小目标检测的一些问题,思路和方案
作者:Quantum
编译:ronghuaiyang
对小目标检测进行了分析,并结合已有的方法给出了一些思路。

机器学习正越来越多地进入我们的日常生活。从个人服务的广告和电影推荐,到自动驾驶汽车和自动送餐服务。几乎所有的现代自动化机器都能“看”世界,但跟我们不一样。为了像我们人类一样看到和识别每个物体,它们必须特别地进行检测和分类。虽然所有现代检测模型都非常擅长检测相对较大的物体,比如人、汽车和树木,但另一方面,小物体仍然给它们带来一些麻烦。对于一个模型来说,很难在房间的另一边看到手机,或者在100米之外看到红绿灯。所以今天我们要讲的是为什么大多数流行的目标检测模型不擅长检测小目标,我们如何提高它们的性能,以及其他已知的解决这个问题的方法。
原因
所有现代目标检测算法都是基于卷积神经网络的。这是一种非常强大的方法,因为它能够创造一些低级的图像抽象,如线,圆圈,然后将它们“迭代地组合”成我们想要检测的目标,但这也是它们难以检测小目标的原因。
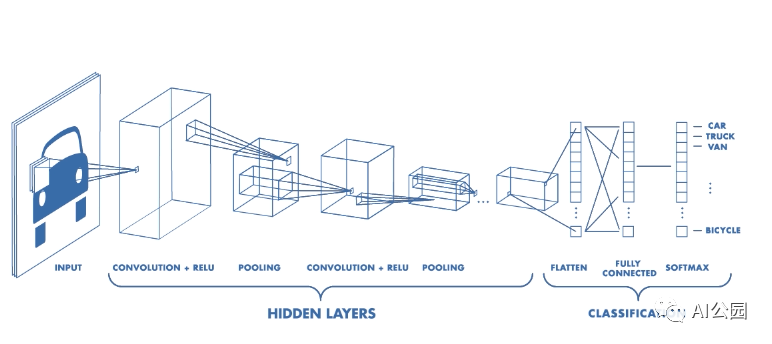
上面你可以看到一个通用的图像分类神经网络的插图。我们最感兴趣的是隐藏层部分。如你所见,这个网络有许多卷积的组合,然后是一个池化层。许多目标检测网络,如YOLO, SSD-Inception和Faster R-CNN也使用这些,而且使用得相当多。将图像的分辨率从600×600降低到约30×30。由于这个事实,他们在第一层提取的小目标特征(一开始就很少)在网络中间的某个地方“消失”了,从来没有真正到达检测和分类步骤中。我们可以尝试一些方法来帮助模型更好地查看这些目标,但是在改进性能之前,让我们先看看它现在的状态。
目前流行的目标检测器的性能
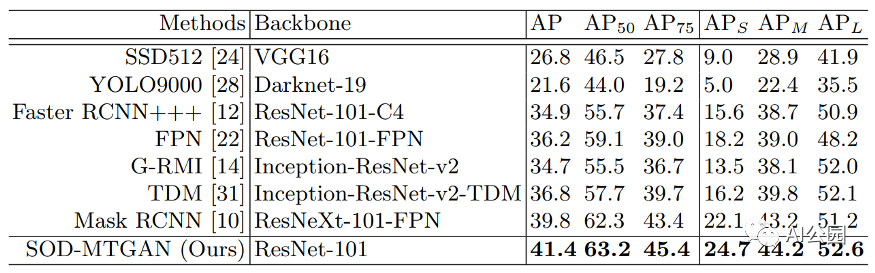
论文SOD-MTGAN在COCO数据集上进行实验并收集了2016年的测试结果。+++表示F-RCNN的特殊训练过程。
一些很小改动去提升小目标检测的方法
使用Focal loss
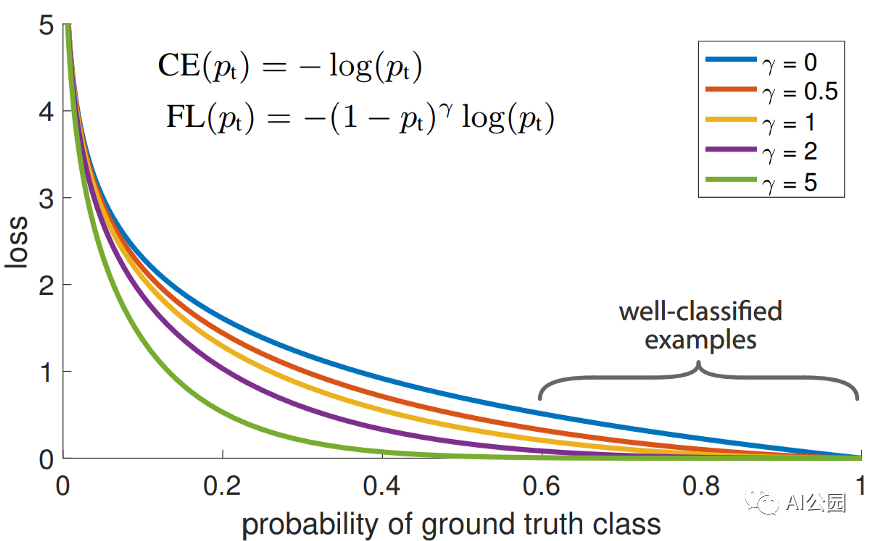
如果你有很多类要检测,一个最简单的方法来提高对小物体和难以检测的类的检测是在训练神经网络的过程中使用Focal loss。这里的主要直觉是,这种损失对网络的“惩罚”不是对它已经可以很好地检测到的类别进行错误分类,而是对它现在有问题的类别进行更多分类。因此,为了进一步最小化损失函数,权值将开始以这样一种方式改变,使网络更好地挑选困难的类别。这很容易从主要论文提供的图中看到:
