
全自动实时移动端AI框架 | YOLO-v4目标检测、换脸、视频上色全部实时手机端实现
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源:计算机视觉研究院
如何助力深度神经网络在移动端「看得」更清,「跑得」更快?来自美国东北大学等机构的研究者提出一种新型全自动模式化稀疏度感知训练框架。
基于模式化稀疏度的剪枝方法能够使深度神经网络在图像识别任务中「看得」更清楚,同时减小了模型尺寸,使模型在移动端「跑得」更快,实现实时推理。 论文地址:https://arxiv.org/abs/2001.07710
官方网站:https://www.cocopie.ai/
B 站:https://space.bilibili.com/573588276

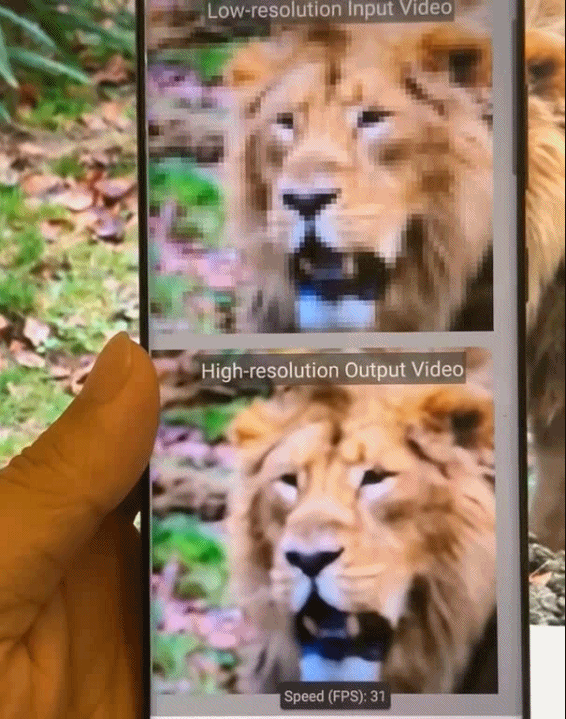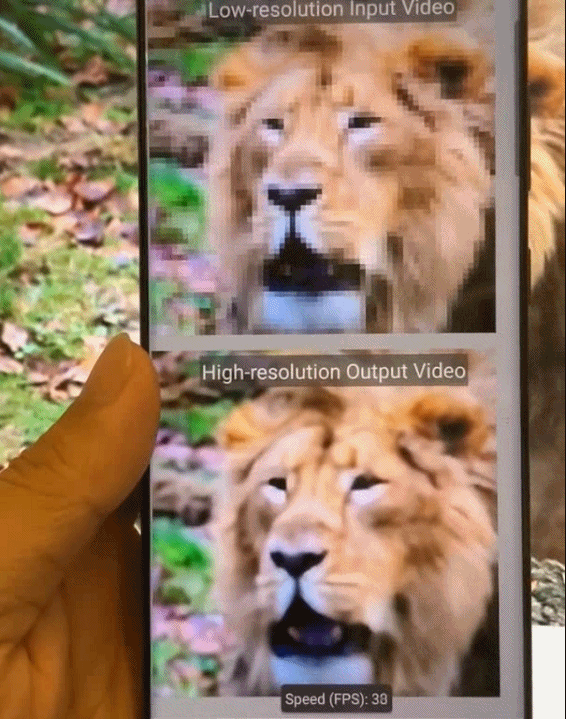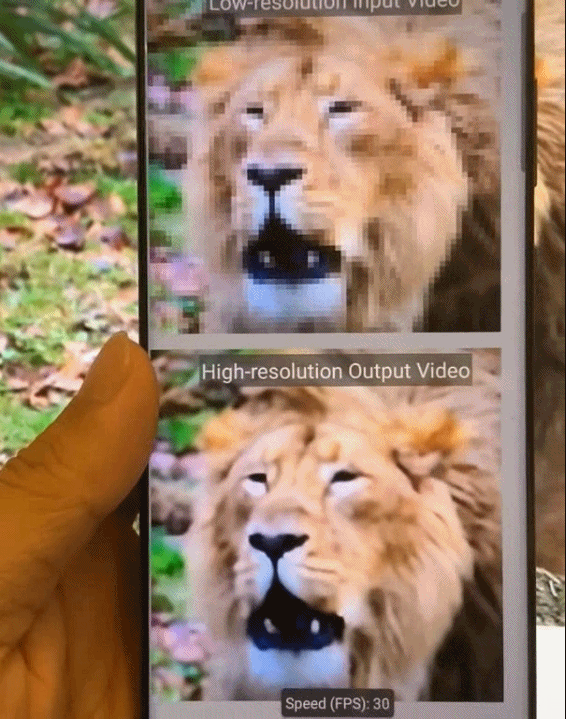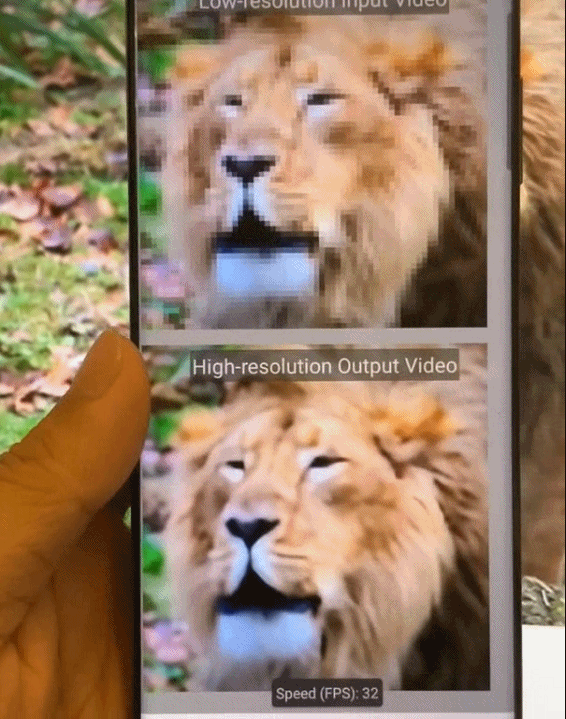



