2020 年 10 月,谷歌大脑团队提出将标准 Transformer 应用于图像,提出了视觉 Transformer(ViT)模型,并在多个图像识别基准上实现了接近甚至优于当时 SOTA 方法的性能。近日,原 ViT 团队的几位成员又尝试将 ViT 模型进行扩展,使用到了包含 30 亿图像的 JFT-3B 数据集,并提出了参数量高达 20 亿参数的 ViT 变体模型 ViT G/14,在 ImageNet 图像数据集上实现了新的 SOTA Top-1 准确率。
基于注意力机制的 Transformer 架构已经席卷了 CV 领域,并成为研究和实践中日益流行的选择。此前,Transformer 被广泛用于 NLP 领域。有研究者仔细研究了自然语言处理中 Transformer 最优扩展,主要结论是大型模型不仅性能更好,而且更有效地使用了大量计算预算。然而,目前尚不清楚这些发现在多大程度上能够迁移到视觉领域。例如,视觉中最成功的预训练方案是有监督的,而 NLP 领域是无监督预训练。在今天介绍的这篇论文中,原 ViT 团队成员、谷歌大脑的几位研究者集中研究了预训练 ViT 模型用于图像分类任务的迁移性能的扩展规则(scaling law)。特别是,研究者试验了从 500 万到 20 亿个参数不等的模型、从 3000 万到 30 亿个训练图像不等的数据集以及从低于 1 个 TPUv3 核每天(core-day)到超过 10000 个核每天的计算预算。其主要贡献是描述 ViT 模型的性能计算边界。
论文链接:https://arxiv.org/pdf/2106.04560.pdf在这个过程中,研究者创建了一个改进的大规模训练方案,探索了训练超参数以及发现微妙的选择,大幅改善小样本迁移性能。具体来说,研究者发现非常强的 L2 正则化,仅应用于最终的线性预测层,导致学习到的视觉表征具有很强的小样本学习能力。例如,在 ImageNet 数据集(有 1000 个类)上,每个类只有一个示例,该研究的最佳模型达到 69.52% 的准确率;如果每个类有 10 个示例,准确率达到了 84.86%。此外,该研究大大减少了 [11] 中提出的原始 ViT 模型的内存占用,通过特定于硬件的体系架构更改和不同的优化器来实现这一点。结果表明,该研究训练了一个具有 20 亿个参数的模型,在 ImageNet 数据集上达到了新的 SOTA 性能 90.45% 的准确率。可以看到,在 SOTA 基准排行榜上,ViT-G/14 模型的 Top-1 准确率已经超越了谷歌之前提出的 Meta Pseduo Labels 模型。
