
目标检测NAS-FPN
&Title:
NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
&Summary
目前最先进的卷积结构用于物体检测是手工设计的。
在这里,我们的目标是一个更好的学习可扩展特征金字塔结构,用于目标检测。在一个覆盖所有交叉尺度连接的可扩展搜索空间中,采用神经网络结构搜索,发现了一种新的特征金字塔结构。架构名为NAS-FPN,由自顶向下和自下而上的连接组合而成,可以跨范围地融合特性。
为了发现一个更好的FPN架构,作者充分利用了神经网络搜索技术[Neural architecture search with rein- forcement learning.],使用强化学习训练了一个控制器来在给定的搜索空间中选择最好的模型结构。控制器使用在搜索空间内子模型的准确率来作为更新参数的反馈信号(reward signal)。因此,通过这样的试错,控制器会学到越来越好的结构,搜索空间在架构成功搜索的过程中起到了很重要的作用。对于FPN的可拓展性,在搜索的过程中,作者强制让FPN重复N次然后concatenation到一起形成一个大的架构。
一句话解释:FPN就是用来特征融合的层,之前都是手工设计,现在尝试神经网络搜索设计!其实就是优化FPN。
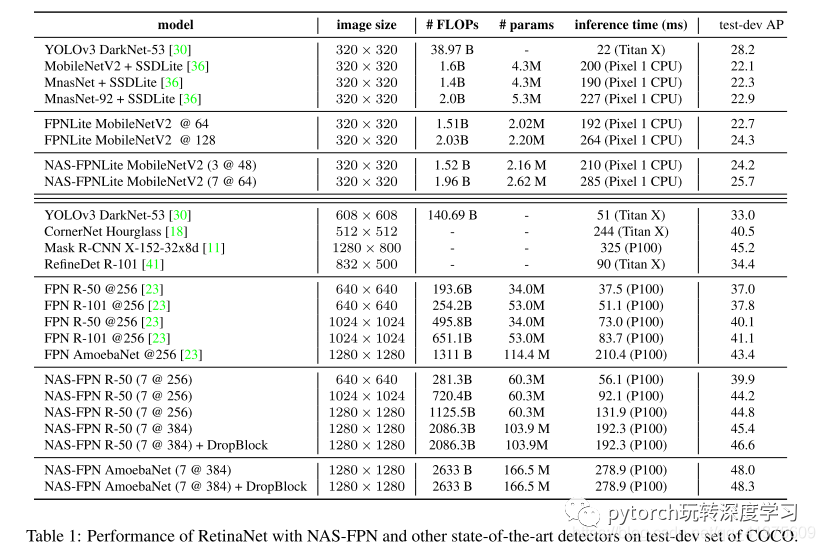
结果:与最先进的目标检测模型相比,NAS-FPN与retinanet框架中的各种主干模型相结合,实现了更好的准确性和延迟权衡。与mobilenetv2模型的最先进的ssdlite相比,nas-fpn提高了2 ap的移动检测精度,达到48.3 ap,以更少的计算时间超越了mask r-cnn的检测精度。
&Research Objective
目标是一个更好的学习可扩展特征金字塔结构,用于目标检测。在一个覆盖所有交叉尺度连接的可扩展搜索空间中,采用神经网络结构搜索,发现了一种新的特征金字塔结构。架构名为NAS-FPN,由自顶向下和自下而上的连接组合而成,可以跨范围地融合特性。
注:神经网络搜索(理论上可以对任何东西进行搜索,就像是强化学习和进化算法
遗传算法等等,这些都是寻优算法,只不过现在把这些算法应用到了神经网络的领域)
&Problem Statement
