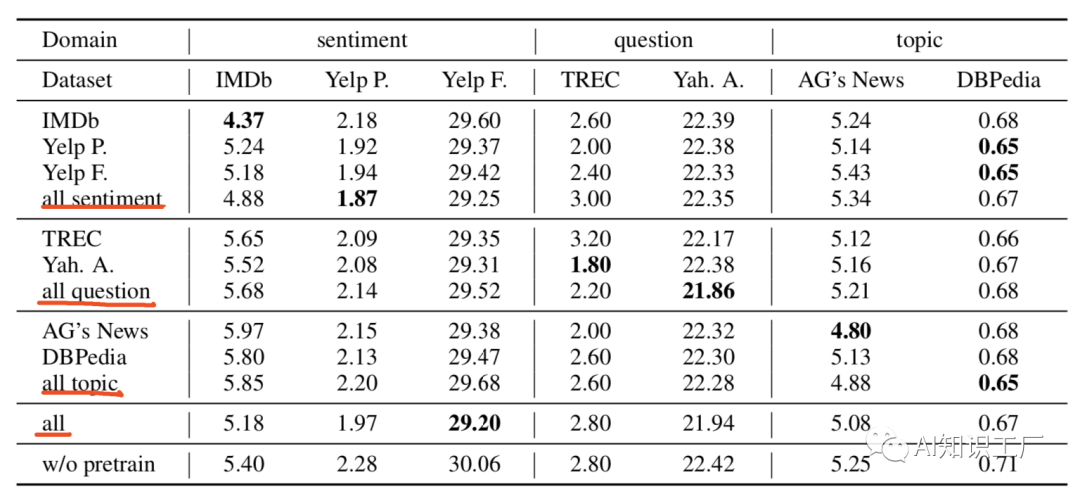
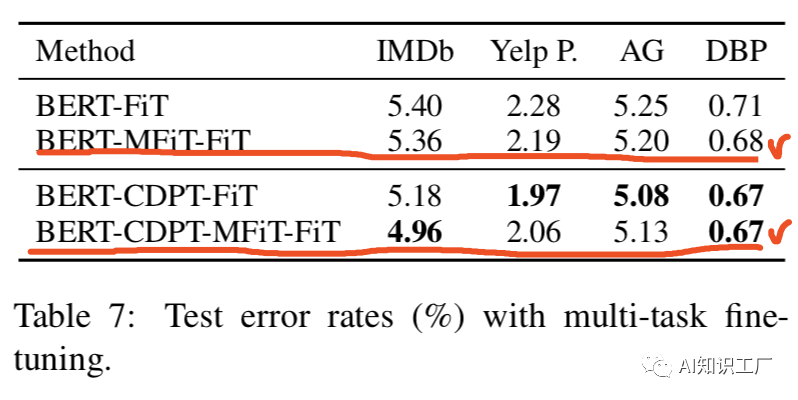
(1) 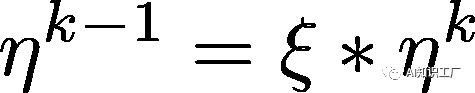 (2)灾难性遗忘(Catastrophic forgetting)是transfer learning中常见的问题,即在学习新知识的过程中,预训练的知识有可能被遗忘或者抹去。因此,本文探讨了BERT是否也存在这种灾难性遗忘问题。如下图所示,当采用较低的学习率时(文中采用2e-5),BERT在训练的过程中能够克服灾难性遗忘问题,而当学习率较大时(文中采用4e-4),就会失去这种能力。BERT预训练模型是在通用领域(General Domain)上做的Training,很自然的一个想法就是在目标域(Target Domain)进一步pretrain。任务内(within-task)pretrain是指在任务域(通常指具体的任务,比如某一金融细分领域的文本分类任务)上对模型进行预训练,预训练的方式仍然是unsupervised masked language model and next sentence prediction tasks,实验结果表明,任务内领域的预训练可以提升模型的效果,但在进一步预训练时需要注意training step,否则效果会变差。In-Domain指的是某一领域内数据,比如金融领域、计算机领域等等,该领域的数据分布往往和任务内数据分布相似,这里的Cross-Domain在内容上可以理解为通用领域,作者通过实验证明领域内(In-Domain)和任务内(Within-Task)的pretrain效果都会有提升,且通常情况下领域内的pretrain效果要好于任务内的pretrain效果,但在交叉域(或者说通用领域)上没什么提升,理由是BERT预训练本身就是在通用领域上训练的。实验结果对比如下图所示,all sentiment/question/topic代表In-Domain pretrain,all代表 Cross-Domain,w/o pretrain代表原始的BERT base 模型。在多任务数据域(比如多个文本分类的数据集,这样做的目的是为了充分利用已有的分类任务数据)上做pretrain,然后在target-domain上进行fine-tune,也会提升模型的效果。其中,
(2)灾难性遗忘(Catastrophic forgetting)是transfer learning中常见的问题,即在学习新知识的过程中,预训练的知识有可能被遗忘或者抹去。因此,本文探讨了BERT是否也存在这种灾难性遗忘问题。如下图所示,当采用较低的学习率时(文中采用2e-5),BERT在训练的过程中能够克服灾难性遗忘问题,而当学习率较大时(文中采用4e-4),就会失去这种能力。BERT预训练模型是在通用领域(General Domain)上做的Training,很自然的一个想法就是在目标域(Target Domain)进一步pretrain。