清华大学刘知远:知识指导的自然语言处理

大数据文摘授权转载自 AI TIME 论道
作者:刘知远
编辑:鸽鸽
“语言是一块琥珀,许多珍贵和绝妙的思想一直安全地保存在里面。”从人类诞生伊始,自然语言就承载着世世代代的智慧,积聚了无穷无尽的知识。这片深蕴宝藏的沃土吸引了众多满怀好奇的AI研究者,投入其中耕耘、开垦、发掘和重构。
2020 年 9 月 25日,由中国科协主办,清华大学计算机科学与技术系、AI TIME 论道承办的《2020 中国科技峰会系列活动青年科学家沙龙——人工智能学术生态与产业创新》上,清华大学副教授刘知远所作的学术报告《知识指导的自然语言处理》,于深度学习时代另辟蹊径,阐释了语言知识和世界知识对于自然语言处理的重要价值。
一、NLP研究需从语言自身特点出发
自然语言处理(Natural Language Processing, NLP),旨在让计算机掌握和运用人类语言。从词性标注、命名实体识别、指代消解、到语义和句法的依存分析,NLP工作者们致力于从无结构的语音或文字序列中挖掘出结构化信息。恍如从一片混沌中寻找秩序,无论是语义还是句法结构的,都不简单。
语言作为一个符号系统,包含多种不同粒度的语言单元。譬如中文的汉字、词、短语、句子、文档、直到文档互联构成的万维网,由下而上,粒度不断加粗。
