
ImageNet 的衰落
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


我做了一个机器学习示例,它使用了曾经最受欢迎的ImageNet 数据集,这是目前每个机器学习从业者都知道的经典图像分类问题。这是一张图片,对1000个类别中的哪一个进行分类。
但这次我注意到了一些奇怪的地方,首先网站崩溃了,当它恢复时,一切都变了,ImageNet 维护者修改了数据集中的每一张图像,以模糊人脸。
这一决定背后的理由是崇高的,他们想让数据集更具“隐私意识”。今天,大多数最先进的计算机视觉模型都在 ImageNet 上进行了预训练,它们所呈现的自然情境和对象为大多数计算机视觉问题提供了强有力的基础。
研究小组发布的一篇关于ImageNet中人脸模糊处理的研究报告,告诉了我们原因。日常图像共享,通常包含敏感信息,向公众发布大型数据集显然会带来许多潜在的巨大隐私风险。由于 ImageNet 的挑战不是识别人,而是识别物体,因此团队决定进一步模糊数据集中人的面孔,最后,他们修改了 243,198 张图片。

我们很难找到一个不同意保护人们隐私的人,数化据匿名是数据科学的核心部分,可以保护从个人身份到健康记录的所有内容。
在机器学习中,我们有机会以安全为核心。互联网起源于一个不同的时代,在这个时代,安全和隐私是人们事后才想到的,互联网的创造者看不到所有可能出错的事情。但是今天,我们可以看到这些问题离我们很近,我们现在可以通过将隐私和安全作为数据科学的核心来解决这些问题。
但是有一个问题,如果我们想把隐私保护作为机器学习的中心,那么我们必须接受我们的数据会不断变化,并导致我们面临更大的问题。
机器学习中存在再现性危机,而且这种危机只会越来越大。
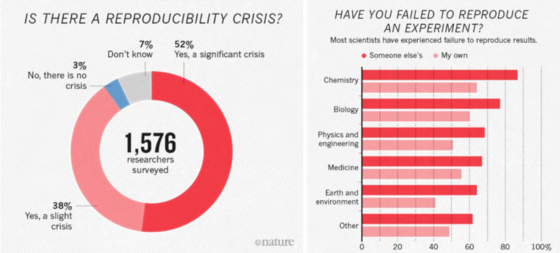
Nature 2016 年再现性调查主要结果
再现性是科学方法的基础,为了从化学和量子力学方面获得可靠的见解,我们依赖于再现性,机器学习也不例外。作为计算机视觉背后的主要技术,神经网络在规模和复杂性上都有了巨大的发展,通常需要大量的GPU集群、大量的数据集,以及对训练过程进行微妙的调整,而这些往往没有在出版物中报道。即使发布了源代码,复制研究的成本也可能使除了资金最雄厚的机构之外的所有机构都无法实现。
这个问题在机器学习研究中变得如此普遍,以至于 2019 年神经信息处理系统 (NeurIPS) 会议引入了一个再现性检查表,其中包含“数据集或模拟环境的可下载版本的链接”。
因此,我们遇到了困难,如果我们不能使用用于训练模型的原始数据集,我们就无法复制它。我们可以在新数据集上重新训练模型,但我们无法复制或与之前的研究进行比较。
这意味着所有建立在原始 ImageNet 上的模型现在都无法重新创建。十多年来每个人都引用和依赖的挑战不再能够作为标准的计算机视觉基准,因为数据集不一样。由于缺乏可再现性,ImageNet 已沦为基准计算机视觉数据集。
这就把我们带到了问题的关键,我们如何在允许数据包含隐私变更的同时保持再现性?
