
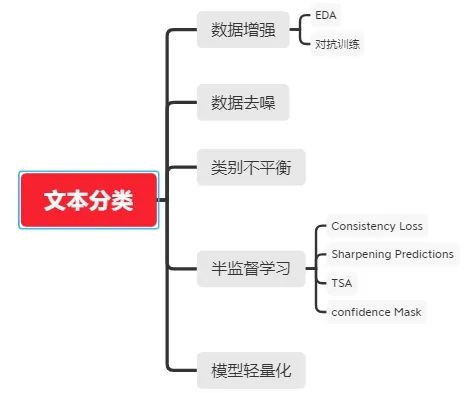
NLP文本分类任务落地的五大杀手锏!!!
作者 | 周俊贤
整理 | NewBeeNLP
文本分类是NLP领域的最常见工业应用之一,也是本人在过去的一年中接触到最多的NLP应用,本文「从工业的角度浅谈实际落地中文本分类的种种常见问题和优化方案」。
由于,项目中的数据涉密,所以拿公开的两个数据集进行实验讲解:今日头条的短文本分类和科大讯飞的长文本分类,数据集的下载见github的链接。
https://github.com/zhoujx4/NLP-Series-text-cls
今日头条的短文本数据示例如下,通过新闻的标题对新闻进行分类:

可以看到短文本分类的大部分数据都是很短的,经过EDA,发现99%以上的数据在40个字符以下。
科大讯飞的长文本数据示例如下,通过APP的简介对APP进行类别分类:

经过EDA探索,发现大部分数据长度在512以上,超过了Bert等模型的最大输入长度。
再看看数据集的label个数、训练集、验证集和测试集的数量分布:
| 短文本分类 | 长文本分类 | |
|---|---|---|
| 标签个数 | 15个 | 119个 |
| 训练集数 | 229605条 | 10313条 |
| 验证集数 | 76534条 | 2211条 |
| 测试集数 | 76536条 | 2211条 |
可以看到短文本是属于样本充足的情况,20多W条训练数据只需分成15个类,长文本分类属于样本不算充足的情况,1W条训练数据要分成119个类,其中数据集还有标签不平衡的问题。
首先搭建Baseline,Baseline用Roberta_base版本,把最后一层Transformer的输出进行mean和max后进行拼接,再连接全连接层,最后进行标签分类,由于Bert限制最大长度为512,对于长文本来说,可以通过「transfomrer-XL等改造模型」或者通过「截取字符」(从前面截取,或从中间截取,或从末尾截取)或「把文本进行分块」,分别输入模型中,再取概率平均,对于一般的任务,个人主要采用截取字符的方法,因为实现起来简单。
用Micro F1值作为评价标准,分数如下。
| 短文本分类 | 长文本分类 | |
|---|---|---|
| baseline | 0.8932 | 0.5579 |
可以看到长文本由于标签类别多,加上标签数据不太充分,难度比短文本难不少。
1、数据增强
1.1 EDA(Easy Data Augmentation)
图像任务中,有随机裁剪、翻转、改变饱和度等操作,同样地,文本也有不少的增强方法,如同义词替换,回译,近音字替换,随机插入,随机交换,随机删除等等,这里说一下个人平时用得做多,也认为效果最好的两个,「同义词替换」和「回译」
1.1.1 同义词替换:
做法可以是维护一个同义词表,如哈工大的发布的同义词词典。在每次训练的时候,样本有一定的概率对里面的词语进行替换。如"自动驾驶、医疗、能源……一季度融资最多的人工智能公司" -> "自动驾车、医术、能源……一季度融资最多的人工智能公司"。根据经验,「有条件的话最好用项目领域的同义词词典」,如做医疗的文本,就用医疗的同义词词典,做金融领域的就用金融的同义词词典,而不是用一个通用的字典。
还有种做法是用词向量进行替换,如上面的句子中,我们对"驾驶"一次进行同义词替换,发现在词向量表中,离"驾驶"余弦距离最近的一词是"行驶",所以就把"驾驶"替换成"行驶",当然这样做的话需要预先训练一个词向量表,还是那句话,最好用你目前手头任务领域的文本来训练词向量。
也可以用Bert等模型来进行替换,如把上面的句子随机MASK掉一些字,变成"自[MASK]驾驶、医疗、能源……一季[MASK]融资最多的人工智[MASK]公司",再让Bert对MASK掉的字进行预测,这样又得到新的一个样本。
1.1.2 回译