而自然语言处理的很多任务,都涉及对不同层级的语言单元的语义相关度计算。例如信息检索就是给定一个query或者短语,找出哪些文档和该短语的语义最相关。由于语言的粒度大小不一,这就给计算增加了复杂度。
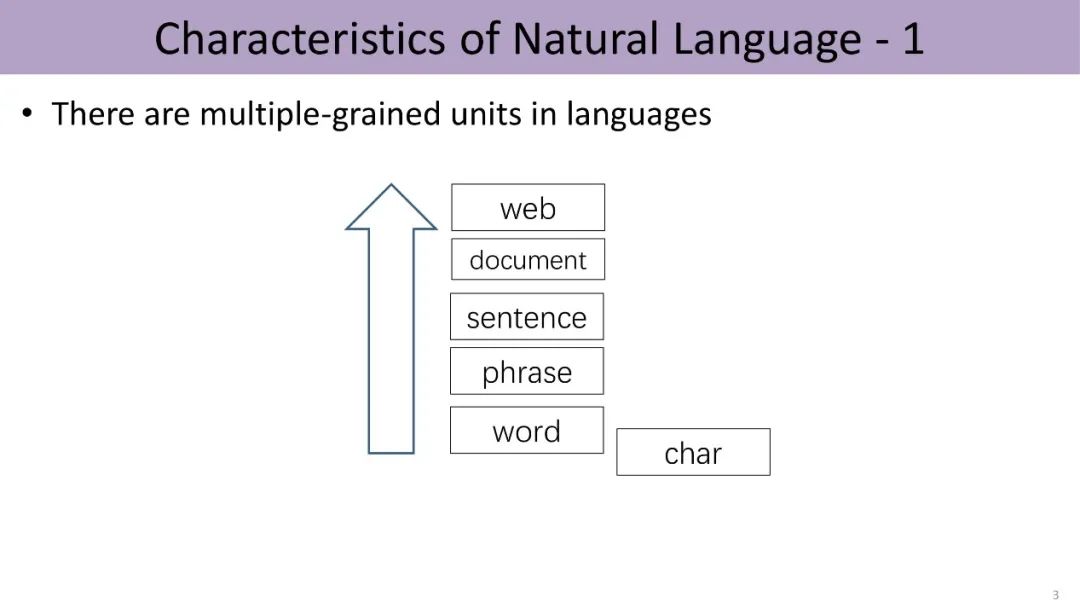
幸运的是,我们可以通过深度学习分布式表示,建立多粒度的语言关联。
深度学习是近十年内一场席卷AI界的技术革命,而深度学习在自然语言处理领域获得巨大成功的一个重要原因就是分布式表示。从词汇、词义、短语、实体到文档,深度学习把不同粒度的语言单元映射到统一的低维向量分布式表示空间,实现统一的隐式表示,有助于不同语言单位语义信息的融合与计算。这给NLP任务提供统一的表示基础,避免对不同任务设计不同的相似度计算方法,也能更好地解决大规模长尾分布数据稀疏的问题。
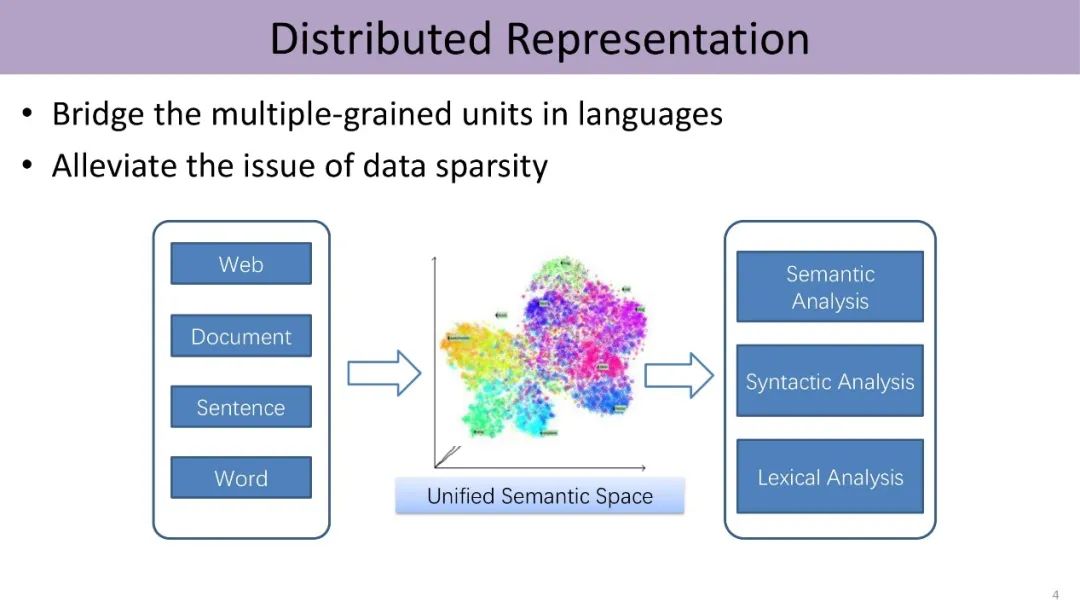
针对深度学习的分布式表示,2015年到2017年刘知远的实验室开展了不少相关工作。具体包括:把汉字和词结合进行统一表示、英文词义和中文词义的表示、短语的表示、实体和文档的表示等等。
二、融入语言知识库HowNet
尽管如今深度学习卓有成效,但自然语言处理尚未得到彻底解决。2015年Science刊登的一篇NLP综述中提到,尽管机器学习和深度学习已经成果丰硕,但要攻克真正的难题,包括语义、上下文、知识的建模,仍需更多研究和发现。

