
YOLO-v4目标检测实时手机端实现
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
转自 | 计算机视觉研究院


1 所示,研究人员可视化了 VGG-16 在 ImageNet
上的预训练模型的部分权重,并且发现(i)卷积核的有效面积(即具有较高绝对值的权重)形成一些特定形状并在模型中反复出现,(ii)某些卷积核的权重值非常小,因此并不能对输出产生有效的激活,研究人员认为这种卷积核是无效卷积核。

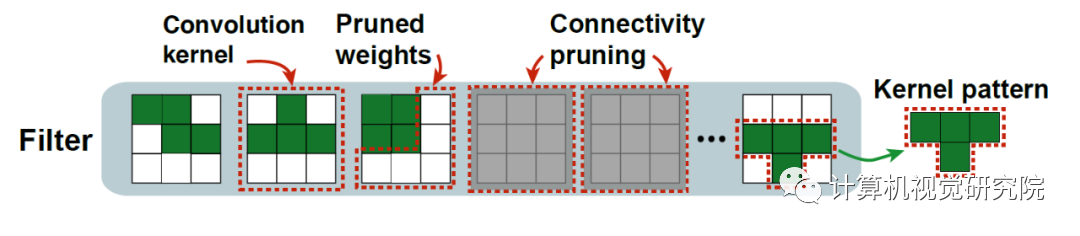
library),并将加入掩膜看作一种对神经网络的插值操作。通过不同模式的掩膜插值,得到一些功能性图像滤波器特征,能够实现图像的锐化与降噪,提高图像质量。值得一提的是,插值操作的过程仅需要少量种类的卷积核模式(或者说一个小尺寸的模式集)。


图3.卷积核模式设计。
ADMM(alternating direction method of multipliers)将原始剪枝问题解耦为
Primal-Proximal 问题,迭代式地通过传统梯度下降法求解 Primal 问题,并引入一个二次项迭代求解 Proximal
问题。通过每次 Primal-Proximal
迭代更新,使卷积核动态地从模式集中选择当前最优的卷积核模式,并同时通过梯度下降法训练该模式非零位置的权重。当卷积核对稀疏模式的选择趋于稳定的时候(一般仅需要迭代
3-5
次),就可以删除掉那些被选择次数非常少的卷积核模式,从而将模式集的大小降低,并用更新后的模式集进行下一轮迭代,最终实现模式集的自动提取。
10%-20%。当训练集的大小足够小的时候,我们便可以用比常规训练时长减少 20%
左右的训练时间完成训练。从实验结果来看,完成模式集提取、模式化稀疏度选择与模型训练的总时长甚至可以少于大部分其他模型剪枝工作。
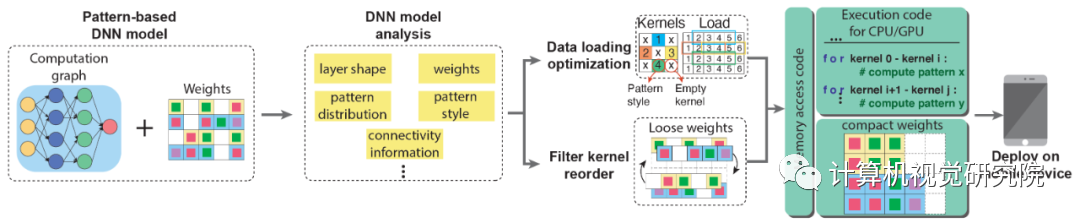
AI 实时推理,满足用户需求。
5 展示了卷积核模式集提取结果。研究人员首先确定了每一个卷积核中应保留 4 个非零值,这样做的好处是控制模式集总集的大小,同时也利于移动端
CPU/GPU 的 SIMD 结构。当经过两次模式集提取后,模式集总集大小从 126 减小到 32 个,这时的模式集中卷积核模式分布图如图
5(b)所示。研究人员进一步训练并删除出现次数最少的卷积核模式后,得到了 Phase 1、2、3 模式集,其中的卷积核模式数量分别为
12、8、4,如图 5(a)所示。可以发现,Phase 2
模式集所含的卷积核模式与理论推导与八种卷积核模式完全匹配。因此研究人员得出结论,基于理论得出的卷积核模式也是算法实现层面上对于深度神经网络最优的卷积核模式。