当前目标检测网络中采用特征金字塔网络(FPN)结构解决多尺度的问题,但是这些 FPN 都是人工事先设计,并不一定是最优的结构。为了更灵活地获得更优的 FPN 结构,该文章首创性地提出了采用神经架构搜索(NAS)的方式定制化地构建 FPN,该结构又称 NAS-FPN。
特征金字塔网络(FPN)是一种典型的模型体系结构,用于生成目标检测的金字塔特征表示。它采用了一个主干模型,通常是为图像分类而设计的,通过将主干模型中的特征层次中的两个相邻层按顺序组合,通过自顶向下和横向连接来构建特征金字塔。高级特征在语义上很强,但分辨率较低,它们被放大并与高分辨率特征相结合,以生成高分辨率和语义强的特征表示。虽然fpn简单有效,但它可能不是最佳的体系结构设计。最近,panet[25]显示在fpn特性上添加额外的自下而上路径可以改进低分辨率特性的特性表示。许多最近的论文[7、16、17、34、38、39、40、43、41]提出了各种交叉尺度连接或操作,以组合特征以生成金字塔特征表示。
&Method(s)
我们的方法基于RetinaNet框架,因为它简单而有效。RetinaNet框架有两个主要组件:骨干网络(通常是最先进的图像分类网络)和特征金字塔网络(FPN)。该算法的目标是为RetinaNet发现更好的FPN架构。图2显示了RetinaNet架构。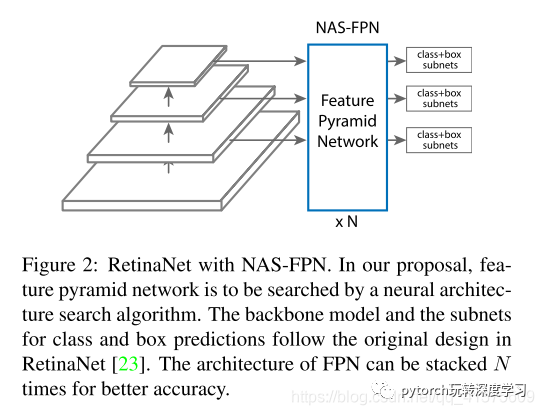
为了发现更好的FPN,我们利用提出的神经架构搜索框架。
神经架构搜索训练控制器使用强化学习在给定搜索空间中选择最佳模型架构。控制器使用搜索空间中的子模型的准确性作为更新其参数的奖励信号。因此,通过反复试验,控制器可以学习如何随着时间的推移生成更好的架构。
搜索空间
FPN 的众多跨连接构成了很大的搜索空间。在搜索空间中,一个 FPN 由很多 merging cells 组成,然后合并一些来自不同层融合的特征表示。一个 merging cell 将两个来自不同特征层的特征连接融合产生一个特征输出,这样的单元结构就构成了 FPN 的元结构,同时所有的可能的特征层组合由 merging cells 组建化的表示,这也就构成了我们的搜索空间(模块化)。一个 merging cell 的结构如下: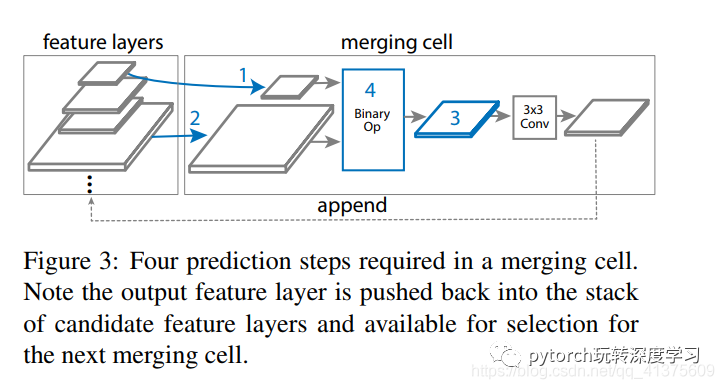
构建 merging cell 是由控制器 RNN 来做决定,它不仅要决定选取哪两个特征层,还要决定采用那种特征融合方式。
每个 merging cell 有 4 个预测步骤:
从候选中选择一个特征层;