这就涉及语言的另一个特点:一词多义现象。日常交流中,我们把词或汉字视为最小的使用单位。然而,这些并非最小的语义单元,词的背后还会有更细粒度的词义层次,比如“苹果”这个词至少有水果、公司产品这两种解释。那么词义(sense)是最小单元么?可能也不是。
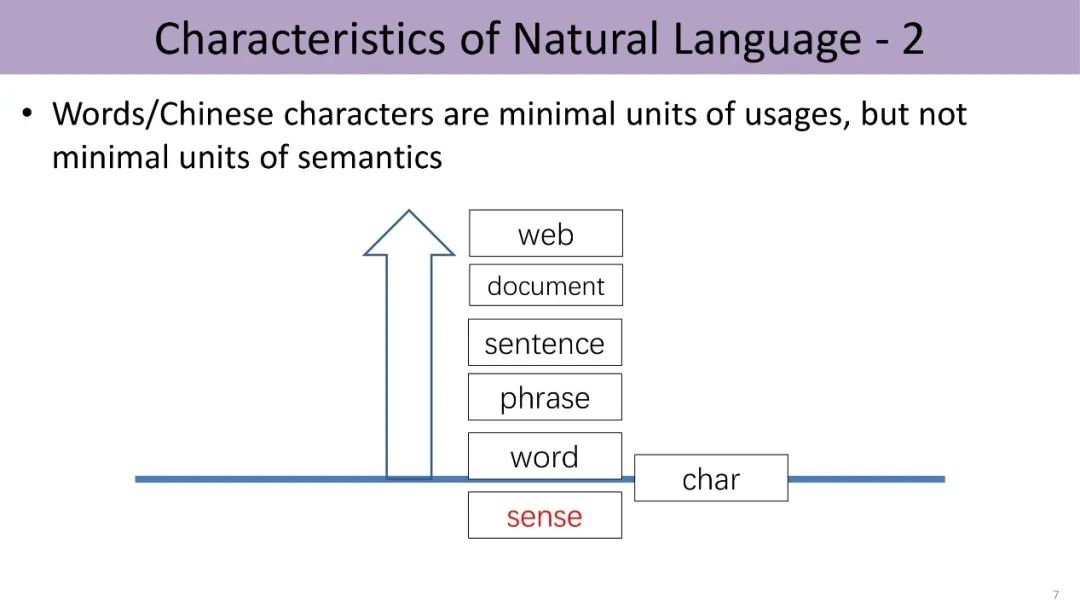
语言学家指出可以对词义进行无限细分,找到一套语义“原子”来描述语言中的所有概念。这套原子称为义原(sememes),即语义的最小单元。例如,“顶点”这个词可能有两个词义,每个词义用细粒度更小的义原来表示。如图,左边的词义是指某物的最高点,由四个义原的组合进行表示。
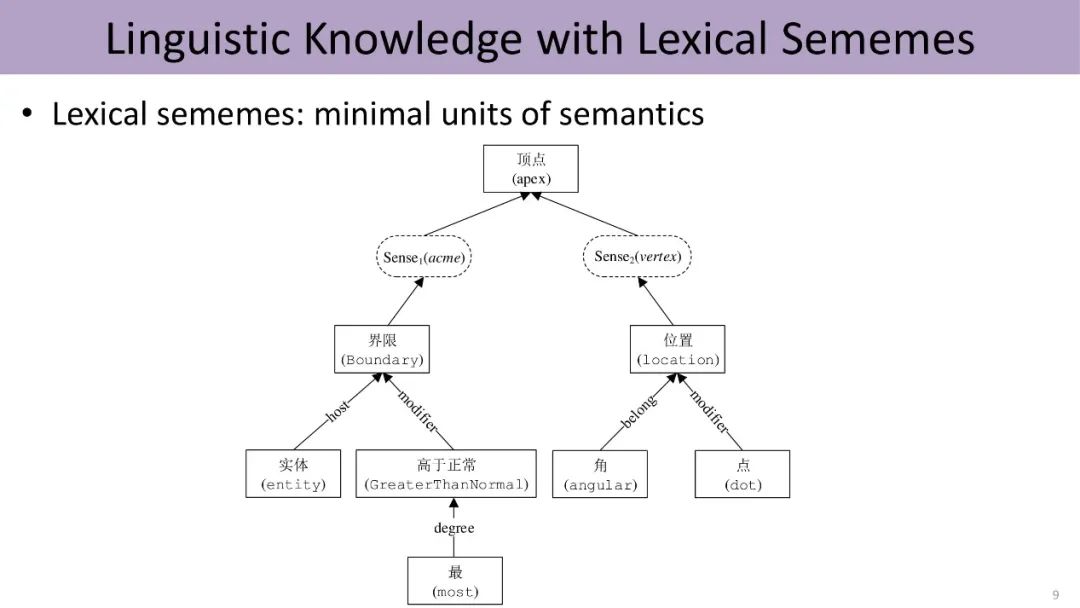
在人工标注义原方面,语言学家董振东先生辛劳数十年,手工标注了一个知识库HowNet,发布于1999年。经过几轮迭代,现囊括约2000个不同的义原,并利用这些义原标注了中英文各十几万个单词的词义。

然而深度学习时代,以word2vec为代表的大规模数据驱动的方法成为主流,传统语言学家标注的大规模知识库逐渐被推向历史的墙角,HowNet、WordNet等知识库的引用明显下跌。
那么,数据驱动是最终的AI解决方案么?