我们必须开始将数据放在首位,数据集开发阶段不再只是模型开发之前的一步,这是一个持续的过程,对我们的数据集的更改是不可避免的。从减少偏差到提高准确性,对我们的数据集的修改是不可避免的,我们需要接受数据更改而不是避免数据更改。
但这是否意味着我们失去了再现性?如果我们从一开始就考虑到这一点,那就不会了。我们已经习惯了这种代码思维方式,我们知道它是动态的,它会改变的。多人将就此进行合作,预计会有新功能、错误修复、性能改进的变化,我们也需要将这种想法扩展到数据。
但与在软件开发中编写代码不同,在机器学习中,我们有两个移动的部分,代码和数据,它们生成我们的模型。我在完成机器学习循环中写了大量关于这个主题的文章,重点是,我们需要支持能够在下图所示的每个“两个循环”中进行迭代的流程和工具。
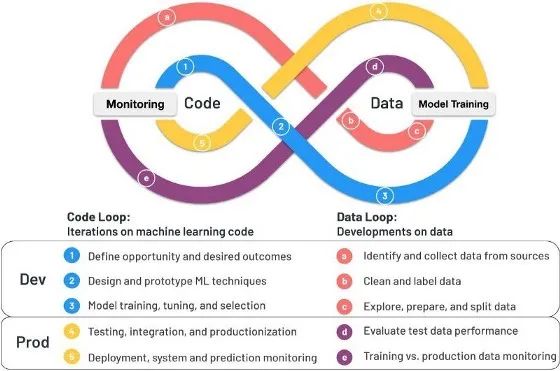
机器学习生命周期中的“两个循环”。在机器学习开发中,我们有两个移动部分需要组合在一起来生成我们的模型:代码和数据。两个循环代表每个循环的开发生命周期,每个循环都在不断迭代。
我们不仅需要能够迭代,还需要跟踪所有移动的部分以获得再现性。需要捕获对数据集的每次修改以及代码中的任何新训练技术,以再现由它们生成的模型,当我们的数据发生变化时,我们需要我们的实验过程来更新。
这就是Pachyderm 等工具的用处,Pachyderm 是一个具有内置版本控制和数据沿袭功能的数据科学和处理平台,它的核心是数据版本控制,以支持数据驱动的管道。它的功能就像一个“生命系统”,管道依靠输入数据来告诉它们何时开始。在我们的例子中,每当数据集被修改时,机器学习模型都会被训练,从而保持数据的安全性和模型的相关性。
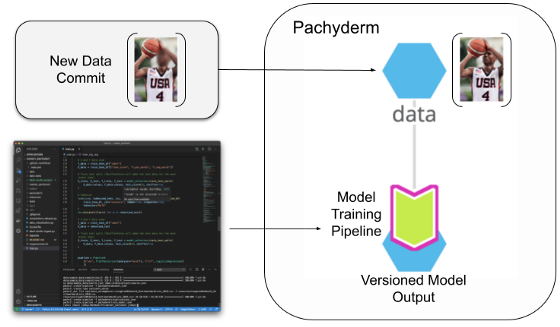
当新的模糊人脸图像提交到版本化数据存储库时,连接的管道会自动重新运行,以保持整个系统的可重现状态。
如果将 ImageNet 组织为 Pachyderm 中的数据集,则隐私感知版本可能会覆盖原始数据集。任何连接的模型训练管道,无论是原始 AlexNet 代码还是最先进的预训练模型,都将自动在新数据集上运行,为我们执行的任何实验提供完全可复制的模型,允许我们的数据更改并保持我们的再现性。
像 Pachyderm 这样将数据放在首位并考虑变化的工具对于将数据隐私引入 AI 来说至关重要,没有它们,我们会发现自己迷失在不断变化的数据和代码的复杂性中。
在现代化的世界中,数据隐私对于保护我们的安全至关重要。但是,数据隐私的改进往往是以牺牲再现性为代价的。
通过采用支持更改的工具,我们可以在不损害再现性的情况下将隐私更改纳入我们的数据集。Pachyderm 一直是我们管理不断变化的数据的首选工具,它极大地提高了在我的机器学习系统上迭代的可靠性和效率,这些类型的工具对于为 AI 的安全和可靠的未来铺平道路至关重要。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~