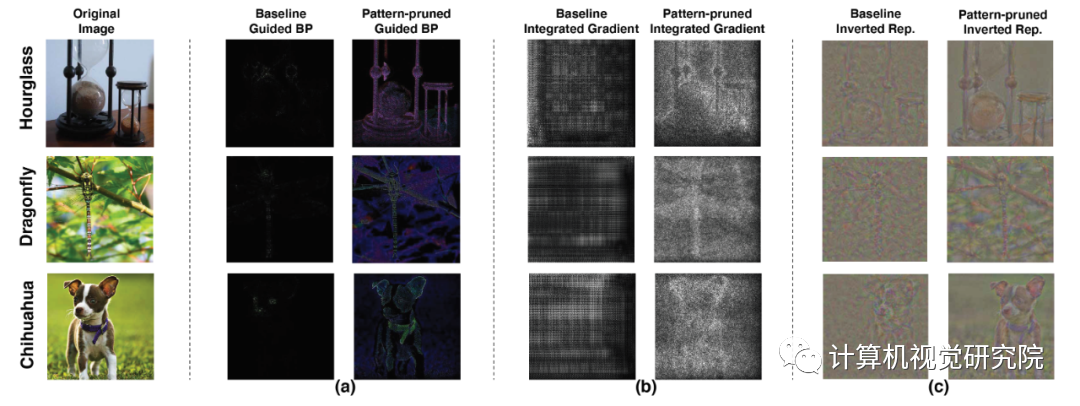
6. 基于 VGG-16 在 ImageNet 上剪枝后的模型可视化效果图。此处采用了三种不同的可视化方法:(a)
guided-backpropagation (BP) ,(b) integrated gradients, (c) inverted
representation。
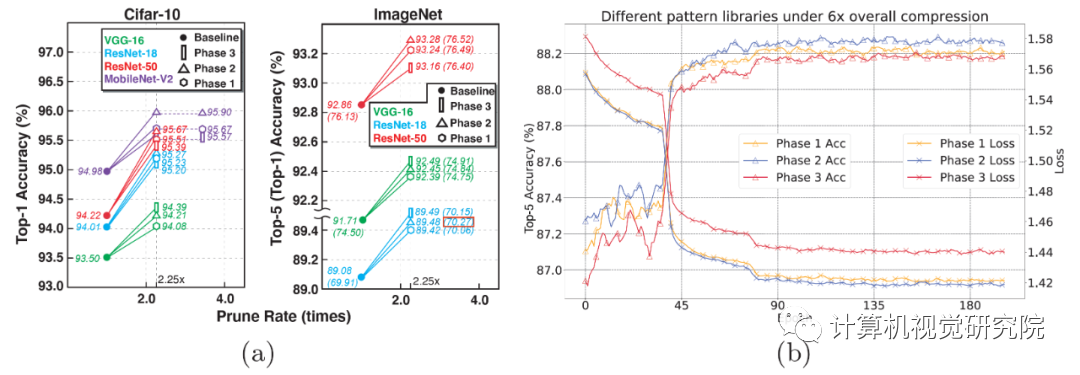