直觉上并非如此。数据只是外在信息、是人类智慧的产物,却无法反映人类智能的深层结构,尤其是高层认知。我们能否教会计算机语言知识呢?
HowNet与Word2Vec的融合
2017年,刘知远等人尝试将HowNet融入当时深度学习自然语言处理中一个里程碑式的工作Word2Vec,取得了振奋人心的实验效果。
下图展示了义原指导的word embedding,该模型根据上下文来计算同一词语不同义原的注意力、得到不同词义的权重,从而进行消歧,进一步利用上下文学习该词义的表示。尽管利用了传统Word2Vec中skip-gram的方法,即由中心词Wt预测滑动窗口里上下文的词,然而中心词的embedding由标注好的义原的embedding组合而成。因此,这项研究将HowNet中word、sense和sememe三层结构融入word embedding中,综合利用了知识库和数据两方面的信息。
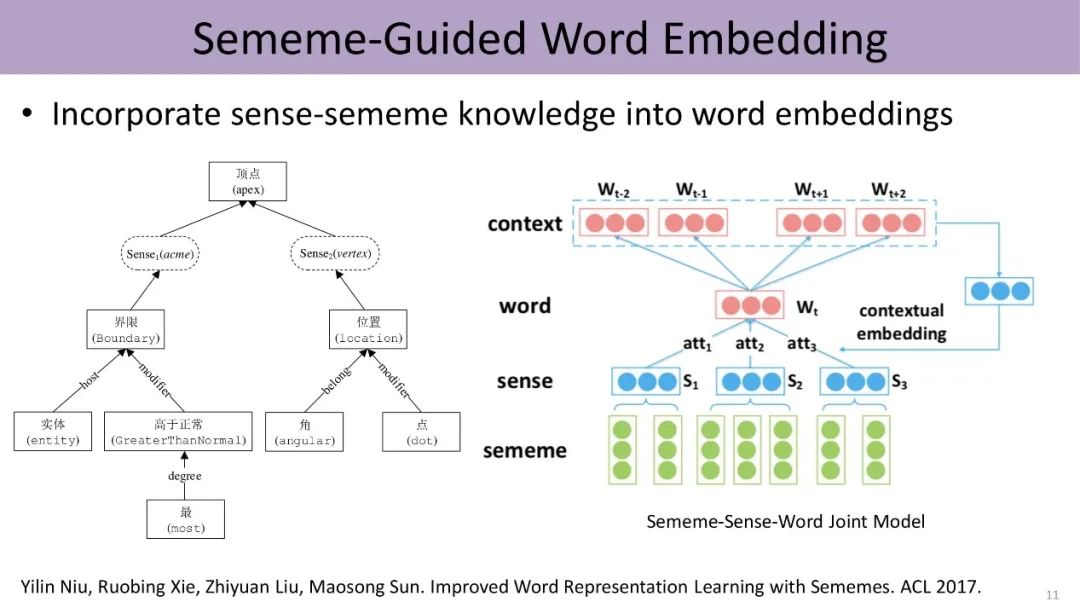