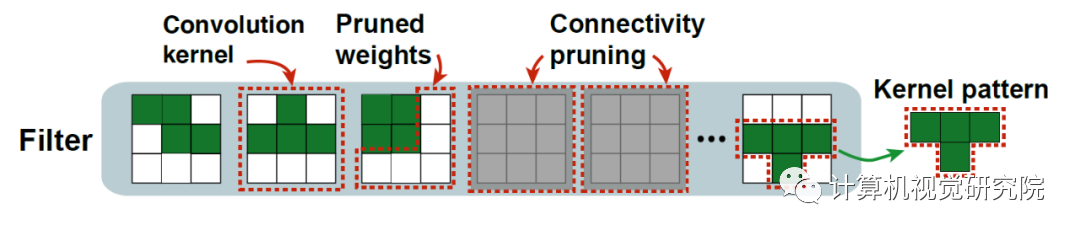


图3.卷积核模式设计。


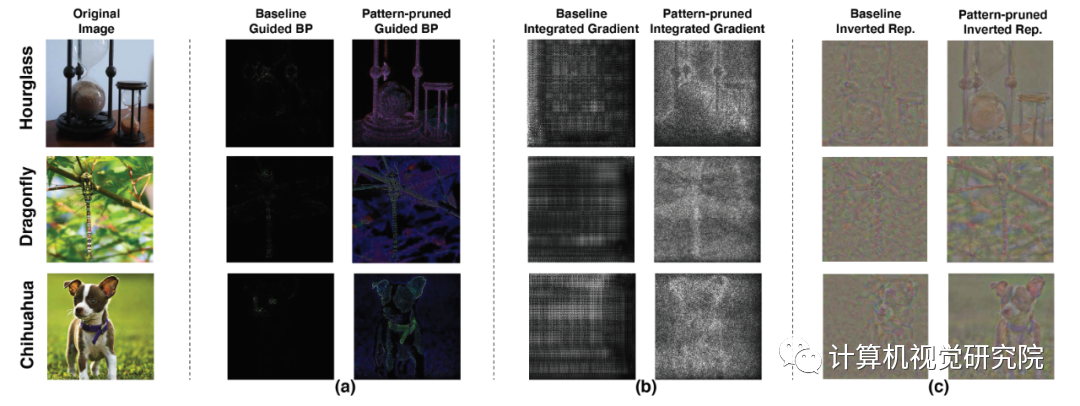
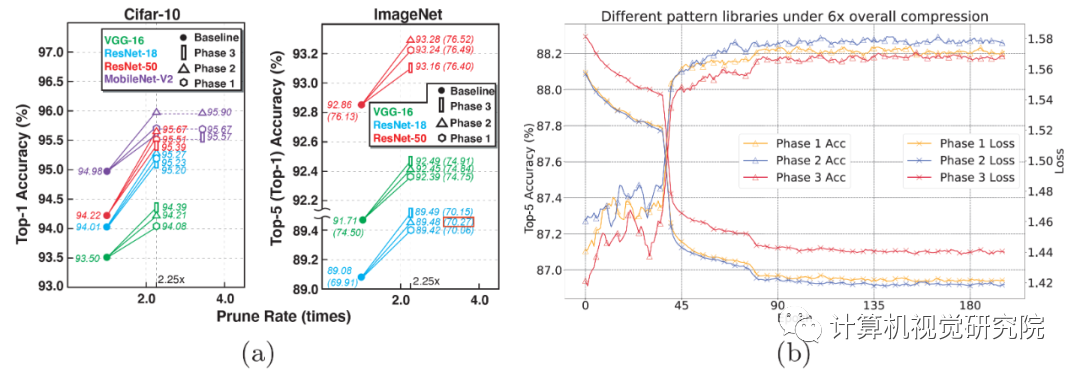


图8.基于Phase 2模式集的稀疏化深度神经网络模型在移动端的加速效果展示图。

图9.基于模式化剪枝与通用型移动端推理框架在手机端不同AI应用场景的执行效果示意。从左到右依次为:相机超分辨率拍摄、实时相机风格迁移、视频实时上色、AI换脸。

图10.基于模式化剪枝与通用型移动端推理框架在手机端的执行效果图。从左到右依次为,实时相机风格迁移、视频实时上色、相机超分辨率拍摄。
/End.
下载1:OpenCV黑魔法
在「AI算法与图像处理」公众号后台回复:OpenCV黑魔法,即可下载小编精心编写整理的计算机视觉趣味实战教程
下载2 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

觉得有趣就点亮在看吧
评论