
(附论文)目标检测新方式 | class-agnostic检测器用于目标检测
点击左上方蓝字关注我们


目标检测模型在定位和分类训练期间显示目标时表现良好,然而,由于创建和注释检测数据集的难度和成本,训练过的模型检测到数量有限的目标类型,未知目标被视为背景内容。这阻碍了传统检测器在现实应用中的采用,如大规模物体匹配、visual grounding、视觉关系预测、障碍检测(确定物体的存在和位置比找到特定类型更重要)等。

有研究者提出类不可知目标检测作为一个新问题,专注于检测对象的对象类。具体地说,其目标是预测图像中所有对象的边界框,而不是预测它们的对象类。预测的框可以被另一个系统使用,以执行特定于应用程序的分类、检索等。
提出了针对类不可知检测器的基准测试的训练和评估协议,以推进该领域的未来研究。最后,研究者提出了:(1)基线方法和(2)一个新的用于类无关检测的对抗性学习框架,它迫使模型从用于预测的特征中排除特定于类的信息。实验结果表明,对抗性学习方法提高了类不可知性的检测效率。
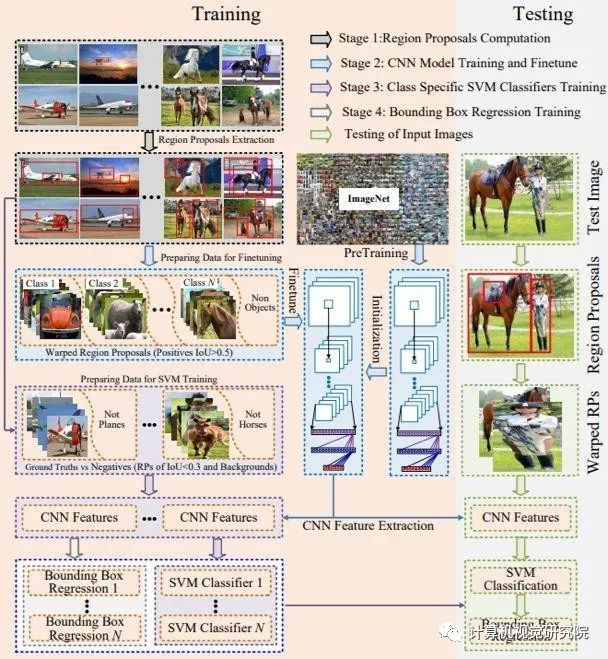
class-specific 方式:很多地方也称作class-aware的检测,是早期Faster RCNN等众多算法采用的方式。它利用每一个RoI特征回归出所有类别的bbox坐标,最后根据classification 结果索引到对应类别的box输出。这种方式对于ms coco有80类前景的数据集来说,并不算效率高的做法。
class-agnostic 方式:只回归2类bounding box,即前景和背景,结合每个box在classification 网络中对应着所有类别的得分,以及检测阈值条件,就可以得到图片中所有类别的检测结果。当然,这种方式最终不同类别的检测结果,可能包含同一个前景框,但实际对精度的影响不算很大,最重要的是大幅减少了bbox回归参数量。具体细节,自己参考目前一些开源算法源码会理解的更好。(摘自于知乎包文韬)
Class-agnostic目标检测器使用object proposal methods (OPMs), conventional class-aware detectors和提出的adversarially trained class-agnostic detectors。如下图:

三、新框架
General Framework