实验结果证明,融入HowNet的知识可以显著提升模型效果,尤其是涉及认知推理、类比推理等成分的任务。并且,我们能自动发现文本中带有歧义的词在具体语境下隶属于哪一个词义。不同于过去有监督或半监督的方法,该模型并未直接标注这些词所对应的词义,而是利用HowNet知识库来完成。由此可见,知识库对于文本理解能够提供一些有意义的信息。

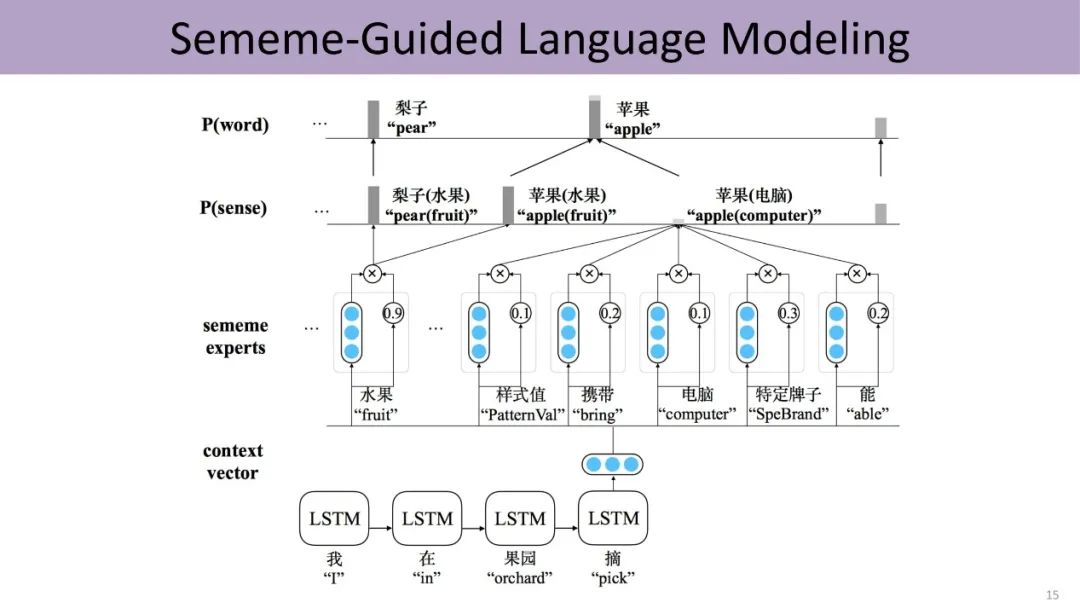
受到这项工作的鼓舞,刘知远的团队将知识的运用从词语层面扩展到句子级别。过去深度学习是直接利用上文的语义预测下一个词,现在把word、sense和sememe的三层结构嵌入预测过程中。首先由上文预测下一个词对应的义原,然后由这些义原激活对应的sense,进而由sense激活对应的词。一方面,该方法引入知识,利用更少的数据训练相对更好的语言模型;另一方面,形成的语言模型具有更高的可解释性,能够清楚地表明哪些义原导致了最终的预测结果。