做法很简单,把中文翻译成英文或法文或日本,再翻译回中文,如下面的句子,先翻译成英文,再翻译回中文,"自动驾驶、医疗、能源……一季度融资最多的人工智能公司" -> "第一季度融资最多的自动驾驶仪、医疗保健、能源人工智能公司",有时回译能得到语法结构不同的句子,如被动句变成主动句,有效增强了样本的多样性。不过个人觉得,长文本并不适用于回译,想想一个500多字的长文本,经过回译后,上下文是否还通顺是个问题,当然也可以随机对长文本中的单句进行回译,而不是把整个长文本进行回译。
实际项目中取哪种数据增强方法,个人感觉是都要进行实验尝试,但无论进行何种尝试,把握一点就是「增强后的样本要和测试集的样本分布相似」,其实这也是无论做图像任务、检测任务还是机器学习的任务都通用的一点,假如你增强后的样本与真实要预测的样本出入很大,你还让模型去学,那怎么可能会带来正向的效果呢?对吧。
这里的实验,采用了同义词替换这个增强方法,用的同义词表就是上文提到的哈工大,用的是nlpcda库(貌似做中文文本增强的库不多,本人还没找到几个用得比较顺手的,当然也可以自己写数据增强这部分的代码,并不复杂),
| 短文本 | 长文本 | |
|---|---|---|
| baseline | 0.8932 | 0.5579 |
| +数据增强(同义词替换) | 0.8945 | 0.5742 |
可以看到经过数据增强后,分数都有所上涨,其实可以说几乎所有的任务,做数据增强都会带来正向的效果,但这个效果有多大的提升,就很依赖做数据增强的方法了,举个例子,一个样本"互联网时代有隐私可言吗?" ->"互联网时代有心事可言吗?",这个样本的增强我认为效果有限,因为增强后已经不是一个语义明了的句子了,还是那句话,「增强后的样本要和实际预测的样本分布要相似」,这样才能得到比较好的正向效果。
1.2 对抗训练
实质上,对抗训练用于文本这几年基本成为算法比赛获奖方案的标配,如FGM、PGD、YOPO、FreeLB 等一些系列的思想。个人认为对抗训练属于数据增强的一部分,因为在深度学习进行文本分类中,无外乎将字或词映射成向量作为模型输入。
如输入为词的模型,"互联网时代有隐私可言吗?"分词后是[互联网,时代,有,隐私,可言,吗,?],每个词在word embedding词表中找到对应的向量作为模型的输入,“隐私”替换成“秘密”,只是在输入的时候,把"隐私"这个词的向量用"秘密"的词向量作为替换,那自然有个思想,「既然增强的目的是使模型的输入发生改变,那为何不能直接从原本的字向量中加入噪声扰动呢」?

添加噪声扰动的思想想到了,也有个问题,噪声有很多种,是加入高斯噪声、还是均值噪声还是其它?其中对抗训练的思想就是「往损失函数上升的方向,在embedding层添加扰动」,对抗训练有很多可供学习的代码和博文[2][3],这里就不再细说了。值得注意的是,添加对抗训练后,训练时间会近乎成倍增常,就拿FGM来说,每一次更新参数,都进行了两次后向传播。在大部分场景下,基本都会加上FGM,基本都能带来正向的效果,而且FGM相对其它对抗方法,所耗时间也较少。
| 短文本 | 长文本 | |
|---|---|---|
| baseline | 0.8932 | 0.5579 |
| +FGM对抗训练 | 0.8970 | 0.5873 |
可以看到加上对抗训练后,效果都有一定的提升。
2、数据去噪
大家都说算法工程师80%在洗数据,20%时间在跑模型,实质上,以我的个人经验来说,这个说法也是有道理的,一个AI应用,一周的时间要解决的话,在准备数据层面可能会花3~4天。特别是做久了之后,很多模型的组件,方法论都已成型,想比较不同方法的效果,从以往积累的项目库里把相关代码抽出来,就可以跑来做实验了,时间成本很低。而且做项目,最后常常会发现,制约模型效果再上一步的,往往是最数据质量,所以洗数据尤为关键,想想假如你在一个准确率只有80%的训练集上训练模型,你觉得你训练出来的模型最后在测试集的准确率能超过80%吗?