传统的类感知检测侧重于检测“感兴趣的对象”,这本质上要求模型能够区分封闭已知集合中的对象类型。直观地说,模型通过编码区分对象类型的特征来实现这一点。然而,为了使类不可知的检测和模型能够检测到以前看不见的对象类型,检测器应该编码能够更有效地区分对象与背景内容、单个对象与图像中的其他对象的特征,而不区分对象类型。
训练传统的目标检测器的二元分类任务以及边界框回归不足以确保模型关注类无关特征,更重要的是,忽略类型区分特征,以便更好地推广到看不见的目标类型。为了克服这个问题,研究者建议以一种对抗性的方式训练类不可知的目标检测器,以便模型因编码包含目标类型信息的编码特征而受到惩罚。
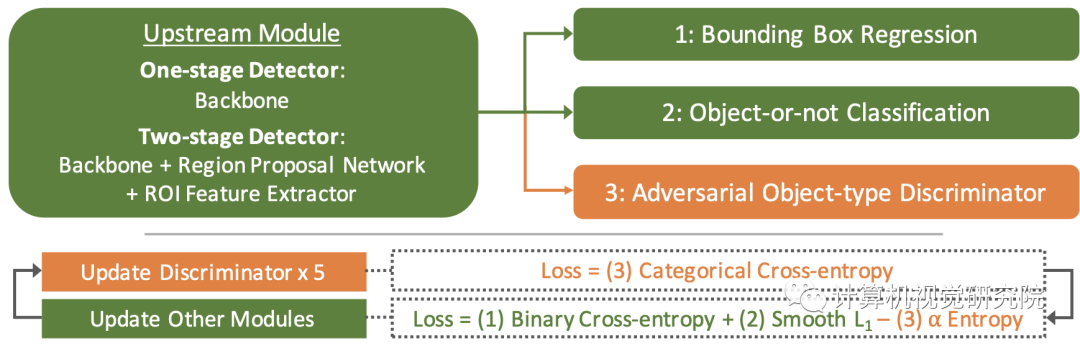
研究者提议用对抗性鉴别器分支来增强类不可知的检测器,这些分支试图从检测网络上游输出的特征中分类对象类型(在训练数据中注释),如果模型训练成功,则对其进行惩罚。模型以交替的方式训练,这样当模型的其余部分更新时,鉴别器被冻结,反之亦然。在更新鉴别器时,研究者使用标准的分类交叉熵损失的目标类型作为预测目标。另一方面,在训练模型的其余部分时,最小化(a)目标与否分类的交叉熵损失,(b)边界框回归的平滑L1损失,以及(c)鉴别器预测的负熵。这种熵最大化迫使检测模型的上游部分从其输出的特征中排除目标类型信息。对于模型的每次更新,鉴别器被更新五次,在整个目标中使用乘子α(调整{0.1,1})对负熵进行加权。上图总结了完整的框架。
四、实验
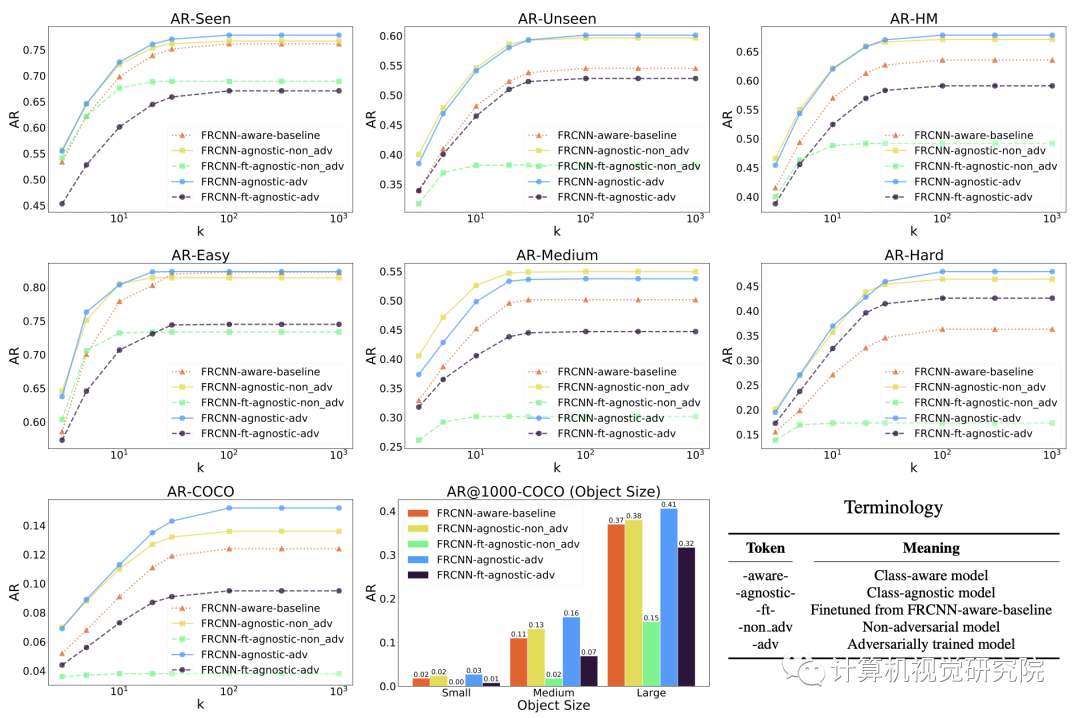
second row shows micro-level results for the easy, medium, and hard unseen classes. FRCNN-agnostic-adv performs the best
on the hard and easy classes with recall drop for the medium class. The last row provides results of evaluation on the COCO
data of 60 unseen classes. FRCNN-agnostic-adv achieves the best AR@k for objects of all sizes.
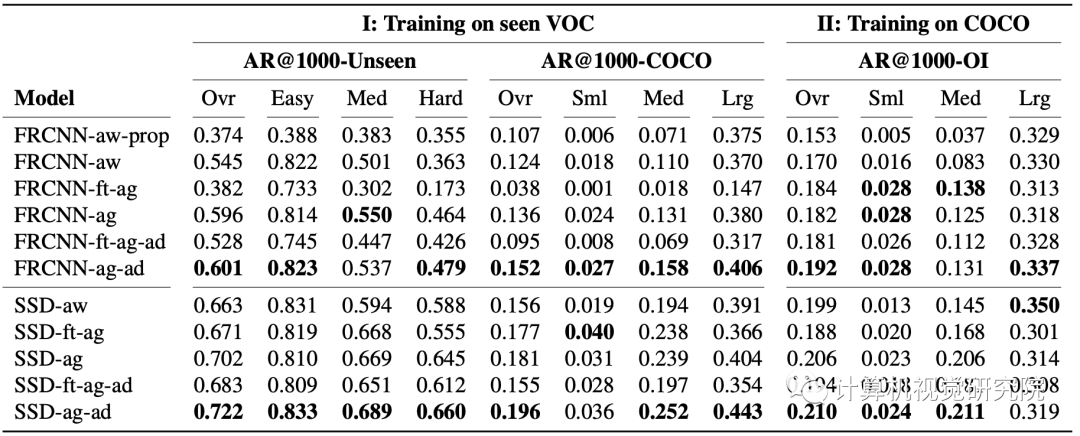
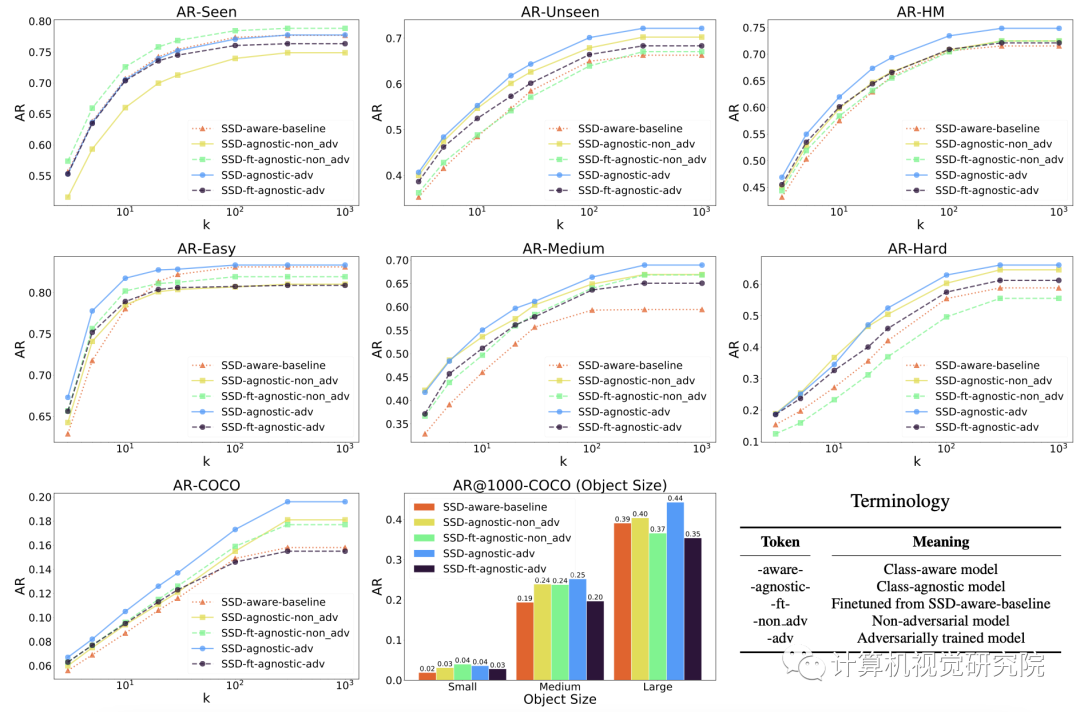
Generalization results for SSD models trained on the seen VOC dataset. The top row shows macro-level AR@kfor seen and unseen classes in VOC as well as their harmonic mean (AR-HM). SSD-agnostic-adv performs the best on AR-
Unseen and AR-HM, with a drop in AR-Seen, but the models that outperform SSD-agnostic-adv on AR-Seen do significantly
worse on AR-Unseen and AR-HM. The second row shows micro-level results for the easy, medium, and hard unseen classes.
SSD-agnostic-adv performs the best in all categories. The last row provides results of evaluation on the COCO data of 60
unseen classes. SSD-agnostic-adv achieves the best AR@k with a slight reduction for small-sized objects.
END
整理不易,点赞三连↓