
目标检测顶流的碰撞 | YOLOv5+DETR成就地表最强目标检测器DEYO...

目标检测是计算机视觉中的一个重要课题,后处理是典型目标检测流水线的重要组成部分,这对传统目标检测模型的性能造成了严重的瓶颈。作为首个端到端目标检测模型,DETR摒弃了Anchor和非最大抑制(NMS)等手动组件的要求,大大简化了目标检测过程。
然而,与大多数传统的目标检测模型相比,DETR收敛速度非常慢,query的含义也很模糊。因此,受Step-by-Step概念的启发,本文提出了一种新的两阶段目标检测模型,名为DETR with YOLO(DEYO),该模型依赖于渐进推理来解决上述问题。DEYO是一个两阶段架构,分别包括经典目标检测模型和类DETR模型作为第一和第二两阶段。
具体而言,第一阶段向第二阶段提供高质量的query和Anchor反馈,与原始DETR模型相比,提高了第二阶段的性能和效率。同时,第二两阶段补偿由第一两阶段检测器的限制引起的性能下降。
广泛的实验表明,DEYO在12和36个Epoch分别达到50.6 AP和52.1 AP,同时利用ResNet-50作为COCO数据集的主干和多尺度特征。与DINO相比,DEYO模型在2个Epoch的设置中提供了1.6 AP和1.2 AP的显著性能改进。
1、简介
目标检测涉及一个过程,其中检测器识别图像中的感兴趣区域,并用边界框和类标签对其进行标记。经过多年来对经典目标检测器的大力发展,已经开发出了几种优秀的单阶段和两阶段目标检测模型。检测器通常包括两部分,即用于预测物体类别和边界框的主干和头部。最近的架构在主干和头部之间插入层,以收集不同阶段的特征图。这些层被称为物体检测器的颈部。
R-CNN系列是最具代表性的两阶段目标检测器,包括Fast R-CNN和Faster R-CNN。最具代表性的单阶段目标检测模型是YOLO[4,5,6]、SSD和RetinaNet。这些经典目标检测器的一个共同特点是严重依赖手工设计的组件,如Anchor和非最大抑制(NMS),NMS是一个去除冗余边界框的后处理过滤器。近年来,Anchor-Free方法,如CenterNet、CornerNet和FCOS,已经取得了与Anchor-Base的模型相当的结果。然而,Anchor-Base和Anchor-Free的两种方案都利用非最大抑制进行后处理,这给经典检测器带来了瓶颈。此外,由于非最大抑制不使用图像信息,因此在边界框保留和删除中容易出错。
经典的检测器主要基于卷积神经网络。DETR依靠基于Transformer的编码器-解码器架构来消除对Anchor和NMS手动组件的依赖。此外,DETR使用匈牙利损失直接预测一对一对象集,简化了目标检测流程。尽管DETR有许多吸引人的特性,但它存在一些问题。首先,DETR需要500个训练周期才能达到吸引人的表现。此外,DETR的query很模糊,无法充分利用。
应该指出的是,已经提出了一系列基于DETR的变体模型,很好地解决了上述问题。例如,通过设计新的注意力模块,Deformable DETR专注于参考点周围的采样点,以提高交叉注意力的效率。Conditional DETR将DETR query分离为content和location部分,以澄清query的含义。此外,DAB-DETR将query视为4D Anchor,并逐层改进。基于DAB-DETR,DN-DETR表明,DETR训练的缓慢收敛是由于早期训练阶段的二分图匹配不稳定性。因此,引入去噪组技术显著加速了DETR模型的收敛。