任务内(within-task)pretrain是指在任务域(通常指具体的任务,比如某一金融细分领域的文本分类任务)上对模型进行预训练,预训练的方式仍然是unsupervised masked language model and next sentence prediction tasks,实验结果表明,任务内领域的预训练可以提升模型的效果,但在进一步预训练时需要注意training step,否则效果会变差。In-Domain指的是某一领域内数据,比如金融领域、计算机领域等等,该领域的数据分布往往和任务内数据分布相似,这里的Cross-Domain在内容上可以理解为通用领域,作者通过实验证明领域内(In-Domain)和任务内(Within-Task)的pretrain效果都会有提升,且通常情况下领域内的pretrain效果要好于任务内的pretrain效果,但在交叉域(或者说通用领域)上没什么提升,理由是BERT预训练本身就是在通用领域上训练的。实验结果对比如下图所示,all sentiment/question/topic代表In-Domain pretrain,all代表 Cross-Domain,w/o pretrain代表原始的BERT base 模型。在多任务数据域(比如多个文本分类的数据集,这样做的目的是为了充分利用已有的分类任务数据)上做pretrain,然后在target-domain上进行fine-tune,也会提升模型的效果。其中,
BERT-FiT = “BERT + Fine-Tuning”.
BERT-CDPT-MFiT-FiT = “BERT + Cross-Domain Pre-Training+Multi-Task Pre-Training+ Fine-Tuning”.(先在交叉域上做pretrain,然后在多任务域上做pretrain,最后在target-domian上做fine-tune)BERT pretrain model的一个优势在于,在下游任务中,只需要少量的样本就能fine-tune一个较好的模型,但是随着数据的增大,在任务内数据的pretrain model和通用领域的pretrain model最后fine-tune的效果差不多,其中红线代表BERT+Fine-tune,即直接利用BERT在target -domain上fine-tune,蓝线代表BERT+ withIn-Task Pre-Training + Fine-Tuning,即先用BERT在within-task域上pretrain,然后在target-domain上fine-tune,这说明了BERT可以利用小数据改进下游任务,且小样本数据上fine-tune效果较明显,当然如果能事先在within-task域上做进一步的pretrain,再做fine-tune,效果会更好。[1] Sun C , Qiu X , Xu Y , et al. How to Fine-Tune BERT for Text Classification?[C]// China National Conference on Chinese Computational Linguistics. Springer, Cham, 2019.获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码: