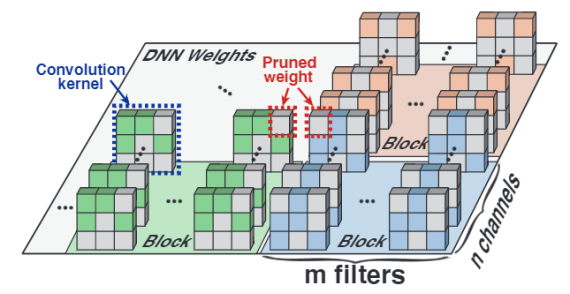
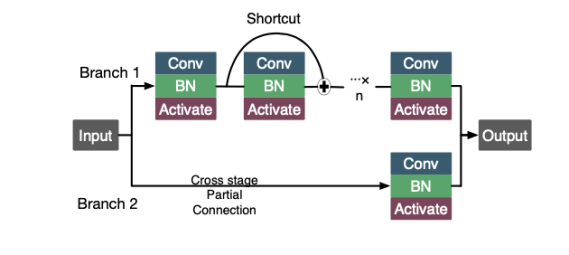
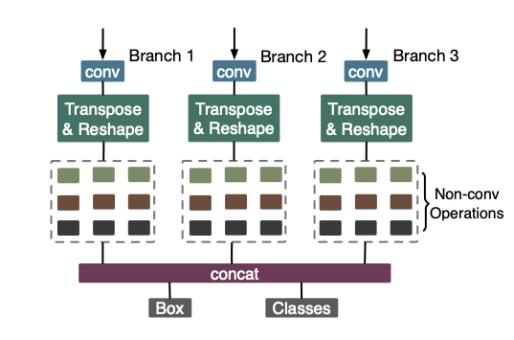
(附代码)YOLObile:手机端19FPS的实时目标检测算法
点击左上方蓝字关注我们

转载自 | 机器之心
开源的模型与训练代码:https://github.com/nightsnack/YOLObile
论文链接:https://arxiv.org/abs/2009.05697
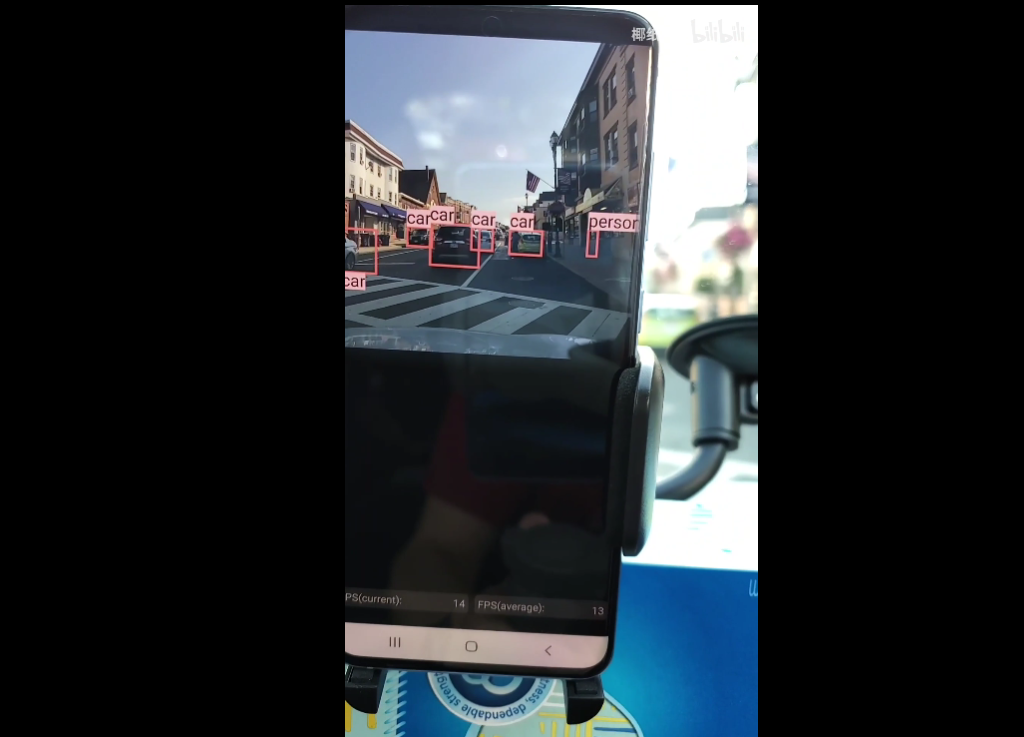
demo链接 · B 站(还有更多应用的 demo):https://www.bilibili.com/video/BV1bz4y1y7CR
END
整理不易,点赞三连↓
评论
 下载APP
下载APP点击左上方蓝字关注我们
转载自 | 机器之心
开源的模型与训练代码:https://github.com/nightsnack/YOLObile
论文链接:https://arxiv.org/abs/2009.05697
demo链接 · B 站(还有更多应用的 demo):https://www.bilibili.com/video/BV1bz4y1y7CR
END
整理不易,点赞三连↓