在上述模型的推动下,DINO通过使用Object365进行检测预训练和使用Swin Transformer作为主干网络,进一步改进了DETR。事实上,DINO在COCO val2017数据集上获得了63.3AP的最新(SOTA)结果。目前,DINO在类DETR模型中具有最快的训练收敛速度和最高的精度,并证明类DETR的检测器实现了与经典检测器同等的性能,甚至优于经典检测器。
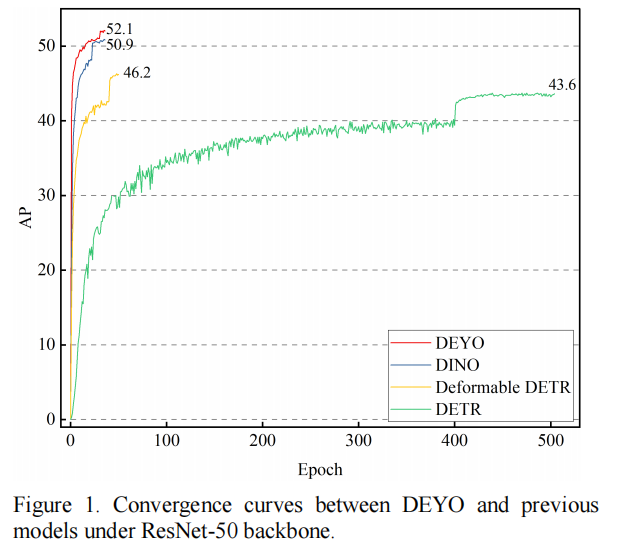
尽管相关工作显著改进了类DETR模型,但作者仍然认为类DETR模型很难直接预测一对一的对象集。经典检测器,如YOLOv5,可以在640x640像素的图像中生成25200个预测作为其输出。假设DETR使用的Transformer模型计算与query数成正比,则类DETR模型的query数通常在100到900之间。显然,单个YOLO预测的计算负担比类DETR模型低得多。因此,受“循序渐进”思想的启发,作者使用低成本和高质量的YOLO预测作为第二阶段类DETR模型的输入,以降低预测一对一对象集的难度。该策略为类DETR模型提供了有限数量的query,以专注于具有挑战性的任务,例如难以识别的目标和严重遮挡的目标,从而提高了整体性能。
本文提出了一种新的基于渐进推理的两阶段目标检测模型。具体而言,本文的模型将YOLOv5用作第一阶段,将类似DETR的模型用作第二阶段。YOLO模型的输出由过渡组件处理,包括目标和边界框信息,然后将其传递给类DETR模型。YOLO的高质量初始化query、anchor和DETR的初始化query以及初始化的anchor被组合,然后被发送到Transformer的解码器。
实验结果表明,所开发模型的第二阶段解码器可以容易地识别来自第一阶段的信息。事实上,类似DETR的模型更多地关注于微调初始边界框、验证和调整类别,以及预测NMS由于严重遮挡而错误滤除的目标或第一阶段检测器无法轻易识别的目标。此外,由于存在高质量的初始化query和anchor,优化目标在第二阶段中为query和anchor都进行了初始化。第二阶段的二分图匹配的不稳定性进一步降低,训练时间大大加快。
所提出的两阶段网络是相辅相成的,因为模型的第一阶段为第二阶段提供了高质量的初始化,以便后一阶段能够快速地关注难以学习的信息。这一概念加速了类DETR模型的收敛,提高了它们的峰值性能。第二阶段模型对第一阶段模型进行微调,以获得更好的结果。因此,所提出的模型补偿了由于NMS限制导致的经典检测器的性能下降,从而使模型能够识别严重遮挡的目标。这是第一个将渐进推理引入类DETR检测模型的工作。本文的贡献总结如下:
设计一个新的两阶段模型,灵感来源于循序渐进的思想。实验结果表明,这种渐进推理显著降低了预测一对一目标集的难度。此外,从一个新的角度来看,类DETR模型的训练收敛时间显著减少,同时模型的精度提高到一个新水平。
克服了经典检测器因NMS而遭受的瓶颈性能问题。此外,在解决了基于NMS的性能瓶颈问题之后,分析了经典检测器的潜在性能。
进行几个实验,验证了想法,并探索模型中每个组件的贡献。
2、相关工作
2.1、YOLO