HowNet作为董振东先生一生非常重要的心血,已经开源出来供大家免费下载和使用,希望更多老师和同学认识到知识库的独特价值,并开展相关的工作。下面是义原知识相关的阅读列表。

三、世界知识:听懂弦外之音
除了语言上的知识,世界知识也是语言所承载的重要信息。
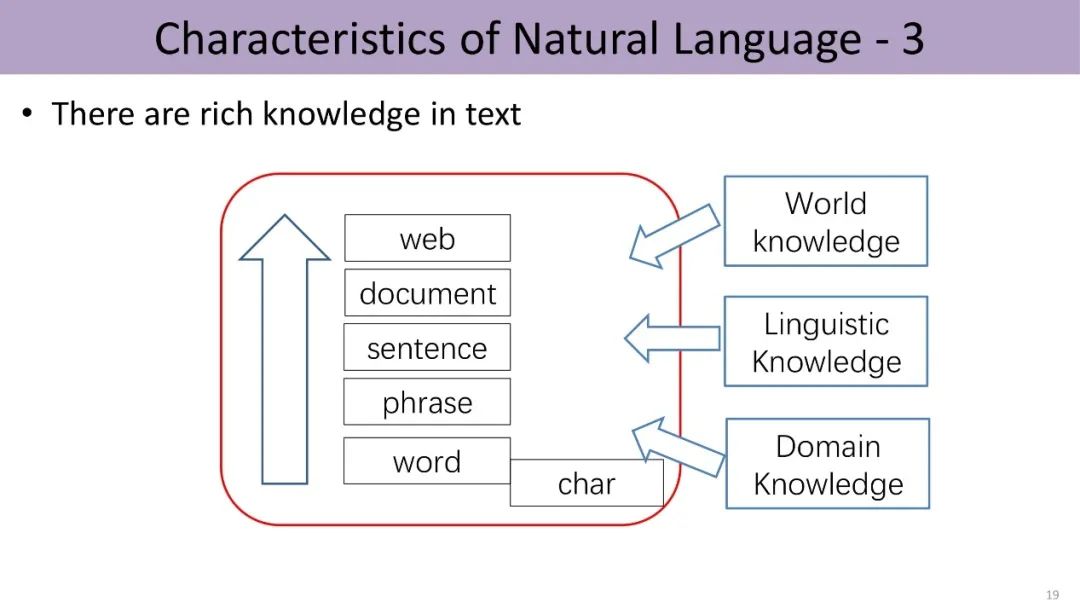
现实世界中有多种多样的实体以及它们之间各种不同的关系,比如莎士比亚创作了《罗密欧与朱丽叶》,这些世界知识可以构成知识图谱(knowledge graph)。在知识图谱中,每个节点可以看成一个实体,连接它们的边反映了这些实体之间的关系。图谱由若干三元组构成,每个三元组包括头实体、尾实体以及它们之间的关系。
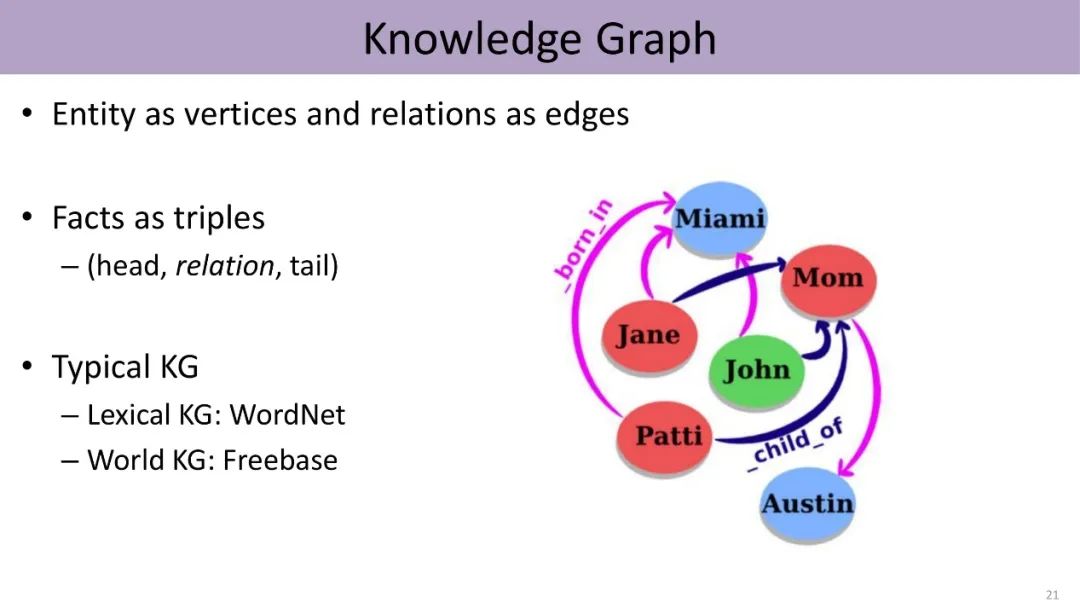
由于知识图谱中的实体隶属不同的类别,而且具有不同的连接信息,因此我们可以基于knowledge attention这种机制,把低维向量的知识表示与文本的上下文表示结合起来,进行细粒度实体分类的工作。
