
目标检测SpineNet
这篇在2019年12月10日由谷歌发表的新型神经网络框架闯入大众的视野,文章提出相较于传统的卷积神经网络在中间层总会进行各种卷积操作来进行一定的特征提取。然而在提取的过程中,总会出现部分的特征损失(卷积后像素降低导致)。这或许对于分类来说无关痛痒,但对于例如物体识别这种同时兼具识别和定位的场景时往往有可能会出现效果不佳的情况。文章提出通过在分类任务的骨干模型设计中采用(decoder network)来解决问题,当然就是采用SpineNet来进行。在COCO上的一级目标检测对比ResNet-FPN不仅AP上提高了6%并且减少了60%的算力需求。并且SpineNet可以转换为分类任务模型,在iNaturalist细粒度数据集上相较于之前的第一名整整提高了6%的精确度。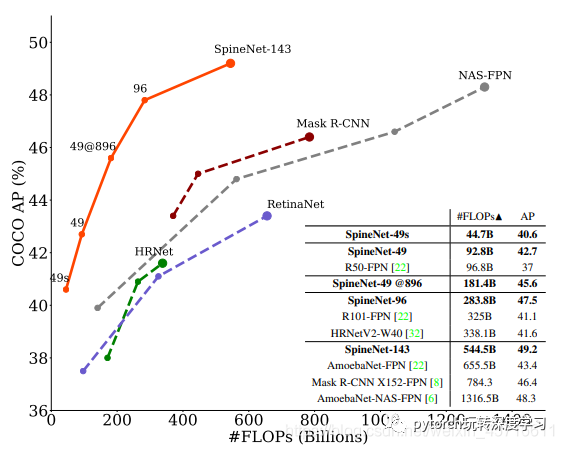
正常情况下我们都知道如果对于一张图片进行采样越底层的保留的细节信息越多,越顶层保留了抽象维度的信息越多。简单的说底层可以提取更多的小物件的细节特征,但是与此同时几乎没有位置信息。作者给出了两个解决思路:首先是对于特征图的中间层的尺度规模是可以随时扩大和缩小的,以便随着模型的深度增加也能保证一定的空间信息。其次两个不同特征层也是可以进行跨尺度的链接,来保证多尺度的特征融合。下图表示作者观点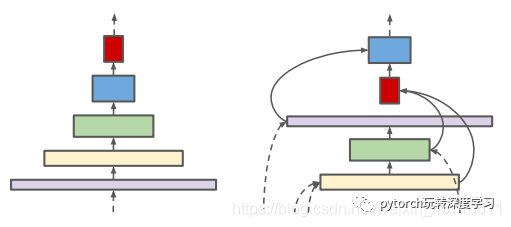
同时作者表示虽然手头上已经有一个简单的架构模型,但是为了避免手动设计筛选架构。所以干脆直接把架构设计这件事情一起丢入神经结构搜索(NAS)的中来进行学习。从而使框架和解码模型间不再有区别,都将顺从要素金字塔结构且可视。
以ResNet50-FPN作为基础网络来进行调整我们对于物体检测任务可以得到巨大的提升,仅进行缩放尺度排列学习就能提高3.7%的AP,如果进一步对模块(e.g.residual block or bottleneck block)的选择进行调整还能提高2%的AP。而这种通过对于缩放尺度排列、骨干架构的学习方式我们也将之命名为SpineNet。 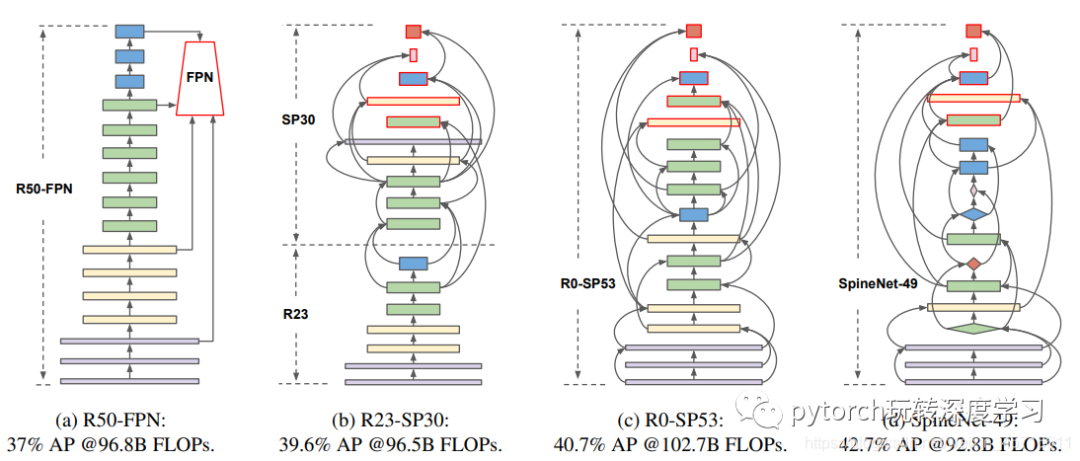
跨尺度融合最大的壁垒来至于两个融合的层数分辨率和维度很可能完全不同,这个时候就需要新的方案来解决这个问题,如下图: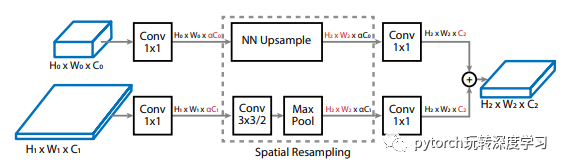