多年来,YOLO[4,5,6]系列一直是最好的单阶段实时目标检测器类别之一。YOLO可以在许多硬件平台和应用场景中找到,满足不同的需求。经过多年的发展,YOLO已经发展成为一系列性能良好的快速模型。Anchor-Base的YOLO方法包括YOLOv4、YOLOv 5和YOLOv7,而Anchor-Free方法是YOLOX、YOLOR和YOLOv6。考虑到这些检测器的性能,Anchor-Free方法的性能与Anchor-Base的方法一样好,Anchor不再是限制YOLO发展的主要因素。
然而,所有YOLO变体都会产生许多冗余边界框,NMS必须在预测阶段过滤掉这些边界框,这可能导致性能瓶颈。在本文的模型中,这个问题得到了一定程度的改善。
2.2、NMS
NMS是经典目标检测管道的重要组成部分,旨在从一组重叠框中选择最佳边界框。NMS根据得分对所有边界框进行排序。选择得分最高的边界框M,并抑制与M重叠超过阈值的所有其他边界框。近年来,一些工作试图改进NMS,如Soft-NMS、Softer-NMS和Adaptive-NMS。然而,这些都不能克服NMS的固有问题,即过滤掉冗余边界框不考虑图像信息。
NMS的一个主要问题是,它将相邻检测的分数设置为零,如果在该重叠阈值中实际存在一个目标,则该目标将被忽略,这将导致平均精度下降。因此,模型的泛化能力在一定程度上受到限制,影响了模型在复杂任务中的性能。
2.3、DETR and its variants
DETR由于其端到端的目标检测特性而引起了研究人员的注意。具体而言,DETR去除了传统检测流水线中的Anchor和NMS组件,采用二分图匹配的标签分配方法,并直接预测一对一对象集。该策略简化了目标检测过程,并缓解了NMS引起的性能瓶颈问题。
此外,引入Transformer架构使边界框过滤在图像和目标特征之间具有交互作用,即DETR的目标过滤结合了图像信息,使DETR能够正确地保留和删除框。然而,DETR存在收敛速度慢和query模糊的问题。
为了解决这些问题,已经提出了许多DETR变体,如Conditional DETR、Deformable DETR和DAB-DETR,DN-DETR和DINO。例如,Conditional DETR将query分离为content和location部分,而Deformable DETR提高了交叉注意力的效率。DAB-DETR将query解释为4-D Anchor框,并学习逐层改进它们。DN-DETR在DAB-DETR的基础上,引入了一个去噪组来解决不稳定的二分图匹配问题,显著加快了模型训练的收敛速度。DINO是一个类似DETR的模型,它进一步改进了以前的工作并实现了SOTA结果。
2.4、Let’s think step by step
通过使用特定提示“Let’s think step by step”和相应的两阶段提示技术,Zero-shot-CoT提高了大规模语言模型在几个与推理相关的Zero-shot任务上的推理能力,优于以前的Zero-shot方法。“Let’s think step by step”分步方案鼓励模型对难以直接提供正确答案的复杂任务进行分步推理,并使模型能够计算出结果;否则无法正确给出的答案。
受Step-by-Step的启发,本文的模型的第一阶段预测简单任务而不是最终推理,类似于语言模型中的“intermediate inference step”。第二阶段侧重于第一阶段从“intermediate inference step”中给出的困难任务,并降低了难度,允许模型预测否则将无法正确识别的目标。
3、Why is Step-by-Step effective?