研究者展示了对 ViT 模型及训练的改进,这些改进大多数易于实现,并显著提升了内存使用率和模型质量。如此一来,研究者可以单独使用数据并行化训练 Vit-G/14 模型,并在单个 TPUv3 上实现整个模型拟合。该研究使用专有的 JFT-3B 数据集,它是 JFT-300M 数据集的更大规模版本,在之前的许多大型计算机视觉模型工作中使用过 [31, 18, 11]。该数据集由近 30 亿张图像组成,标注为包含 30k 类别的层级类别,并且由于采用半自动标注,所以标注是有噪音的。所有的测试数据也均从 JFT-3B 中移除。下图 5 展示了数据集从 JFT-300M 到 JFT-3B 过程中对模型性能的影响。可以观察到,更大规模的 JFT-3B 数据集可以得到更好的模型,所以 JFT-300M 数据集的过拟合并不是实现性能提升的唯一原因。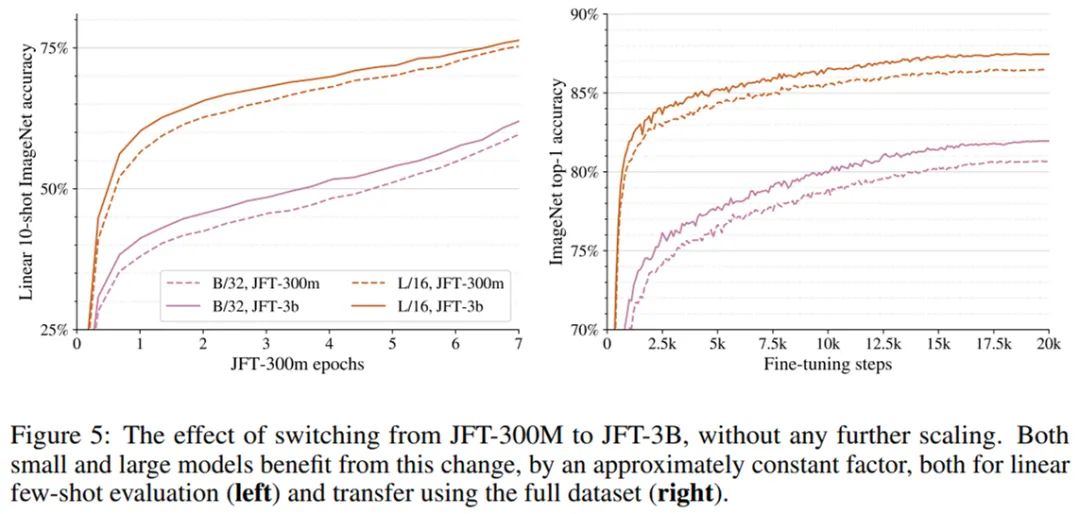
权重衰减对低数据情况下的模型自适应具有重大影响。研究者在中等规模程度上研究了这一现象,并发现可以从模型中最终线性层(「head」)和剩余权重(「body」)的权重衰减强度解耦中获益。下图 4 展示了这一效果。研究者在 JFT-300M 上训练了一个 ViT-B/32 模型,每个单元格对应不同 head/body 权重衰减值的性能。他们观察到的有趣的一点是:尽管提升了迁移性能,但 head 中高权重衰减却降低了预训练(上游)任务的性能。
对于 ViT 模型,当前的 TPU 硬件将 toek 维数填充为 128 的倍数,这可能导致高度 50% 的内存开销。为了解决这一问题,研究者尝试探索「使用额外[class] token」的替代方法。具体地,他们对全局平均池化( GAP)和多头注意力池化(MAP)进行评估以聚合来自所有 patch token 的表示,并将 MAP 中 head 的数量与模型其他部分中注意力 head 的数量设为相同。为了进一步简化 head 设计,研究者原始 ViT 论文中出现的、最终预测层之前的最终非线性映射。为了选择最佳 head,研究者对[class] token 和 GAP/MAP head 进行了并排比较,结果如上图 4(右)所示。他们发现,所有 head 的表现类似,同时 GAP 和 MAP 由于进行了填充(padding)考虑,因而具备更高的内存效率。此外,非线性映射还可以安全地进行移除。因此,研究者选择了 MAP head,这是因为其表现力最强,并且能够生成最统一的架构。在本文中,研究者选择了 ViT 模型,模型参数从 500 万到 2 亿,训练数据量从 3000 万到 30 亿。下表 2 为具体的模型架构细节: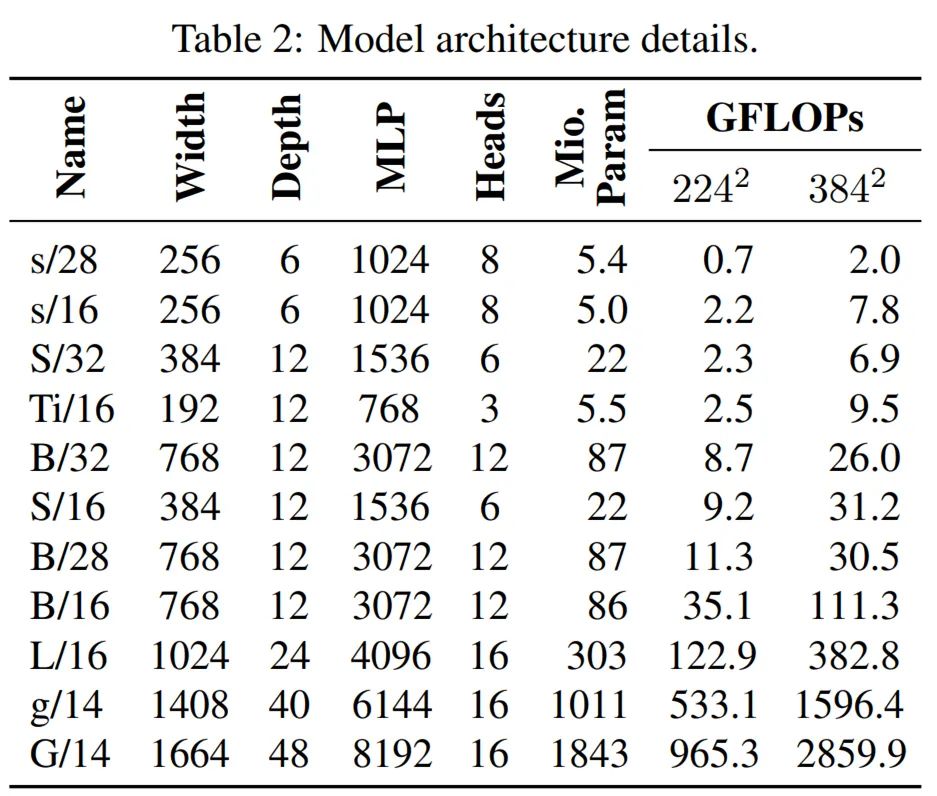
在接下来的实验中,研究者在多达 30 亿个弱标记图像上训练了几个 ViT 模型。研究者改变架构大小、训练图像的数量和训练持续时间。所有模型都在 TPUv3 上训练,因此总计算量是以 TPUv3 核每天(core-days)数来衡量的。为了评估由模型学习的表征的质量,研究者进行了一下测量(i)通过在固定权值上训练线性分类器来进行小样本迁移;(ii)通过对所有数据的整个模型进行微调,将其传递给多个基准测试任务。图 1 显示了在 ImageNet 上的 10-shot 线性评估和微调评估,并进行了高层级的观测。首先,将计算、模型和数据一起扩展可以提高表征质量。第二,模型尺寸会影响表征质量。第三,大型模型受益于额外的数据,甚至超过 1B 图像。
图 2 显示了在预训练期间「可见」的图像总数(批大小乘以 step 数)的表征质量。除了在公共验证集上进行 ImageNet 微调和线性 10-shot 结果外,研究者还报告了在 ImageNet-v2 测试集 [27] 上的 ImageNet 微调模型的结果,作为鲁棒泛化的指标。下图中展示了对 30 亿张图像进行预训练的三个 ViT 模型。
实验可得,有足够的数据,以较少的步骤训练一个更大的模型是可取的。该研究训练了一个大型的视觉 Transformer,ViT-G/14,它包含近 20 亿个参数。实验评估了 ViT-G/14 模型在一系列下游任务中的应用,并将其与 SOTA 结果进行了比较。研究者在 ImaegNet 上进行微调,并报告 ImageNet[28]、ImageNet-v2[27]、ReaL[3]和 ObjectNet[1]的准确率。此外,该研究还报告了在 VTAB-1k 基准上的迁移学习效果,该基准包括 19 个不同的任务[43]。图 3 显示了在 ImageNet 上进行小样本学习(few-shot learning)结果。由结果可得,ViT-G/14 比以前最好的 ViT-H/14 模型 [11] 表现优异(超过 5%),达到 84.86% 的准确率,每类 10 个例子。
下表 1 展示了其他基准上的结果。ViT-G/14 在 ImageNet 数据集上实现了 90.45% 的 Top-1 准确率,成为新的 SOTA。此外,在 ImageNet-v2 上,ViT-G/14 比基于 EfficientNet-L2 的 Noisy Student 模型提升了 3%。在 ReaL 数据集上,ViT-G/14 略微优于 ViT-H 和 BiT-L,再次表明 ImageNet 分类任务性能可能达到了饱和点。在 ObjectNet 数据集上,ViT-G/14 大幅度优于 BiT-L,较 Noisy Student 模型提升 2%,比 CLIP 落后约 2%。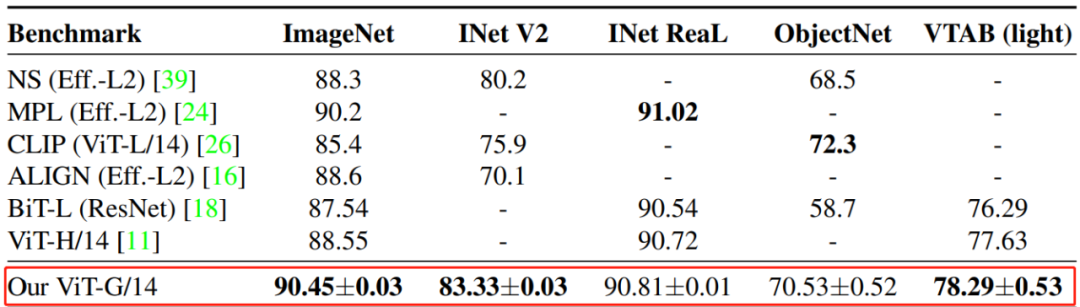
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

