
MetaFormer的视觉Baseline开源!颜水成团队再出马,顺带刷新ImageNet新记录!

极市导读
原班人马对MetaFormer进行了进一步的探索:依托MetaFormer引入了最基本的Mixer,提出了4个基线模型且都取得了相当不错的效果。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

MetaFormer论文链接:https://arxiv.org/abs/2210.13452
MetaFormer:https://github.com/sail-sg/metaformer
PoolFormer论文链接:https://arxiv.org/abs/2111.11418
PoolFormer:https://github.com/sail-sg/poolformer
Transformer在CV领域的成功到底是什么呢?最近两年来各种Transformer与MLP架构设计意义真的有那么大呢?CV老将“水哥”颜水成团队于2021年11月份提出的MetaFormer之PoolFormer可能提供了一个非常有价值的参考,PoolFormer感兴趣的朋友可以关注如下解读:Transformer的终章还是新起点?颜水成团队新作:MetaFormer才是你真正需要的!
近日,原班人马对MetaFormer进行了进一步的探索:依托MetaFormer引入了最基本的Mixer,提出了几个基线模型并取得了喜人的性能,得出以下几个发现:
MetaFormer确保了模型的性能下限:当采用Identity作为Mixer时(IdentityFormer)时,取得了>80%的精度;
MetaFormer对任意Mixer均表现良好:甚至采用随机矩阵进行Mixer(RandFormer)时,模型仍可取得>81%的精度;
MetaFormer可以毫不费力的达成SOTA指标:(1) 当采用深度分离卷积进行Mixer(ConvFormer,可视作纯CNN方案),具有比ConvNeXt更佳的性能;(2) 当在bottom阶段使用深度分离卷积,在top阶段使用普通自注意力时(CAFormer),模型取得了新的SOTA指标85.5%(尺寸测试,无需额外数据或蒸馏)。
除了上述发现外,作者还发现了一种新的激活函数StarReLU:相比GELU,其计算量可减少71%,同时性能更高。具体来讲,StarReLU是SquaredReLU的变种,它被用于消除分布偏移(distribution shift)。

MetaFormer
MetaFormer脱胎于Transformer的一种广义架构,它并未指定Token Mixer的实现方式。具体来说,输入首先转为为特征序列(即token序列,笔者往往将其称之为词):
然后,这些特征序列将送入到MetaFormerBlock中进行处理:
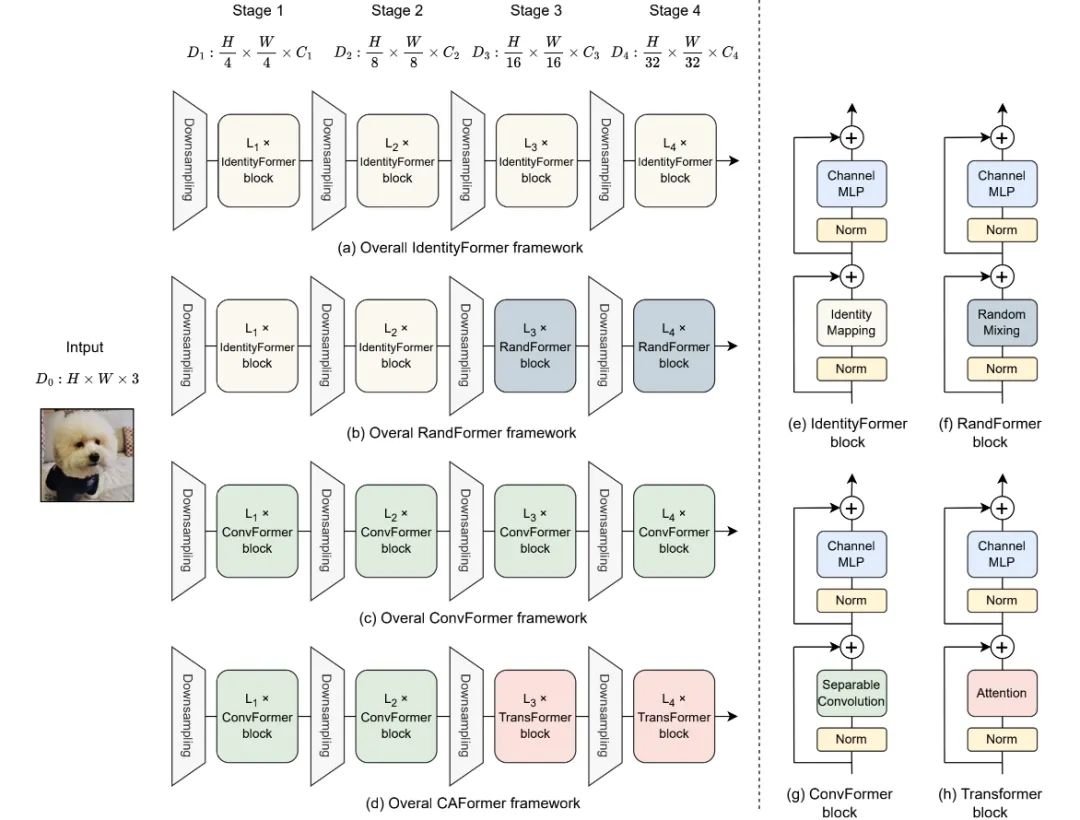
当指定TokenMixer的实现方式后,MetaFormer将演变为特定的模型。正式介绍之前,先来"剧透"一下本文所提到的IdentityFormer、RandomFormer、ConvFormer、CAFormer架构体系。
Technique to improve MetaFormer
本文并未引入复杂的Mixer技术,相反,作者提出了一种新的激活函数StarReLU与两种改进以改善MetaFormer性能。
StarReLU
ReLU与GELU分别表示如下:
从计算复杂度角度来看,对于每个单元来讲,ReLU为1FLOPs,GELU则为14FLOPs。为简化GELU,有研究发现可以通过ReLU进行替换,得到如下表示:
相比GELU,SquaredReLU每个单元计算量为2FLOPs。尽管如此,作者发现:对某些分类模型而言,SquaredReLU的性能不如GELU。作者认为:该性能退化源自分布偏移。假设输入服从正太分布,此时有:
为消除分布偏移作者提出了如下StarReLU方案:
然而,上述关于输入的假设过强,为使得该激活函数可以适用于不同条件(不同模型、不同初始化)。作者进一步将其重写如下:
相比GELU,StarReLU的计算复杂度仅为4FLOPs,同时可以取得更高的性能。
Other modifications
Scaling branch output 为提升Transformer模型深度,Hugo等人提出了LayerScale:
类似地,也有学者提出ResScale对残差分支添加scaling参数:
上述两者的合并则得到了BranchScale:
作者发现:ResScale表现最佳。因此,MetaFormer默认选择ResScale。
Disabling Biases 在MetaFormer模块中,移除了全连接层的偏置参数,该操作不会降低性能,甚至对个别模型还可以轻微提升。为简单起见,MetaFormer默认禁用biases。
IdentityFomer and RandFormer
延续PoolFormer理念,我们尝试将TokenMixer进行实例化以进一步探索MetaFormer的性能。
首先,作者考虑了Identity Mapping:
当然,Identity Mapping并未进行任何Mixer。
然后,作者引入另一种Mixer操作:Global Random Mixing:
注:在随机初始化后冻结。下图给出了两者的实现参考Code。
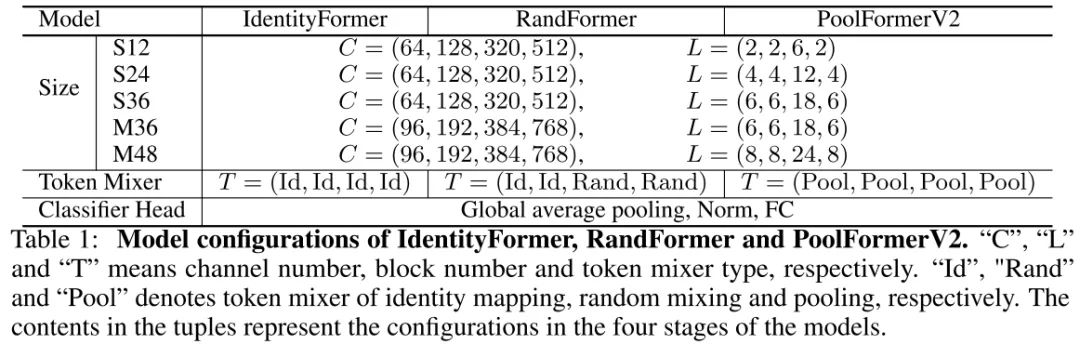
在模型构建方面,作者仍延续了PoolFormer的4阶段方式构建了不同大小的模型,详见下表。需要注意的是:考虑到RandomMixing带来的额外参数量与计算消耗,RandFormer在前两个阶段使用IdentityMapping,仅在后两个阶段使用RandomMixing。此外,为更公平的与Poolformer对比, 作者将前面提到的技术用于PoolFormer得到了PoolFormerV2.
ConvFormer and CAFormer
前面的方案采用最基本的Mixer方式探索了模型的性能下限。接下来,作者采用常见的Mixer方式以探索模型的上线。
首先登场的是深度分离卷积,作者延续了MobileNetV2的逆分离卷积模块设计,所得模型称之为ConvFormer:
参考ConvNeXt,作者将深度卷积核尺寸设置为,扩展比例设为2,参考实现代码如下。