3.1、High-quality query initialization speeds up training
DETR采用匈牙利匹配算法直接预测一对一对象集。然而,有证据表明,由于blocking pairs,匈牙利匹配会导致匹配不稳定。由于代价矩阵的微小变化,最终匹配结果将发生显著变化,从而导致在训练的早期阶段解码器query的优化目标不一致。这显著增加了训练难度,这是DETR收敛速度慢的关键原因之一。
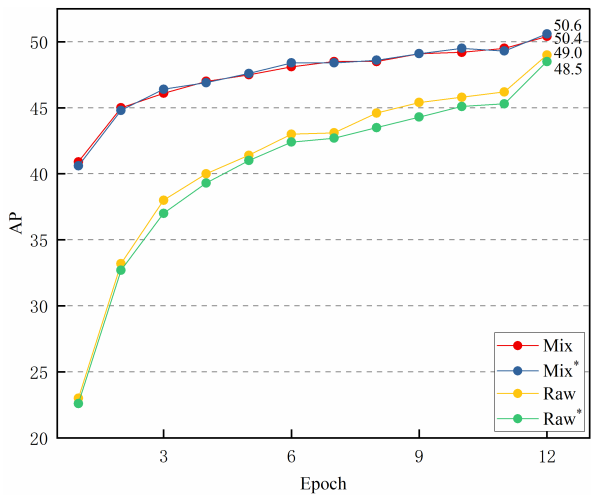
因此,将高质量的query和anchor输入到解码器中。如图4(b)所示,本文的模型在第一个epoch就实现了40.6 AP,这表明解码器可以很容易地学习在高质量query和anchor中获取信息,帮助模型明确其优化目标,并避免匈牙利匹配导致的歧义。因此,由于不稳定的匈牙利匹配而导致的缓慢训练收敛显著减少。
3.2、Breaking through the performance bottleneck caused by NMS
在预测阶段,经典检测器生成冗余边界框,这些边界框必须被NMS抑制和过滤掉。然而,NMS过滤算法不整合图像信息,而是通过根据不同的任务调整不同的IoU阈值来优化过滤,这在保留和删除框时容易出错。因此,在不使用NMS的情况下研究了YOLOv5x的潜在性能。在图2中,显示了使用具有不同Iou阈值的NMS的25200个预测的640x640大小图像的YOLOv5的后处理性能。
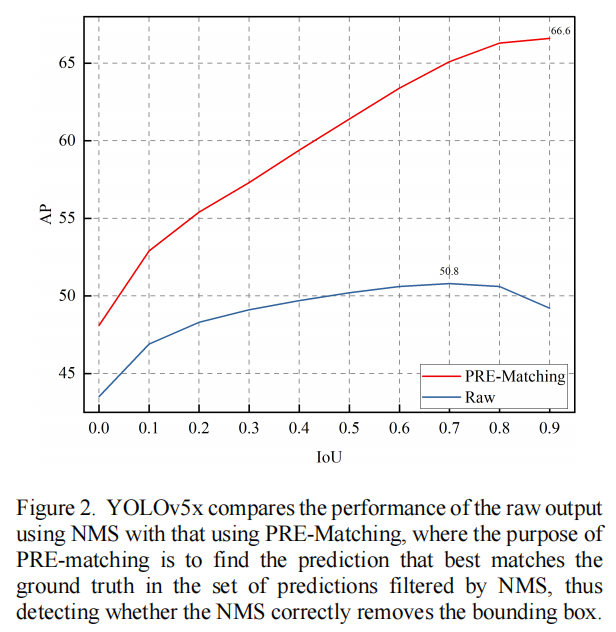
结果表明,随着IoU阈值的增加,在NMS之后使用预匹配滤波的预测性能将逐渐提高。此外,没有预匹配滤波的预测性能将随着IoU阈值的增加而逐渐降低。这一观察表明,在一项困难的任务中,低阈值可能会导致错误地移除预测框,而高阈值可能会生成多余的预测框并影响最终结果。这意味着,即使检测模型的预测很好,最终结果仍可能受到NMS的影响,从而造成性能瓶颈。图2还描述了没有NMS的YOLOv5x的潜在性能。