从候选中没有替换地选出另一个特征层;
选择输出特征的分辨率;
选择一个operation操作来融合step1和step2的特征,然后生成一个分辨率为step3选定的新的特征。
在step 4中的operations有两种,sum和global pooling,因为他们简单有效.输入的特征层使用最近邻采样或者max pooling来调整到输出分辨率,merged特征层总会跟着ReLu, 3x3卷积和一个BN层。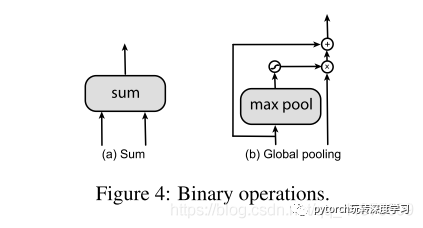
在架构搜索期间,可以有多个候选功能共享相同的分辨率。为了减少已发现架构中的计算,我们避免在步骤3中为中间合并单元选择步长8特征。最后,最后5个合并单元被设计为输出特征金字塔{P3,P4,P5,P6,P7}。输出特征级别的顺序由控制器预测。然后通过重复步骤1,2,4生成每个输出特征层,直到完全生成输出特征金字塔。
深入监督随时检测目标
模块化金字塔架构的另一个好处是可以随时检测目标,虽然这种方法已出现,但手动设计这种架构依旧相当困难。固定分类和回归的网络进行深度监督训练。搜索的终止并不是非要全部搜索完,随时都可以退出。因为分辨率不变,所以 FPN 可以随意扩展。
利用堆叠金字塔网络缩放NAS-FPN的一个优点是可以在任何给定金字塔网络的输出处获得特征金字塔表示。此属性可以随时检测,可以在早期退出时生成检测结果。
NAS 利用强化学习训练控制器在给定的搜索空间中选择最优的模型架构。控制器利用子模型在搜索空间中的准确度作为奖励信号来更新参数。因此,通过反复试验,控制器逐渐学会了如何生成更好的架构。由于不知道 FPN 的跨连接情况,NAS-FPN 采用 RNN 作为控制器,使用该控制器来产生一串信息,用于构建不同的连接。其宏观结构如下图所示:(图源文章)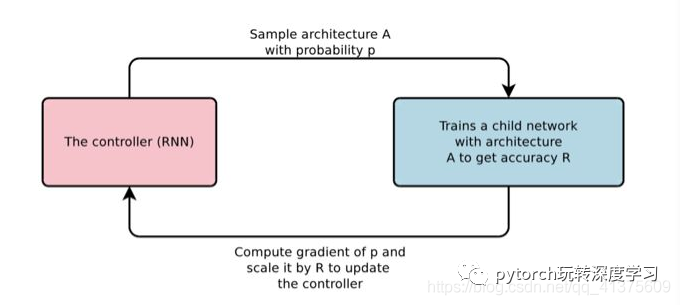
搜索得到的最优 FPN 结构如下图,其控制器收敛得到的最终 FPN 结构如 (f) 所示,并且其精度最高。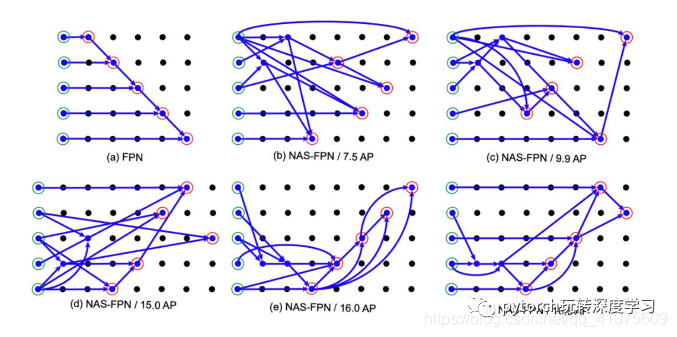
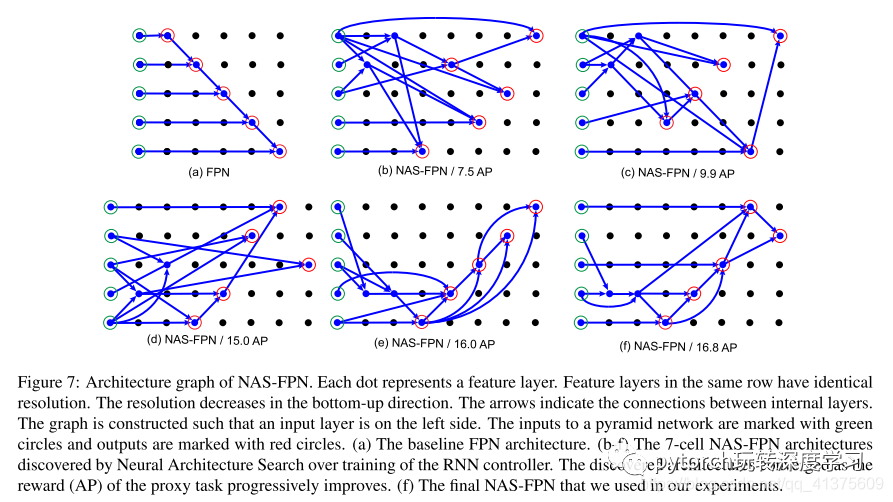
每个点代表一个特征层。同一行的特征层具有相同的分辨率。分辨率在自底向上下降。箭头表示内部层之间的连接。图中左侧是输入层。金字塔网络的输入用绿色圆圈标记,输出用红色圆圈标记。