除了卷积外,另一种常见的Mixer为Transformer中的自注意力,它具有更好的全局建模能力,但是会导致较高的计算复杂度。受启发于CoAtNet,作者在前两个阶段使用卷积进行Mixer,后两个阶段使用自注意力,进而构建了CAFormer。关于ConvFormer与CAFormer的参数配置可参考下表。

本文实验
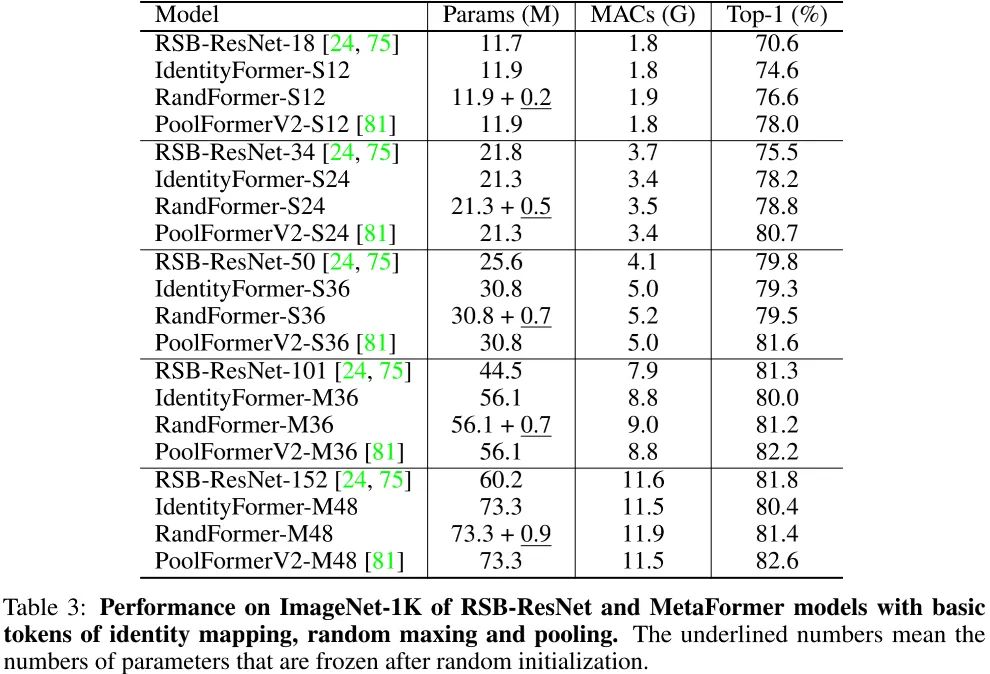
上表给出了本文几种方案的性能对比,从中可以看到:
哪怕采用最简单的Identity,IdentityFormer仍可表现很好。在小模型方面,IdentityFormer-S12/S24分别比RSB-ResNet-18/34高出4.0%/2.7%;进一步扩大后,IdentityFormer-M48取得了80.4%的指标,超过了RSB-ResNet-50的79.8%。IdentityFormer表征了MetaFormer的性能下限,也就是说,当MetaFormer基础上进一步探索时,IdentityFormer-M48大小的模型性能不会低于80%!
在IdentityFormer的后两个阶段引入随机混合后,RandFormer可以进一步提升性能。小尺寸模型RandFormer-S12/M48分别取得了76.6%/81.4%;中尺寸模型RandFormer-M36取得了81.2%,与RSB-ResNet101相当;大尺寸模型RandFormer-M 48取得了81.4%。这说明:MetaFormer对任意TokenMixer机制均表现很好,验证了其统一性。
相比PoolFormerV2,RandomFormer的性能差异可能源自pooling操作引入的局部归纳偏置。
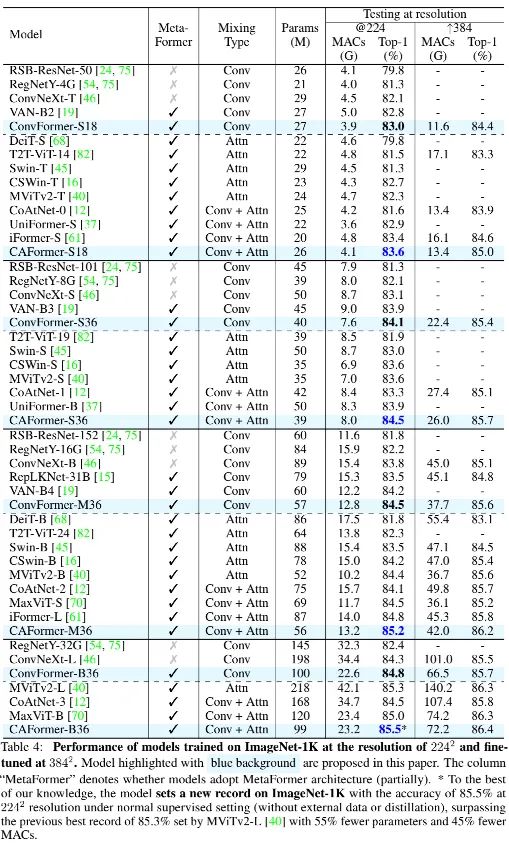