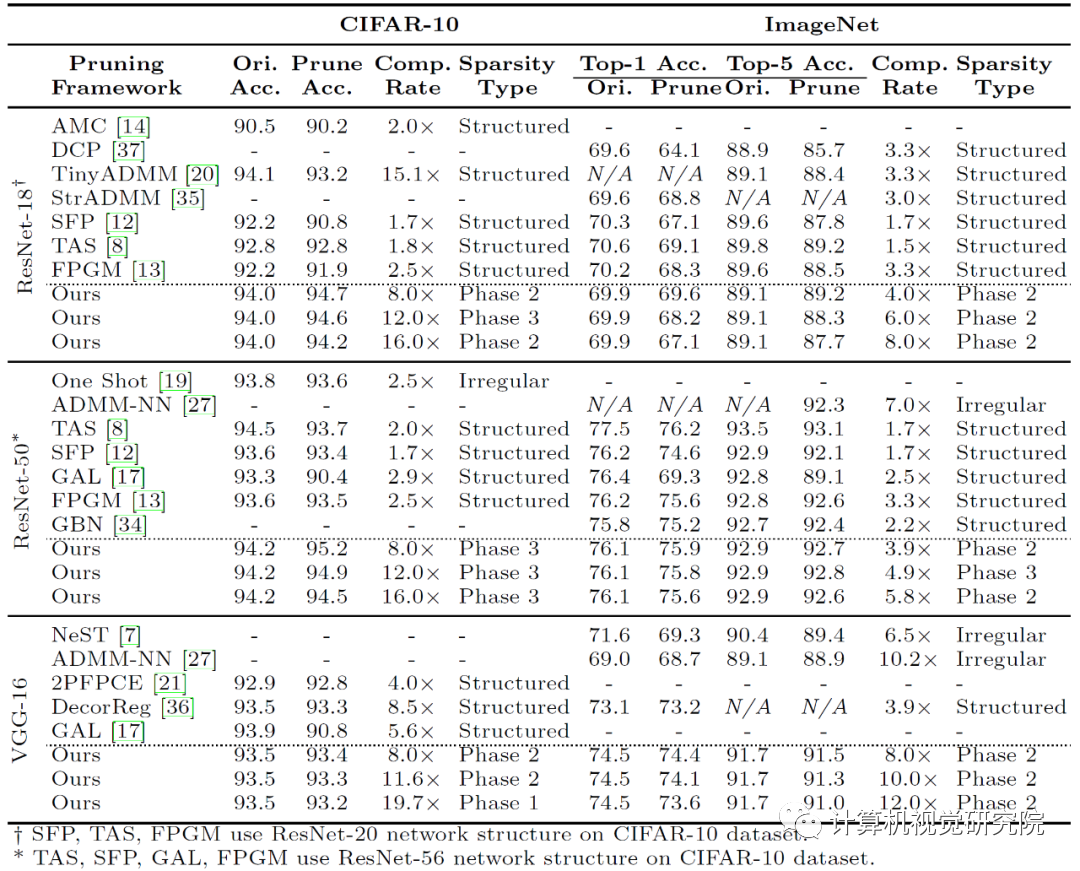
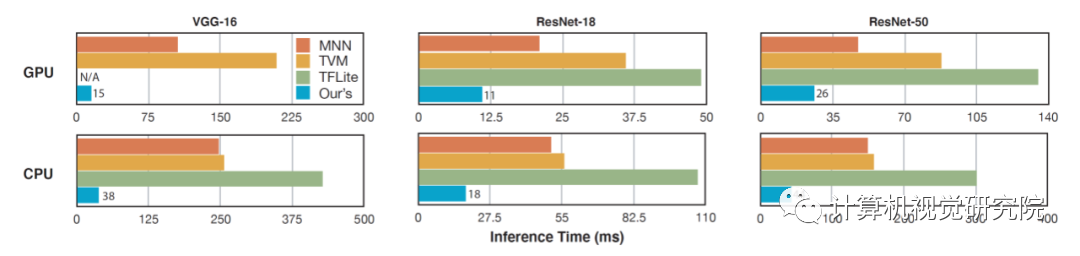
图8.基于Phase 2模式集的稀疏化深度神经网络模型在移动端的加速效果展示图。
frames/second,即 33ms/second)。例如,在大型神经网络 VGG-16 上,该方法的推理时间仅为
15ms。这一对于最优的模式化剪枝方法与通用型的移动推理框架的研究使得在移动端对任意神经网络进行实时运算变为可能。