将图像分成小块
我们自己也遇到过模型不能检测到相对较小的物体的问题。任务是检测足球运动员和比赛场上的足球。游戏的分辨率是2K,所以我们有很多细节。但我们用来检测玩家的模型的输入分辨率要小得多——从300×300到604×604。所以,当我们把图像输入网络时,很多细节都丢失了。它仍然能够找到前景中的球员,但既没有球也没有球员在球场的另一边被检测到。因为我们有一个大的输入图像,我们决定先尝试我们能想到的最简单的解决方案 —— 把图像分割成小块,然后对它们运行检测算法。而且效果很好。你可以在下面看到运行测试的结果。

虽然该模型的FPS大幅下降,但它给了该模型在玩家检测上一个非常好的准确性提升。另一方面,球仍然是个问题。稍后我们将更深入地探讨我们是如何解决它的。
利用图像的时间特性
如果我们有一个来自静止摄像机的视频,我们需要检测它上面的移动物体,比如足球,我们可以利用图像的时间特性。例如,我们可以做背景减法,或者仅仅使用后续帧之间的差异作为一个(或多个)输入通道。所以,我们可能有3个RGB通道和一个或多个额外的通道。这确实让我们改变了一些网络的输入,但仍然不是很多。我们所需要改变的只是第一个输入层,而网络的其他部分可以保持不变,仍然可以利用整个架构的力量。
这一变化将预示着网络将为移动目标创造更“强大”的特性,而这些特性不会消失在池化和大stride的卷积层中。
改变anchor大小
目前的一些探测器使用所谓的“锚”来探测物体。这里的主要直觉是通过明确地向网络提供一些关于物体大小的信息来帮助网络检测物体,并在图像中每个预定义的单元格中检测几个物体。
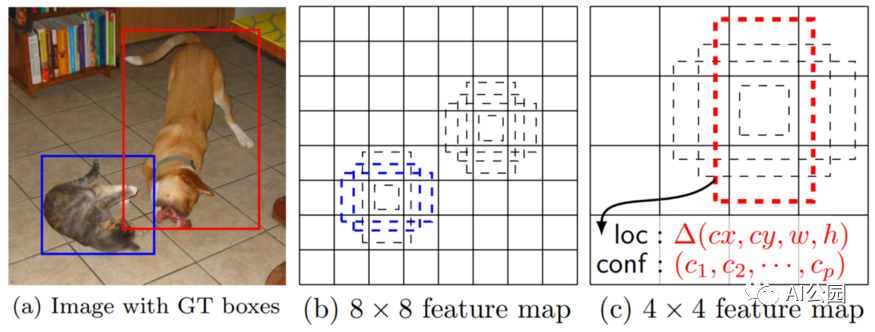
因此,改变锚点以适应你的数据集是一个很好的主意。对于YOLOv3,有一种简单的方法可以做到这一点。这里:https://github.com/AlexeyAB/darknet#how-to-improve-object-detection你将发现一系列改进YOLO体系结构检测的方法。
为小目标检测定制模型
上面描述的方法很好,但远不是最好的,如果你使用专为寻找小目标而设计的体系结构,你很可能会获得更好的结果。所以,让我们开始吧。
特征金字塔网络 (FPN)
由于其有趣的结构,这些类型的网络在检测小目标方面表现得相当有效。虽然像SSD和YOLOv3这样的网络也检测不同尺度的目标,但是只使用了这些尺度的信息,即所谓的金字塔特征层,而FPN建议将高层特征向下传播。这一方法“丰富”了抽象的底层,并具有更强的语义特征,这些特征是网络在其头部附近计算出来的,最终帮助探测器拾取小物体。这种简单而有效的方法表明,可以将目标检测数据集的总体平均精度从47.3提高到56.9。