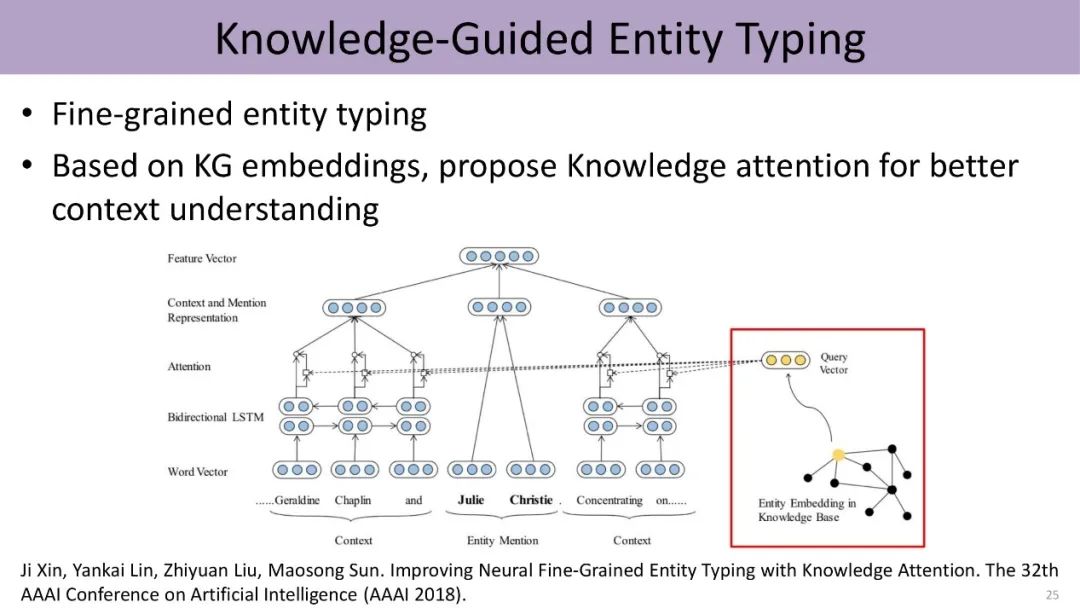
另一个方向是两个不同知识图谱的融合问题,实为一个典型的entity alignment的问题,过去一般要设计一些特别复杂的算法,发现两个图谱之间各种各样蛛丝马迹的联系。现在实验室提出了一个简单的方法,把这两个异质图谱分别进行knowledge embedding,得到两个不同的空间,再利用这两个图谱里面具有一定连接的实体对、也就是构成的种子,把这两个图谱的空间结合在一起。工作发现,该方法能够更好地进行实体的对齐。
同时,知识也能指导我们进行信息检索,计算query和文档之间的相似度。除了考虑query和document中词的信息,我们可以把实体的信息、以及实体跟词之间的关联形成不同的矩阵,从而支持排序模型的训练。
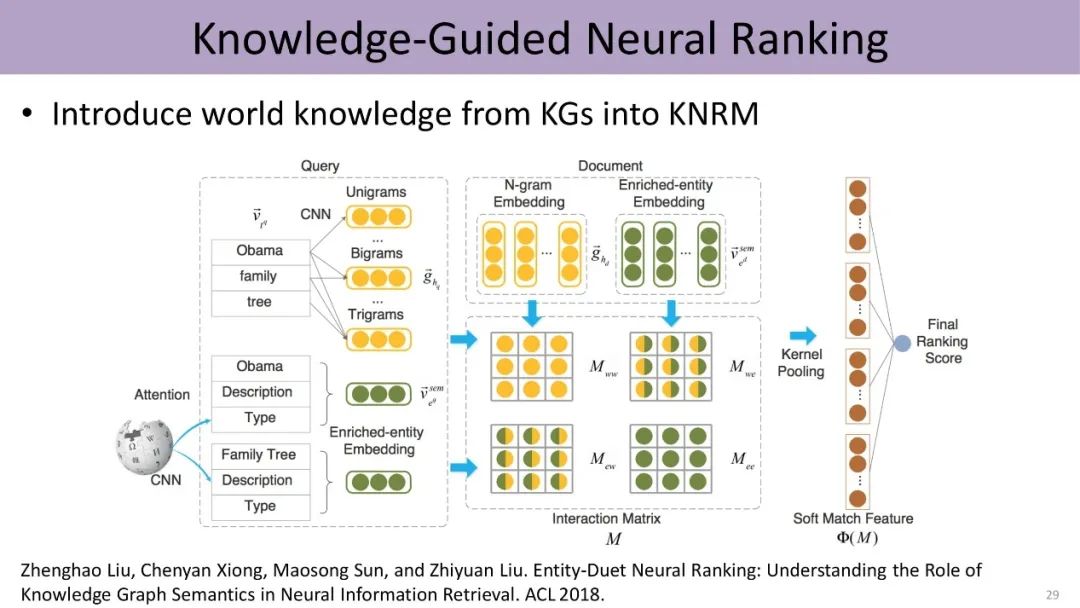
最后,预训练语言模型的诞生,把深度学习从原来有监督的数据扩展到了大规模无监督数据。事实上,这些大规模文本中的每句话,都包含大量实体以及它们之间的关系。我们理解一句话,往往需要外部的世界知识的支持。