4、DEYO
4.1、Overview
本文的模型使用YOLOv5作为第一阶段,DINO作为第二阶段,提供了一种新的基于渐进推理的两阶段模型。在本文中,第一阶段的YOLOv5模型称为PRE-DEYO,第二阶段的DINO模型称为POST-DEYO。作为经典YOLO系列的检测器,PRE-DEYO包含一个主干、一个包括FPN+PAN的颈部和一个输出三个尺度预测信息的头部。作为一个类似DETR的模型,POST-DEYO包含一个主干、多层Transformer编码器、多层Transformer解码器和多个预测头。它使用Anchor的静态query和动态初始化,并涉及用于比较去噪训练的Additional CDN分支。
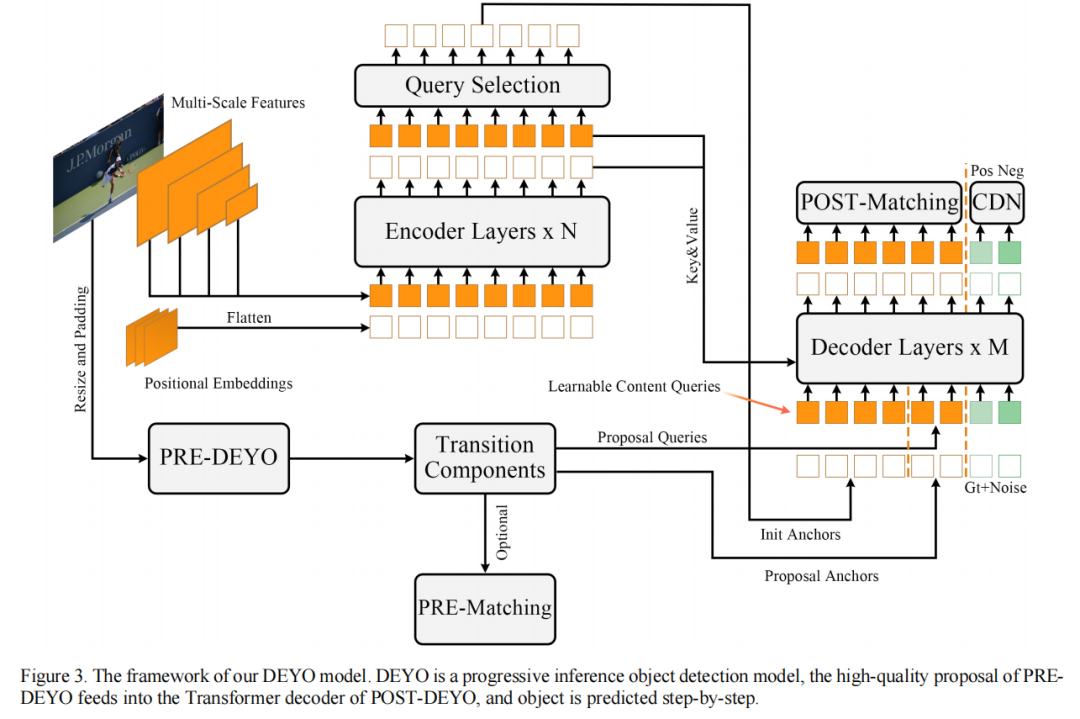
整个DEYO模型如图3所示。PRE-DEYO的输出通过转换组件与PRE-DEJO的初始化query和Anchor相结合,并输入到Transformer解码器。POST-DEYO可以在训练期间快速获取PRE-DEYO的信息,并专注于困难的任务。
本文给出了两种标签分配方法,DEYO默认使用POST匹配,PRE匹配仅用于消融研究。PRE匹配类似于POST匹配,PRE-DEYO的输出直接与GT匹配,以避免二分匹配不稳定性对目标分配的影响。
4.2、DINO briefing
DINO是一种基于DN-DETR、DAB-DETR和Deformable-DETR的类DETR模型,将解码器中的query公式化为动态Anchor,并在解码器层中逐步细化。在DN-DETR之后,DINO将去噪训练改进为对比去噪训练(CDN),提高了对没有附近对象的Anchor的“无目标”预测能力,同时在训练期间稳定了二分图匹配。
同时,DINO还使用可变形注意力来提高其计算效率。动态Anchor Box的逐层细化有助于POST-DEYO在推理中微调PRE-DEYO的高质量Anchor Box。可变形注意力与高质量Anchor Box相结合,使POST-DEYO能够快速找到图像中的关键信息,进一步加快边界框过滤、验证和调整图像内容。