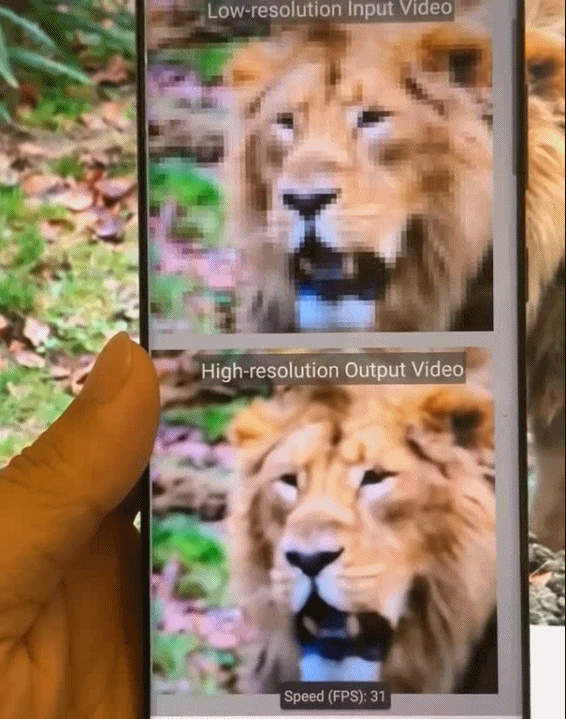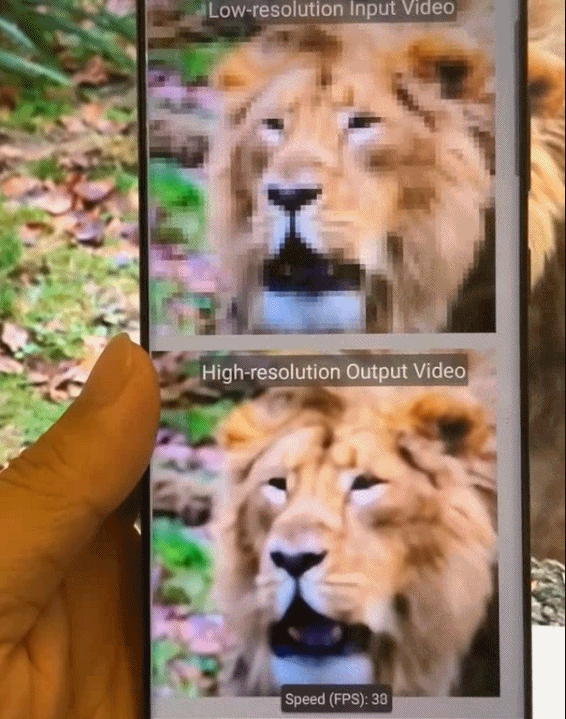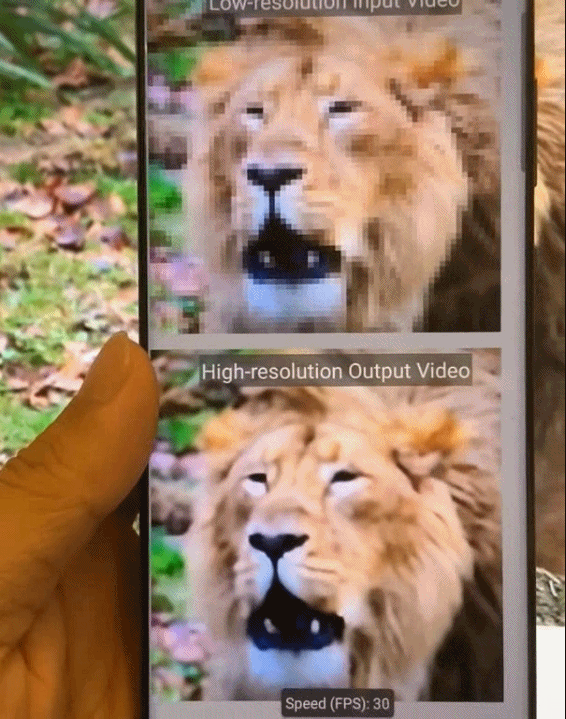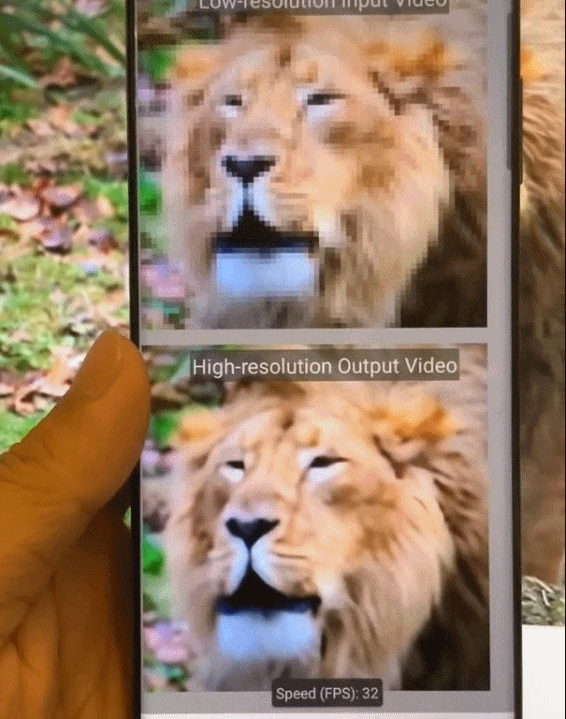
图9.基于模式化剪枝与通用型移动端推理框架在手机端不同AI应用场景的执行效果示意。从左到右依次为:相机超分辨率拍摄、实时相机风格迁移、视频实时上色、AI换脸。

图10.基于模式化剪枝与通用型移动端推理框架在手机端的执行效果图。从左到右依次为,实时相机风格迁移、视频实时上色、相机超分辨率拍摄。

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论