通常,接到一个AI需求,假如要训练机器学习或深度学习的模型,标注数据是必不可少的,来源可以是已有的人工标注,没有的话,只能自己或者找实习生标注进行打标,假如需要的标注样本多的话,还可以请众包公司进行标注。就拿文本分类来说,人工标注准确率有95%就已经很好了。
怎么清洗标注错误的数据呢?这个问题其实本人还没有很深的积累,常常优先使用的方法是「根据业务规则洗」,就拿前段时间做的一个工单分类的项目来说(以往是人工分类,客户想用AI的方法进行自动分类),以往确实积累了几万条人工分类过的样本,但以往的工作人员很多是凭经验进行随机分类的,所以在看数据的时候,看的我皱眉头,很多都是分类错误的,这时候,只能和客户不断沟通,拿更多的资料,思考从客户角度,他们判断类别的逻辑,从而把错误的样本修正过来,这个过程很耗时,但也很重要,我想这也是实际做项目和打比赛的一个很大的不同。
除此之外,还有没有更智能的清洗数据方法?有不少前沿的论文对这些方法进行过讨论,如通过置信度清洗数据等等,但实际上,很多方法都仅仅能针对非常有限的场景,效果有限。
本人常常用的比较笨的方法是「交叉验证清洗」,如"湖人拿到2020年NBA的总冠军"这样本,在训练集上把它标注为"娱乐"新闻,很明显是错误的,像这种错误,用交叉验证的方法洗是最容易的,举个例子,我们可以对训练集训练一个5折的模型,然后对训练集进行预测,假如这个样本在5折模型中都预测为"体育",则把该样本的label从"娱乐"修正为"体育",用交叉验证的方法能批量洗掉一些很明显错误的样本,但是这个阈值(出现5次还是4次以上就把该样本修正)需要多做实验。
3、类别不平衡
针对类别不平均的问题,有过采样、欠采样、改造损失函数等方法入手。实际项目落地时,还需要考虑客户的需求,例如某个标签的样本很少,导致这个样本的召回率、精确率都比较低,但可能客户不太关心这个标签的精确性,这时候也没必要花太多时间纠结如何改善。
个人经验来说,我会比较倾向使用改造函数函数来调接样本不平衡的问题,因为无论是过采样或者欠采样,都会导致样本噪声这个问题,而改造损失函数,如调整不同样本的权重,采用Focal Loss等等函数都能有限减少不平衡的问题。
关于类别不平衡的问题,有更深入的思考再补充。
4、半监督学习
思考上文提到的文本数据增强的方法,无论一个样本经过同义词替换,还是回译,还是随机交换词语的位置生成多个样本,其实人还是能判断出这几个样本来源同一个句子,从这个角度出发,数据增强带来的效果有限,想想假如训练集只有100条样本,无论你怎么做增强,本质上,样本的来源其实就是那100条,这样模型训练出来的效果也有限。这时候,就体现出半监督学习的重要性,如何把海量的无标注数据纳入进模型训练。
前段时间,本人接到一个机器阅读理解的项目,客户提供了3W条无标注数据,花了一天辛辛苦苦标注了1000条,但由于时间关系,客户说2天必须出结果,还剩下一天要马上进行模型训练,这时候就把剩下的2.9W条无标注数据抛弃掉吗?实质上,就要考虑半监督的方法了。
这里用到的方法是谷歌在2019年的一篇论文:《Unsupervised Data Augmentation for Consistency Training》。

思想很简单,对于标注好的样本一样用交叉熵作为损失函数,对于没标注的样本,则用Consistency Loss。
4.1、Consistency Loss(一致性损失)