4.3、Transition components
转换组件处理从PRE-DEYO发送到POST-DETR的信息,以确保信息解释期间的一致性,并确保从PRE-DIYO过滤的信息最适合POST-DEYO。
1、Prediction selection
PRE-DEYO预测了许多几乎相同的边界框,如果没有引入过滤机制,则训练过程中会导致POST-DEYO崩溃。作者发现POST-DEYO中的过滤能力是有限的。因此,POST-DEYO很难学习相似和重叠框的正确过滤策略。
因此,作者将NMS包含在转换组件中,以过滤来自PRE-DEYO的信息。为了保证模型的最终性能,作者通过调整合适的IoU阈值来获得最适合POST-DEYO的高质量query和Anchor。在过渡组件中使用NMS不会限制模型的最终性能,因为由于错误保留或删除框而可能导致的性能下降在POST-DEYO中得到了补偿。
2、Padding
由于每张图像中的目标数量会动态变化,因此PRE-DEYO生成的高质量query和Anchor在发送到POST-DEYO之前会被填充到特定的数字。该策略确保了每个epoch中query数量的稳定性。填充query不参与二分图匹配或损失计算,并且不用于最终预测结果。
3、Label Mapper
PRE-DEYO的COCO类别指数从0到79,POST-DEYO COCO类别索引从0到90,涉及POST-DEY中几个未使用的类别指数。标签映射器将PRE-DEYO的类别索引替换为POST-DEYO中CDN组件的同一类别所使用的序列号。对齐类别索引允许模型只学习一种类型的编码系统并加速模型训练。
4、Class Embedding
PRE-DEYO的类别信息通过类嵌入被投影到隐藏特征维度,然后被发送到Transformer编码器。由于COCO类别号一致,本文的类嵌入与CDN的标签嵌入一致,但独立于标签嵌入,大大加快了模型学习PRE-DEYO类别信息的过程。