最终收敛的 FPN 网络结构如下图: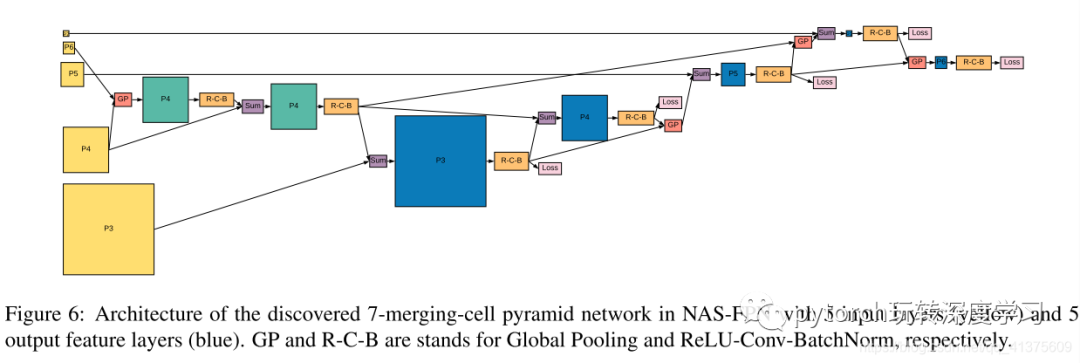
注:图6:NAS-FPN中发现的7合并单元金字塔网络的体系结构,具有5个输入层(黄色)和5个输出要素层(蓝色)。GP和R-C-B分别代表Global Pooling和ReLU-Conv-BatchNorm。
&Evaluation
Proxy task
为了加速RNN控制器的训练,我们需要一个代理任务,它具有较短的训练时间,并且与实际任务相关。
然后,可以在搜索期间使用代理任务来识别良好的FPN架构。我们发现我们可以简单地缩短目标任务的训练并将其用作代理任务。我们只训练10个时期的代理任务,而不是我们用来训练RetinaNet汇聚的50个时期。为了进一步加快培训代理任务,我们使用ResNet-10的小型骨干架构,输入512×512图像大小。
通过这些减少,TPU上的代理任务的培训时间为1小时。我们在代理任务中重复金字塔网络3次。
初始学习率0.08适用于前8个时期,并且在时期8处以0.1的系数衰减。我们保留从COCO
train2017中随机选择的7392个图像作为验证集,我们用它来获得奖励Controller
我们的控制器是递归神经网络(RNN),并使用近端策略优化(PPO)[33]算法进行训练。控制器对具有不同架构的子网络进行采样。这些体系结构使用工作池来训练代理任务。
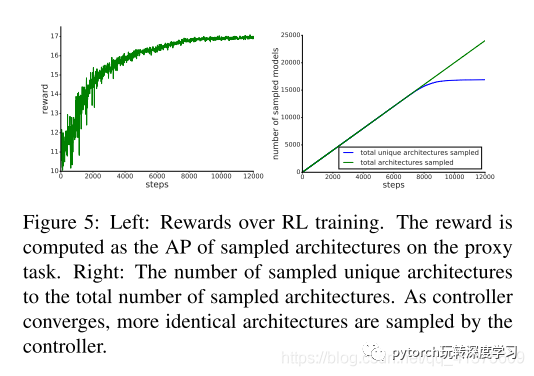
我们实验中的工作队列由100个Tensor Processing
Units(TPU)组成。由此产生的保持定值组平均精度(AP)的检测精度用作更新控制器的奖励。注:架构的详细信息为上文收敛的 FPN 网络结构图
图5-Left显示了不同迭代训练的采样体系构结的AP。可以看出,控制器随着时间的推移产生了更好的架构。
图5-Right显示了采样架构的总数以及RNN控制器生成的唯一架构的总数。经过约8000步后,独特架构的数量趋于一致。
Discovered feature pyramid architectures
什么使金字塔结构成为一个好的功能? 我们希望通过可视化发现的架构来阐明这个问题。在图7(b-f)中,我们绘制了NAS-FPN架构,在RL训练期间获得了更高的奖励。我们发现RNN控制器可以在早期学习阶段快速获得一些重要的跨尺度连接。例如,它发现高分辨率输入和输出特征层之间的连接,这对于生成用于检测小物体的高分辨率特征至关重要。