拿一个例子来说明UDA中的一致性损失,如现在只有【体育,娱乐,金融,政治】四个分类,某个样本"詹姆斯超乔丹论调遭麦蒂吐槽:为什么人们总会忘记科比?",在模型训练过程中,模型判断出的该样本属于四个类别的概率分别为【0.5, 0.15, 0.15, 0.2】,这时候对该样本进行数据增强(这也是论文标题出现Data Augmentation的原因,原论文用了同义词替换和回译两种方法),样本变成"詹姆斯强于乔丹论调遭麦蒂埋怨:为什么人们总会遗忘科比?"。一致性的意思就是认为,「增强后的样本跟原来的样本语义相同,这时候模型的输出概率就应该保持一致」,所以增强后的样本的概率分布应该要去拟合【0.5, 0.15, 0.15, 0.2】这一概率分布。在论文中,「用原样本的输出概率分布和增强样本的输出概率分布的KL散度损失与有标签样本的交叉熵损失进行联合训练」。
在UDA方法中,还有许多训练的细节,如Sharpening Predictions、TSA(TRAINING SIGNAL ANNEALING)等等,下面简单介绍一下这些细节。
4.2、Sharpening Predictions
半监督学习的大部分论文中,除了Consistency思想,其实还是一种思路是最小化熵,还是拿一个样本进行举例,如"用摄影记录当红女星杨幂成长之路"这一无标签样本,还是【体育,娱乐,金融,政治】四分类,把样本输入模型,模型其实不是直接输出概率,而是不同的数值,如【0.50, 1.05, -0.56, 0.01】,把这些数据经过Sofrmax才得到概率分布【0.27, 0.47, 0.09, 0.17】,这时候同上面的思想一样,我们把样本进行数据增强后输入模型,让输出的概率去拟合【0.27, 0.47, 0.09, 0.17】这一概率分布。
但在这里我们有个不同的处理,在原样本的Softmax过程中,我们引入Sharpening Predictions,「Softmax( l(X) / τ )」 计算,其中l(X)表示结果逻辑分布概率,即上面的【0.50, 1.05, -0.56, 0.01】,τ 表示温度。τ 越小,分布越Sharper。如τ =0.6,【0.50, 1.05, -0.56, 0.01】每个元素都除以τ,变为【0.83, 1.75, -0.93, 0.02】,再经过Softmax,得到分类概率为【0.24, 0.61, 0.04, 0.11】,可以看到τ 取小于1的数,Softmax输出的概率分布会「更"Sharpening",即为更陡峭,熵也越低」(思考一下,概率分布陡峭了,不确定自然也少了,熵也自然少了)。
为啥要引入Sharpening Predictions?「我认为是为了让模型输出能更明确,或者说就是让熵尽可能小」,让模型更 倾向输出【0.97, 0.01, 0.01, 0.01】这种明确性更高的、低熵的概率分布,而不是【0.7, 0.1, 0.1, 0.1】这种相对来说不是很明确的概率分布,增加模型的鲁棒性。
4.3、TSA(TRAINING SIGNAL ANNEALING)
思考一个问题,假如你现在只有50个标注样本和20K个无标注样本,假如不经过任何处理,直接进行联合训练,很可能的情况是,模型会对50个标注样本过拟合,因为标注样本数量实在太少了,所以这里引入TSA。
举个例子,我们取TSA=0.5,对于某个标注样本"去年A股上市公司高管薪酬比拼:金融和房地产业最高",还是【体育,娱乐,金融,政治】四分类,其真实标签为"金融",模型输出的概率分布为【0.1, 0.1, 0.7, 0.1】,由于其真实标签的概率为0.7>0.5,所以我们不把该样本的损失考虑进行,只有其真实标签的概率小于TSA的样本的损失我们才用来进行反向传播,通过这一方法,「减缓模型对于少量标签样本过拟合的步伐」。TSA系数是随着训练过程不断增加的。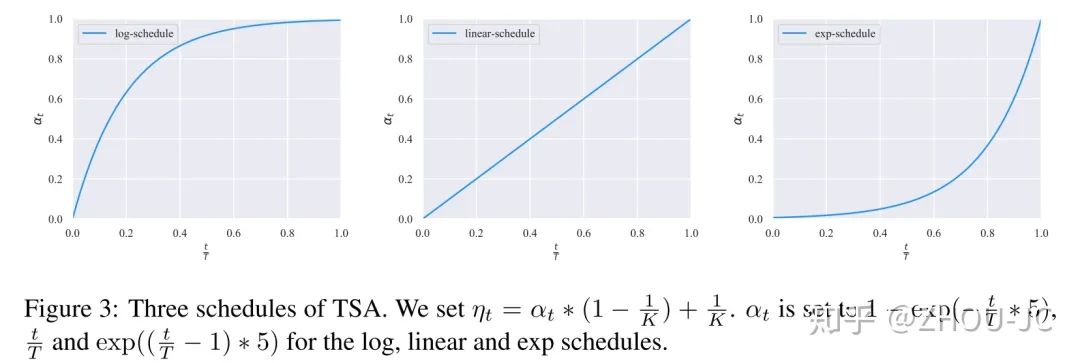
具体的,假如分类问题很简单,标注样本相对无标注样本很少的情况下,就用指数增长,在前期,TSA系数增常很慢,维持在一个很低的值,尽可能不把容易学习的标注样本的损失考虑进去,避免模型对标注样本过拟合。