5、Post Processing of Anchor
由于PRE-DEYO和POST-DEYO的推断是在不同的图像尺度下进行的,因此Anchor后处理将PRE-DEY的高质量Anchor与POST-DEY的尺度对齐。在归一化和inverse sigmoid 处理之后,Anchor被传送到POST-DEYO的解码器。
5、实验
5.1、Main Results
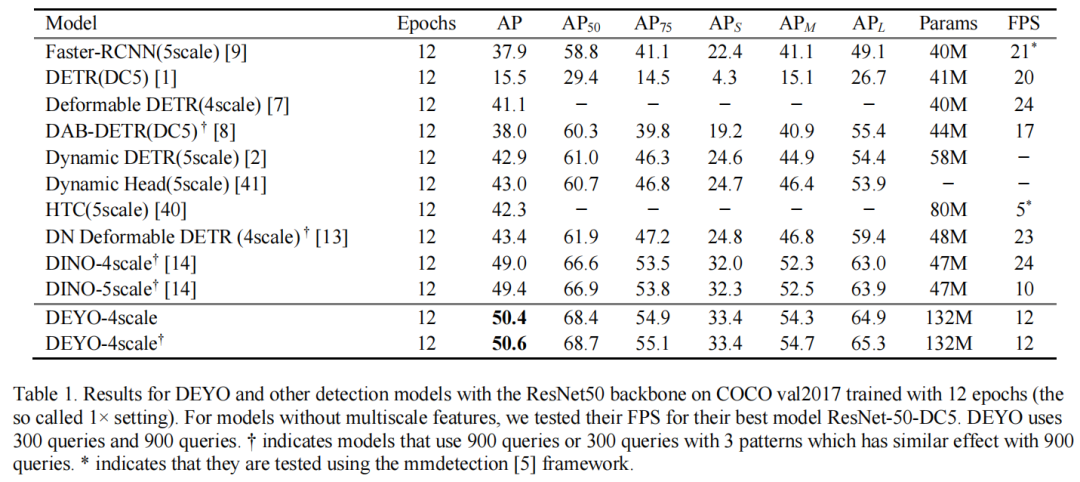
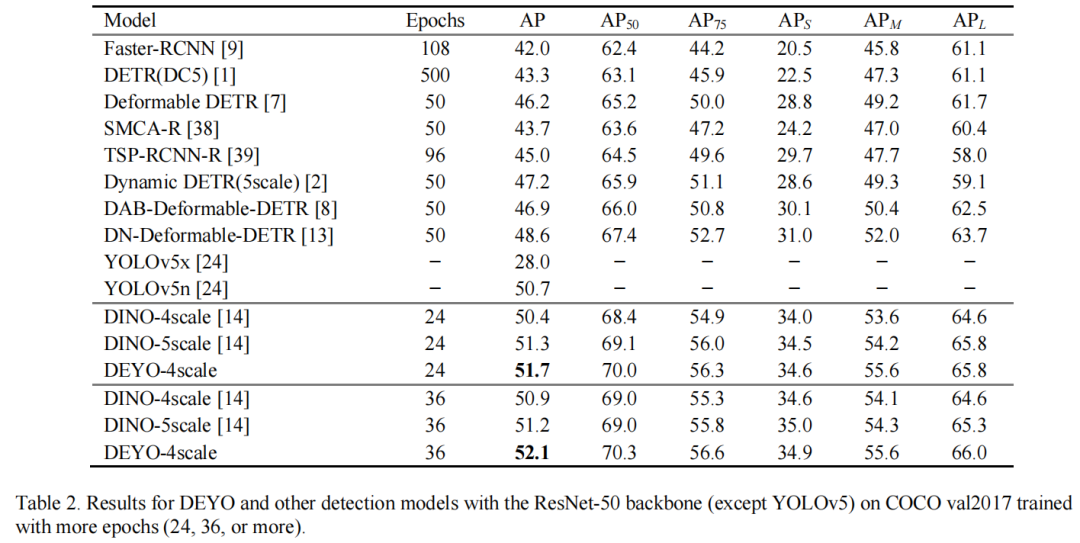
5.2、Ablation Study
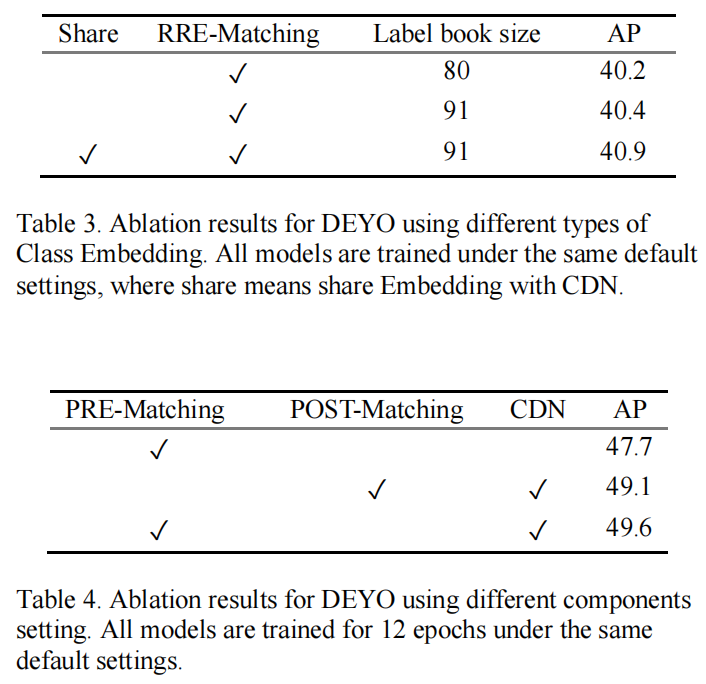
在表3和表4中,利用PRE匹配来保护CDN不受增加二分匹配稳定性对性能的影响。在表3中,探讨了不同的类嵌入方法对第一个epoch性能的影响,并发现在CDN上使用标签嵌入对POST-DEYO从PRE-DEYO学习信息最为有利。
作者还分析了CDN对POST-DEYO性能的增益,表4中的结果表明,除了提高匹配后二分匹配的稳定性之外,CDN还可以引导模型学习正确重建来自PRE-DEYO的信息。
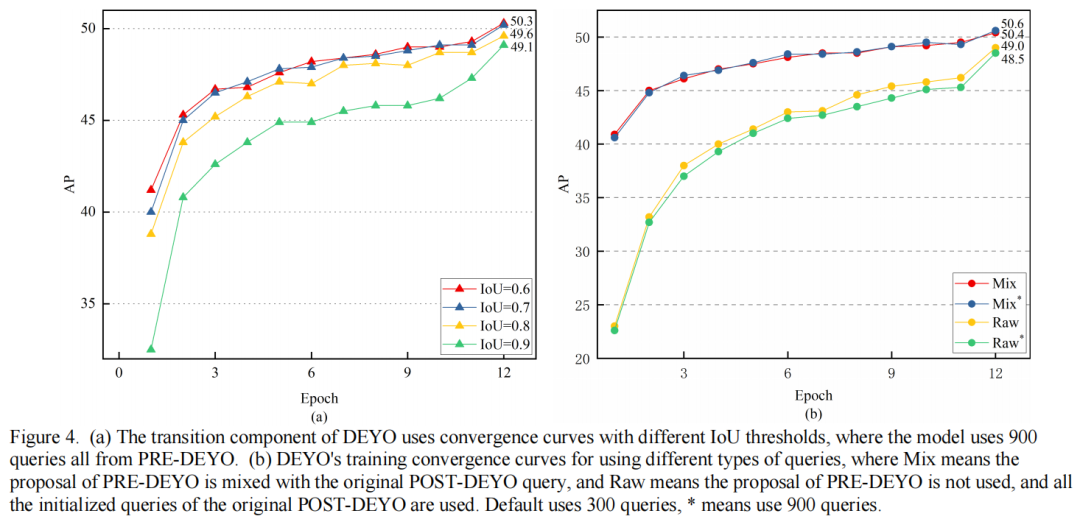
在图4(a)中,作者使用900个query分析了训练收敛曲线,这些query都来自PRE-DEYO,过渡分量的iou阈值不同。结果表明,POST-DEYO的电流滤波鉴别能力有限,性能随着iou阈值的升高而降低。
作者还分析了12个epoch训练收敛曲线混合和原始query,如图4(b)所示。结果表明,使用混合query的DEYO模型对query数量的变化最不敏感。DEYO模型使用来自PRE-DEYO的计算成本较低的预测来减少计算成本较高的query数量,而不会降低准确性和加快推理速度。
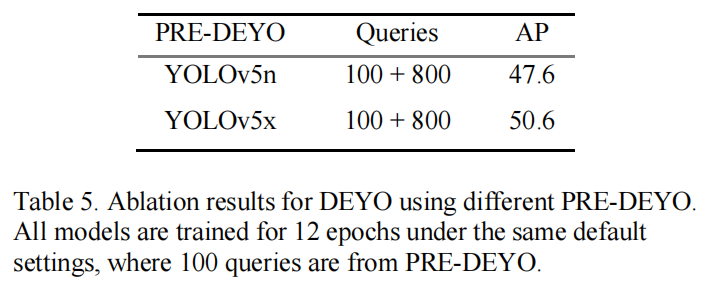