上表给出了ConvFormer、CAFormer与业界其他方案的性能对比,可以看到:
ConvFormer(实际上是一种纯CNN架构)具有比ConvNeXt更优的性能。ConvFormer-B36比ConvNeXt-B高出0.5%,且仅需51%参数量,66%计算量。与此同时,ConvFormer比Swin、CoAtNet等方案性能更高,参数量与计算量更少。
相比ConvFormer,CAFormer取得了更高的性能。值得一提的是,CAFormer在ImageNet上取得了新的SOTA记录85.5%(常规监督训练,224尺寸,无额外数据或蒸馏) 。
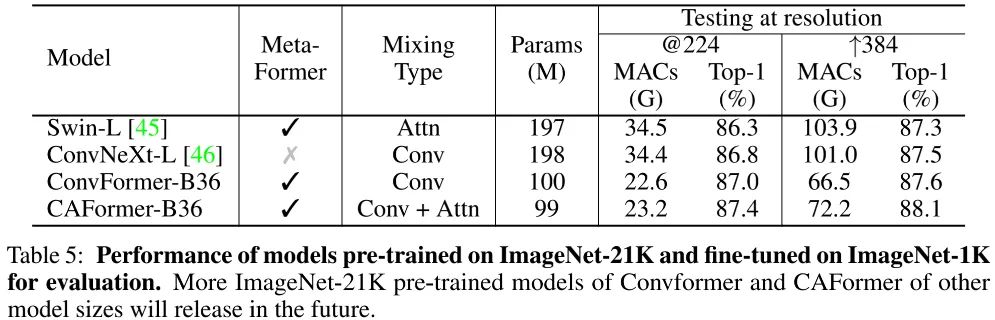
此外,当引入ImageNet21K预训练后,ConvFormer-B36与CAFormer-B36可以进一步提升到87.0%、87.4%(相比ConvNeXt-L,ConvFormer-B36指标高出0.2%且参数量少49%,计算量少34%);当测试分辨率提升到384后,指标还可以进一步提升到87.6%、88.1% 。
仅仅使用上述"old-fashioned"Mixer机制,MetaFormer已取得了惊人的性能,CAFormer甚至打下一个新记录。这意味着:MetaFormer具有取得SOTA性能的潜力。当采用更优的Mixer机制或更好的训练策略后,MetaFormer的性能有可能进一步取得新的记录。
公众号后台回复“开学”获取CVPR、ICCV、VALSE等论文资源下载~

# 极市平台签约作者#

happy
知乎:AIWalker
AIWalker运营、CV技术深度Follower、爱造各种轮子
研究领域:专注low-level,对CNN、Transformer、MLP等前沿网络架构
保持学习心态,倾心于AI技术产品化。
公众号:AIWalker
作品精选