通过一个执行空间重采样的过程,在第一个1 * 1的卷积上引入了一个α(默认值为0.5)来对维度进行控制。之后进入空间重采样区,对于下层高分辨的采用3 * 3步长为2的卷积顺带必要的时候可以进行一个最大的池化操作以便后续可以下采样和目标维度经行匹配,而目标维度也可以进行上采样的操作。最后由1 * 1的卷积层来进行维度的最终匹配,都成为了一个H2∗W2∗C2的标准层再进行相加。
作者对于对于ResNet-50的模型进行不同程度的置换,以考究主干模型和尺度可变模型间的关系。通过限定不同程度的搜索空间来进行生成不同的骨干结构。
| stem network {L2, L3, L4, L5} | scale-permuted network {L2, L3, L4, L5, L6, L7} | |
|---|---|---|
| R50 R35-SP18 R23-SP30 R14-SP39 R0-SP53 | {3, 4, 6, 3} {2, 3, 5, 1} {2, 2, 2, 1} {1, 1, 1, 1} {2, 0, 0, 0} | {−} {1, 1, 1, 1, 1, 1} {1, 2, 4, 1, 1, 1} {2, 3, 5, 1, 1, 1} {1, 4, 6, 2, 1, 1} |
| SpineNet-49 | {2, 0, 0, 0} | {1, 2, 4, 4, 2, 2} |
上图表格1对应的部分图像在图三查找,不难看出在全面解禁搜索空间后主干网络会被逐步减少,而尺度可变网络占比在逐步拉伸。并且对于块的数量如果不再局限那么L2,3,4,5,6,7数量配比也会发生改变,最终训练出来的模型便是SpineNet-49。
作者又开始对SpineNet-49来进一步的进行探究,在权衡延时性能后共衍生出了三个个同家族系列的网络结构。分别命名为SpineNet-49s、SpineNet-96、SpineNet-143。其中SpineNet-49s居于和49相同的结构,但是特征尺寸仅有原来的75%,而SpineNet-96是重复了原来一次的结构块来加深深度(参考下图中间部分),SpineNet-143则是复用总计三次原来的结构(参考下图的右边部分)。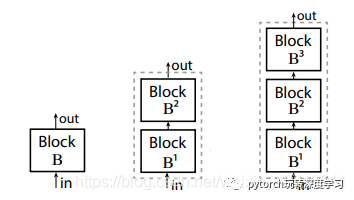
在物体检测SpineNet有一定的效果,对比ResNet-FPN还是Mask R-NN都有一定的提高。并且可以推广到图像分类上。
总结:本文对于传统的骨干结构进行了革新。通过引入NAS多尺度融合甚至对于模块进行选择和调整使得骨干模型更加合理,而无需依靠人工来进行先验设计。