在表5中分析了使用不同的PRE-DEYO对DEYO整体性能的影响。结果表明,query和anchor的质量在很大程度上决定了最终的性能。这是因为良好的query和anchor质量可以为POST-DEYO建立明确的优化目标,使预测一对一对象集变得更容易,而低质量的query和anchor会使POST-DEXO训练变得更困难。
5.3、分析
对比去噪训练对于DEYO模型至关重要,可以增强POST-DEYO二分法匹配的稳定性,并指导POST-DEYO在推理中获得更好的结果。正如在Let’s think by think中一样,精心设计的中间推理步骤可以显著提高模型的最终性能。
因此,作者认为,POST-DEYO的鉴别滤波能力不仅取决于解码器,还与CDN等组件的设计密切相关。在表3中,将共享嵌入导致的性能下降与独立嵌入进行了比较,这表明CDN query anchor和POST-DEYO初始化中的query anchor在训练期间是不明确的。作者相信,更好的“CDN”和中间推理指导可以帮助POST-DEYO在更大程度上利用PRE-DEYO的潜在性能。
6、总结
本文提出了一种新的两阶段目标检测模型DEYO,该模型采用基于分步思想的渐进推理方法。该模型降低了类DETR模型预测一对一对象集的难度,并从新的角度解决了类DETR模型收敛速度慢的问题。同时,它有效地改善了经典检测器由于NMS后处理而导致的性能瓶颈问题。结果表明,渐进推理方法显著加快了收敛速度并提高了性能,使用ResNet-50作为主干,在1x(epochs)设置中获得了最佳结果。
考虑到限制和未来的工作,轻量级过渡组件和POST-DEYO还没有充分利用第一阶段的信息。事实上,图4(a)强调了由于不适当地过滤信息而导致的性能下降。因此,应探索两个阶段之间更有效的信息传输方案,并应改进不完善的信息编码和解码,以避免最终性能下降。
7、参考
[1].DEYO: DETR with YOLO for Step-by-Step Object Detection.
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