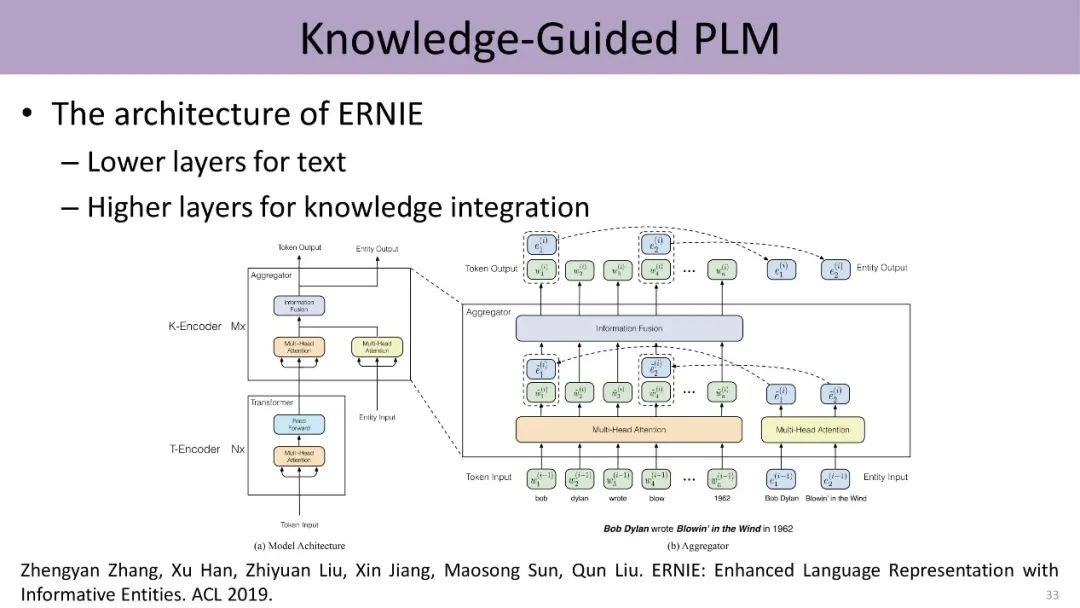
能否把外部知识库加入预训练语言模型呢?2019年,刘知远所在的团队提出ERNIE模型,使用知识表示算法(transE)将知识图谱中的实体表示为低维的向量,并利用一个全新的收集器(aggregator)结构,通过前馈网络将词相关的信息与实体相关的信息双向整合到一起,完成将结构化知识加入到语言表示模型的目的。
四、总结
本次报告主要从义原知识和世界知识两个方面,阐述了知识指导的自然语言处理相关的工作。未来自然语言处理的一个重要方向,就是融入人类各种各样的知识,从而深入地理解语言,读懂言外之意、听出弦外之音。针对面向自然语言处理的表示学习,刘知远等人也发表了一本专著,供大家免费下载研读。


相关链接及参考文献:




实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn