
2分31秒,腾讯云创造128卡训练ImageNet新记录

新智元报道
新智元报道
来源:腾讯云
编辑:白峰
【新智元导读】8月21日,腾讯云正式对外宣布成功创造了128卡训练ImageNet业界新记录,以2分31秒的成绩一举刷新了这个领域的世界记录。

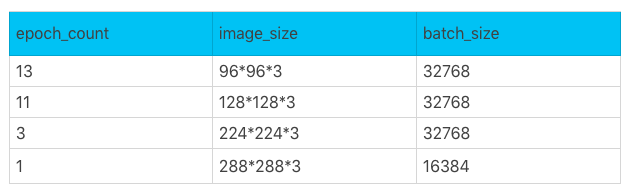
模型越来越大,算力需求暴涨
数据供给制约计算
TCP网络下的多机多卡扩展性差
大batch收敛难
超参数选择多
联合团队研发了 Light大规模分布式多机多卡训练框架来进行高效训练,并将能力平台化。
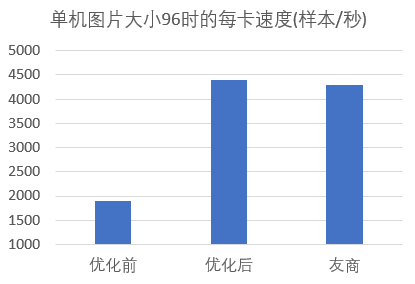
单机训练速度优化
1)分布式缓存与数据预取
2)自动调整最优数据预处理线程数
3)本地预解码图片缓存
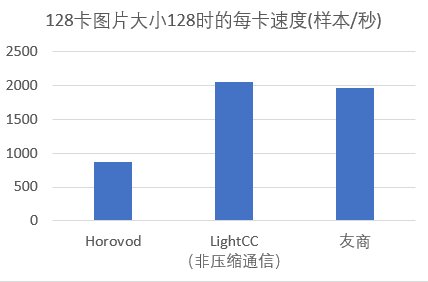
LightCC高效扩展多机训练

1)自适应梯度融合技术优化通信时间
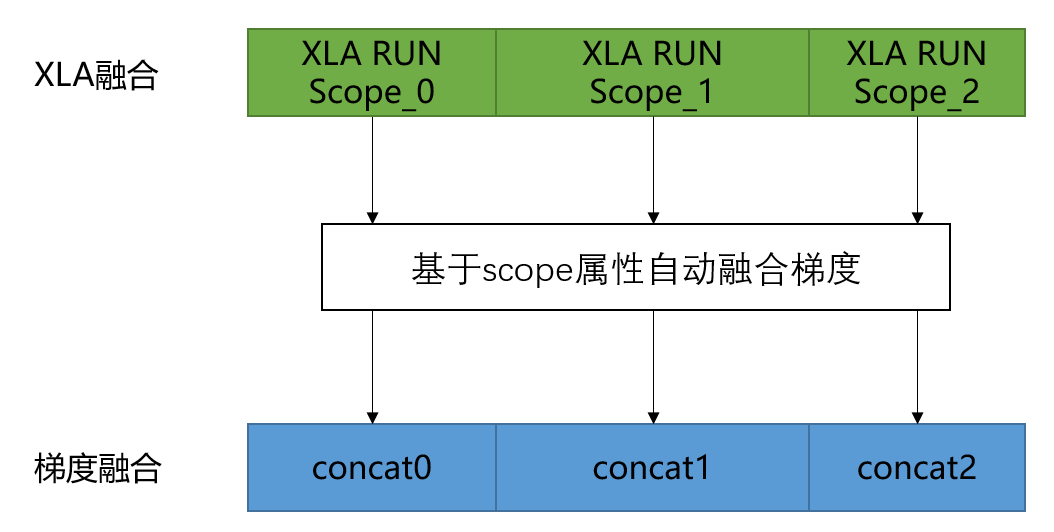
2)层级通信+多流提升带宽利用率

3)层级topk压缩通信算法减少通信量,突破带宽瓶颈

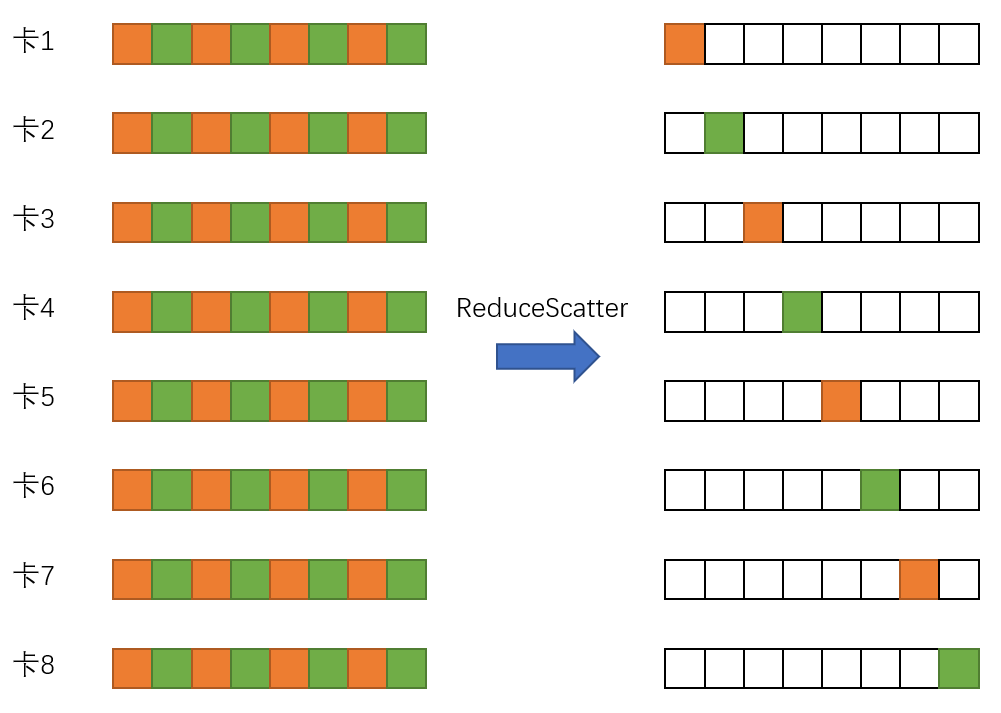

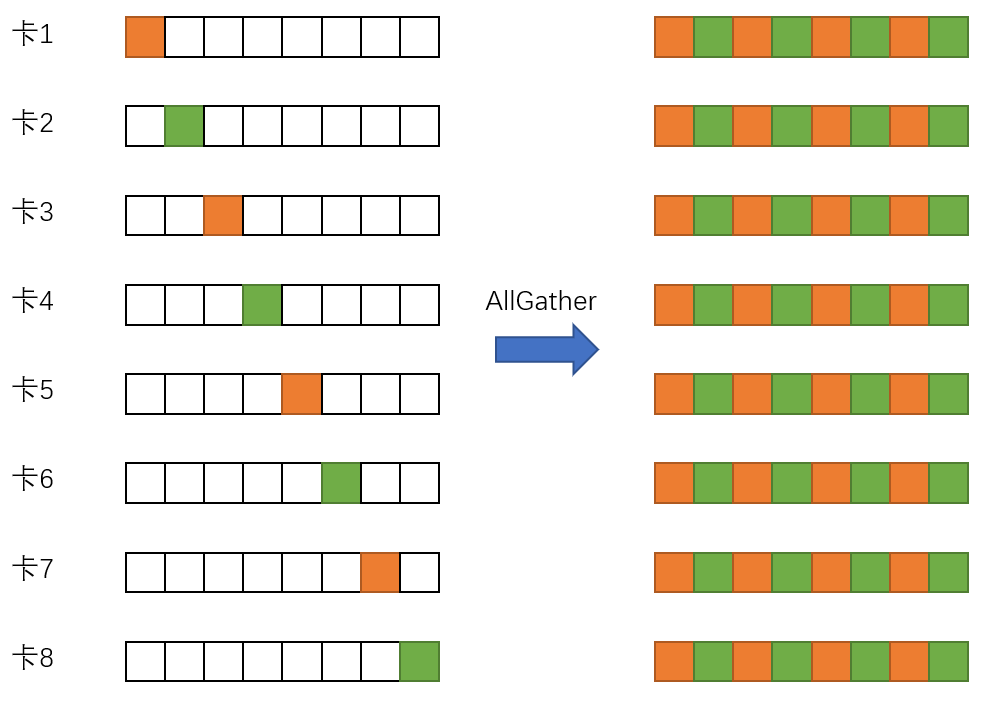
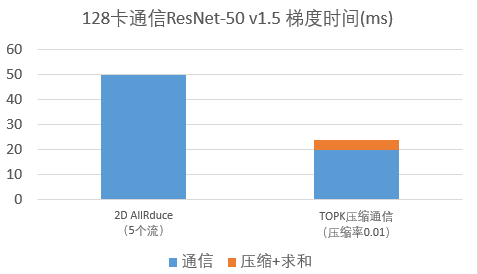
4) LARS计算并行化
大batch收敛
1)大batch调参策略
2)梯度压缩精度
3)AutoML调参

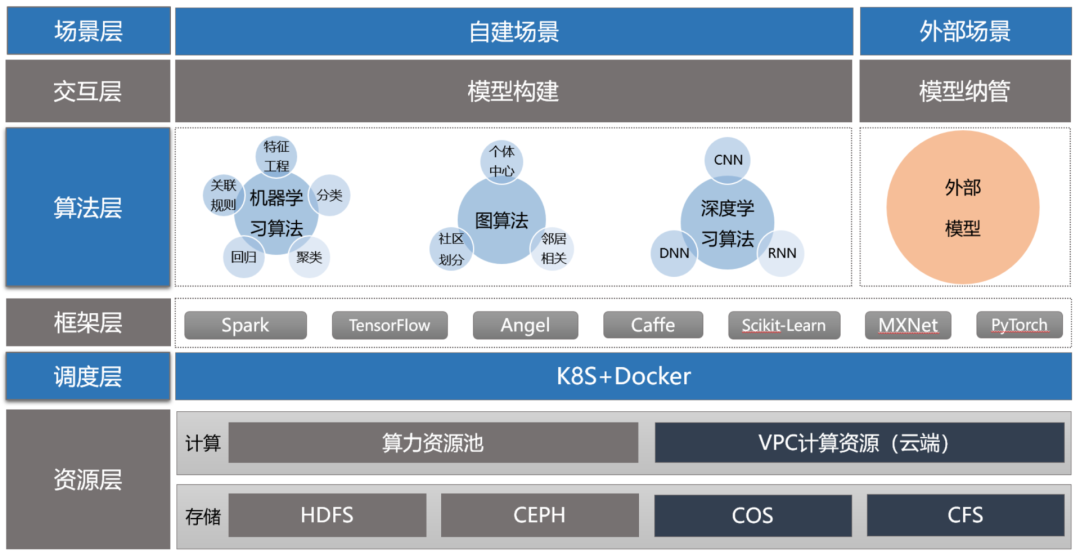
4.4 高性能机器学习平台——智能钛
单机优化
多机扩展

收敛
在收敛精度方面,通过手动设置超参与AutoML调参相结合,在28个epoch将top5精度训练到93%。
2分31秒训练ImageNet
在2分36秒内训练 ImageNet 28个epoch,TOP5精度达到93%;使用压缩通信后,在精度达到93%情况下,时间进一步减少到2分31秒,刷新了业界最好成绩,创造了业界新记录。若跨机网络改为RoCE,则训练时间再进一步减少到2分2秒。
构建稳定、易用、好用、高效的平台和服务,将成为算法工程师的重要生产力工具,也会助力游戏AI、计算机视觉AI,广告推荐AI、翻译AI、语音ASR AI等典型AI业务从一个成功走向另一个更大的成功。
本次破纪录的ImageNet训练,由腾讯机智团队、腾讯云智能钛团队、腾讯优图实验室、腾讯大数据团队和香港浸会大学计算机科学系褚晓文教授团队协同优化完成。
参考链接:

评论