当控制器收敛时,控制器会发现具有自上而下和自下而上连接的架构,这与图7(a)中的vanilla FPN不同。随着控制器的收敛,我们还发现了更好的特征重用。控制器不是从候选池中随机选择任何两个输入层,而是学习在新生成的层上构建连接以重用先前计算的特征表示。
Stacking pyramid networks
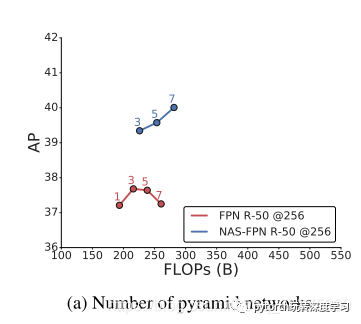
我们的金字塔网络具有很好的特性,可以通过堆叠多个重复架构将其扩展为更大的架构。在上图中,我们显示堆叠vanilla FPN(vanilla ????这个是什么,刚入门不久,博主不是很清楚这个东西)架构并不总能提高性能,而堆叠NAS-FPN显着提高了准确性。这个结果突出了我们的搜索算法可以找到可扩展的架构,这可能很难手动设计。有趣的是,虽然我们在架构搜索阶段只代理任务应用了3个金字塔网络,但应用最多7个金字塔网络时性能仍然有所提高。Adopting different backbone architectures
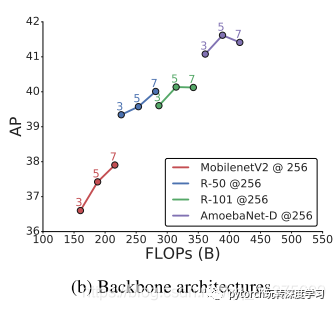
一种衡量对象检测体系结构准确性和速度的常用方法是改变主干架构。尽管NAS-FPN中的金字塔网络是通过使用轻量级ResNet-10骨干架构发现的,但我们表明它可以在不同的骨干架构中很好地传输。上图中显示了NAS-FPN在不同主干之上的性能,从较轻的体系结构(如MobilenetV2)到非常高容量的体系结构(如AmoebaNet-D [29])。Adjusting feature dimension of feature pyramid networks
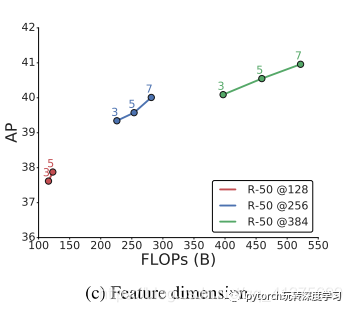
增加模型容量的另一种方法是增加NAS-FPN中特征图层的特征尺寸。图8c显示了具有ResNet-50骨干架构的NAS-FPN中128,256和384特征维度的结果。 毫不奇怪,增加特征尺寸可以提高检测性能,但它可能不是提高性能的有效方法。注:点上方的数字表示网络堆叠的次数。
Architectures for high detection accuracy
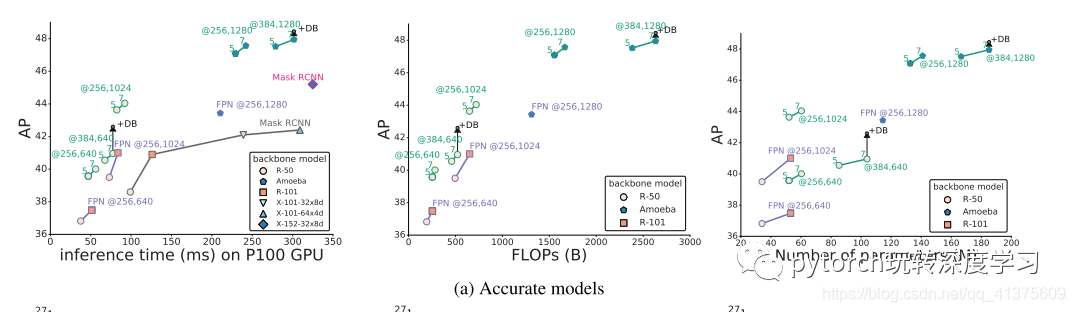
通过可扩展的NAS-FPN架构,我们将讨论如何在保持高效的同时构建精确模型。在图9a中,我们首先表明NAS-FPN R-50 5 @ 256模型具有与R-101 FPN基线相比较的FLOP,但具有2.5 AP增益。 这表明使用NAS-FPN比用更高容量的模型替换骨干更有效。为了获得更高精度的模型,可以使用更重的骨架模型或更高的特征尺寸。图9(a)显示,与现有方法相比,NAS-FPN架构位于推理时间数字的左上部分。NAS-FPN与最先进的Mask R-CNN模型一样精确,计算时间更短。
Architectures for fast inference
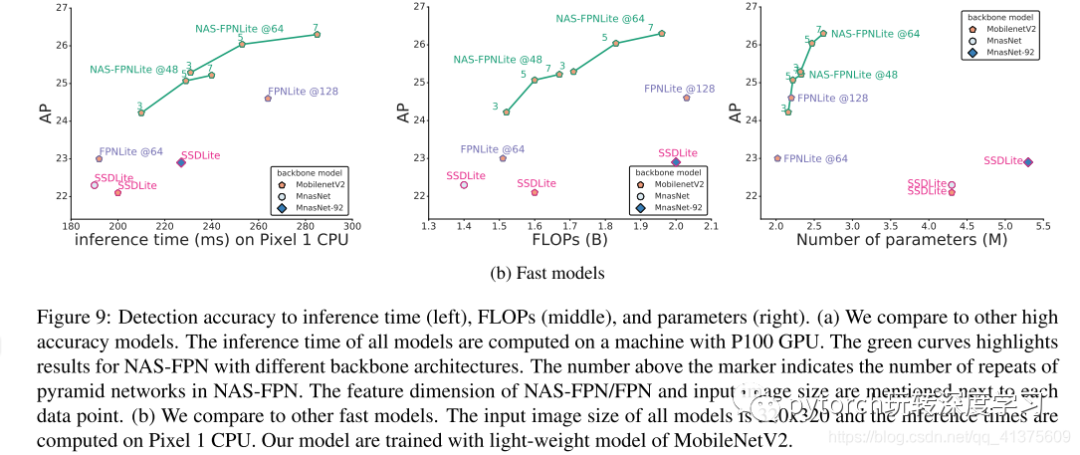
设计具有低延迟和有限计算预算的对象检测器是一个活跃的研究课题。在这里,我们介绍NAS-FPNLite用于移动对象检测。
NAS-FPNLite和NAS-FPN的主要区别在于我们搜索具有P3到P6输出的金字塔网络。在图9b中,我们将NAS-FPN的特征维度控制为48或64,以便它具有相似的FLOP Pixel1上的CPU和CPU运行时作为基线方法,并显示NAS-FPNLite优于SS-DLite [32]和FPNLite。
Further Improvements with DropBlock
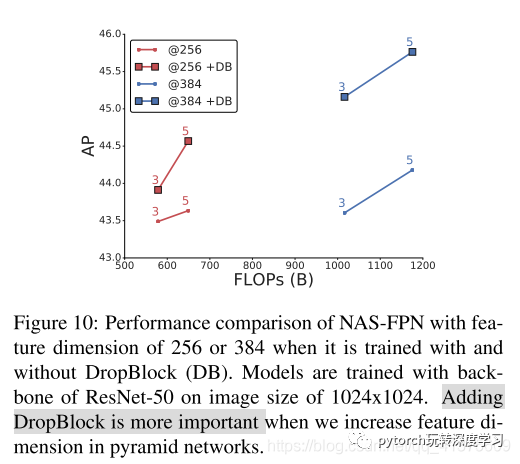
由于NAS-FPN架构中引入的新层数量增加,因此需要进行适当的模型正则化以防止过度拟合。我们在NAS-FPN层中的批量标准化层之后应用块大小为3x3的DropBlock。
图10显示DropBlock提高了NAS-FPN的性能。特别是,对于具有更多新引入的过滤器的架构,它进一步提高。
result
&Conclusion
本文提出利用神经架构搜索进一步优化用于目标检测的特征金字塔网络的设计过程。在 COCO 数据集上的实验表明,神经结构搜索发现的架构,名为 NAS-FPN,具有良好的灵活性和高性能,可用于构建精确的检测模型。在广泛的精度和速度权衡方面,NAS-FPN 在许多检测任务的主干架构上产生了显著改进。
&Notes
主要贡献
设计搜索空间,覆盖所有可能的跨尺度连接,以生成多尺度特征表示。 在搜索过程中,我们的目标是发现一个具有相同输入和输出特性级别并且可以重复应用的原子体系结构(博主不是特别能理解这句话:具有相同输入和输出特性级别???)。模块化的搜索空间使搜索金字塔结构变得易于管理。模块化金字塔结构的另一个好处是能够随时随地检测目标(或“提前退出”)。尽管已经尝试了这种早期的退出方法[14],但是在考虑到这种约束的情况下,手工设计这种体系结构是相当困难的。