4.4、Confidence Mask
首先设定Confidence Mask系数,如把Confidence Mask Coefficient=0.5,把无标注样本输入模型,得到概率分布为【0.3, 0.25, 0.4, 0.05】,由于最大的类别概率也少于0.5,所以就不把该无标注样本的 Consistency Loss 纳入到反向传播中。
UDA的详细效果请看下表,
| 短文本 | |
|---|---|
| 50条标注数据 | 0.6443 |
| 50条标注数据+30W条无标注数据(无标注取自训练集+验证集+测试集) | 0.7410 |
| 100条标注数据 | 0.7342 |
| 100条标注数据+30W条无标注数据(无标注取自验证集+测试集) | 0.7877 |
| 20W条标注数据 | 0.8933 |
| 20W条标注数据+10W条无标注数据(无标注取自验证集+测试集) | 0.8920 |
可以看到引入半监督学习,在缺少标注数据的情况下,提升巨大,但随着标注数据的不断增加,半监督带来的正向效果也在不断减少,在原论文中讨论过,「当标注数据充分的情况下,无监督仍能带来少量的提升」。
但在本实验中,看最后两行,可以发现标注数据充分的情况下,引入半监督是没有提升的,我估计是这里的数据增强做得太简单了,这里的数据增强只是对句子中的词进行同义词替换, 而原论文用了一种考虑更细致的方法,思想是用TF-IDF进行统计,「样本中对分类成功贡献很大的词,不进行替换」,更详细的思想可以看原论文和论文源代码。
5、模型轻量化
模型轻量化也是更实际落地常常碰到的问题,一般的AI项目,可能存在资源不充足的情况,如客户提供的服务器不包括GPU,这时候就要在自己公司的服务器上把模型先训练好,再迁移到客户的服务器,用CPU部署,这时要考虑推断速度是否满足项目需求,也有可能是服务器可能不止部署你一个模型,还要部署其它系统应用,这时候给你留下的内存就不足了。当然最好是项目前期,就像客户说明需求的配置,让客户尽量满足,但实际上,随着项目的进展,很可能发生各种意外情况。
在实际部署中,本人比较倾向用docker这种微服务进行部署,通常一个bert模型加上docker需要的基础环境,用CPU进行部署,把容器起起来后,占用的内存会到2G左右,推断速度大概在1~2秒/一个样本。
模型轻量化也有几种思路,如「模型剪枝」(把贡献不高的神经元去掉)、换「轻量化模型」(如用3层Bert代替原生的12层Bert、或者换Fasttext等轻量化模型)、「模型蒸馏」(TinyBert等蒸馏模型)。
想想在某个应用种,Bert模型能得到89%的准确率,FastText能得到85%的准确率,最终上线的时候你会考虑用哪个模型?不是说Bert不好,但毕竟它在某些资源有限的情形下,还是显得太"重"了,但Bert可以作为一个性能标杆,用轻量化的模型不断去逼近Bert的效果。
以上就是实际落地中,文本分类常遇到的问题和相应的解决方法。本文会不断完善。
参考
nlpcda库 https://pypi.org/project/nlpcda/ 【炼丹技巧】功守道:NLP中的对抗训练 + PyTorch实现 https://zhuanlan.zhihu.com/p/91269728 一文搞懂NLP中的对抗训练FGSM/FGM/PGD/FreeAT/YOPO/FreeLB/SMART https://zhuanlan.zhihu.com/p/103593948 《Unsupervised Data Augmentation for Consistency Training》 http://cn.arxiv.org/pdf/1904.12848v5
- END -