优势
NAS-FPN的优势之一是搜索空间的设计,覆盖所有可能的跨尺度连接,用来生成多尺度特征表示。 在搜索过程中,研究者的目标是发现具有相同输入和输出特征级别并且可以被重复应用的微粒架构。模块化搜索空间使得搜索金字塔架构变得易于管理。
可视化NAS-FPN架构的理解
看图理解:
仔细看图七,图(b~f)共有8列,除去输入层,也就是文章说的7个merging cell,注意每一列都有一个中间状态 一共是7个代表的是7merging
cell的输出。第二列和第三列上的点,分别有一个点是蓝色的,其余都是普通的黑色。后面的五列中,蓝色点上还有红色圈圈,则为输出。以下理解,参考来自文章
merging cell介绍了编码的方式 |输入|输入|输出|操作方式 |–|--|–|--|不太清楚他们是不是相互独立的 本文中FPN一共有7个上述cell 因此用长度28的串就可以表示一个FPN 初始状态有5个
由于采用了7个merging cells 因此又多了7个状态因此是12个状态 但是上面的12的状态并不是最终的输出 还有一步处理,文中说Similar to [44], we take all feature layers that have not been connected to any of output layer and sum them to the output layer
that has the corresponding resolution正是因为这一点,你会看到有些点的输入是三个输入(merging cell 的输入是两输入) 这是二次处理的结果,但是论文中并不是上面的这种理解方式。首先得到28个编码之后,然后检查是否有没有用到的5个状态中的一个,然后与merging cell的输出进行sum。得到的结果才是中间状态。
编码:
一共有5行 8列 这是因为有5个输入状态 7merging cell的结果 注意每一列都有一个中间状态 一共是7个代表的是7merging cell的输出 如果按照12345对于中间状态的resolution进行编码的的化 从下往上依次是 1 2 3 4 5对于
(b)图就是4 5 1 4 2 3 5
(f)图就是2 2 1 2 3 5 4
参考
CVPR 2019 | NAS-FPN:基于自动架构搜索的特征金字塔网络