Finding Tiny Faces
这篇做了大量的工作和研究。我强烈建议你阅读全文:https://arxiv.org/pdf/1612.04402.pdf,但我们在这里总结一下:
上下文很重要,利用它更好地找到小物体
建立多个不同尺度的网络成本高,但效果好 如果你想要高精度,区域建议仍然是一个好方法 查看你的骨干网络做预训练的数据集,然后尝试缩放你的图像,使你需要检测/分类的目标的大小匹配那些预训练的数据集。这将减少训练时间和并得到更好的结果。检测大小为20×45的目标,使用同样大小的kernel可能并不一定是最有效的。将图像放大两倍并使用40×90的kernel,就可能真正提高性能。大物体的情况则相反。
F-RCNN的改进
因为在几乎所有你看到的关于网络之间的速度/准确性比较的图表中,F-RCNN总是在右上角,人们一直在努力提高这种体系结构的速度和准确性。我们将简要看一下不同的改进方法,以提高其准确性。
Small Object Detection in Optical Remote Sensing Images via Modified Faster RCNN
在本文中,作者做了几件事。首先,他们测试了不同的预训练骨干网络用于F-RCNN的小目标检测。结果表明,ResNet-50的效果最好。他们已经选择了最适合他们测试网络的数据集的最佳锚尺寸。此外,就像之前关于寻找小人脸的论文一样,使用物体周围的背景也显著有助于检测。最后,他们采用了从高到低结合特征的FPN方法。
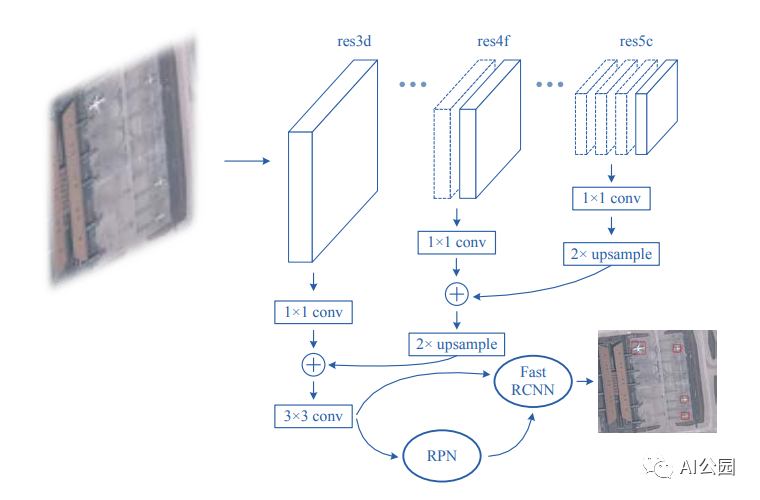
然而,架构并不是他们唯一改变和创新的东西。训练过程也得到了改进,并对训练结果产生了很大的影响。第一个变化是为训练平衡数据集的特定方式。他们通过多次处理一些图像来平衡数据集,而不是让它保持原样,然后调整损失函数来进行均衡类别的学习。这使得每个时代的阶级分布更加均匀。他们改变的第二件事是添加了一个随机旋转。因此,它们不是将图像旋转90或180度,而是将图像旋转一个随机生成的角度,例如13.53。这需要重新计算边界框,你可以在原始论文中看到公式。
Small Object Detection with Multiscale Features
本文作者也使用Faster-RCNN作为主要网络。他们所做的修改与FPN的想法相似 —— 将高层的特征与低层的特征结合起来。但是,他们没有迭代地组合层,而是将它们连接起来,并对结果运行1×1卷积。这在作者提供的体系结构可视化中得到了最好的体现。
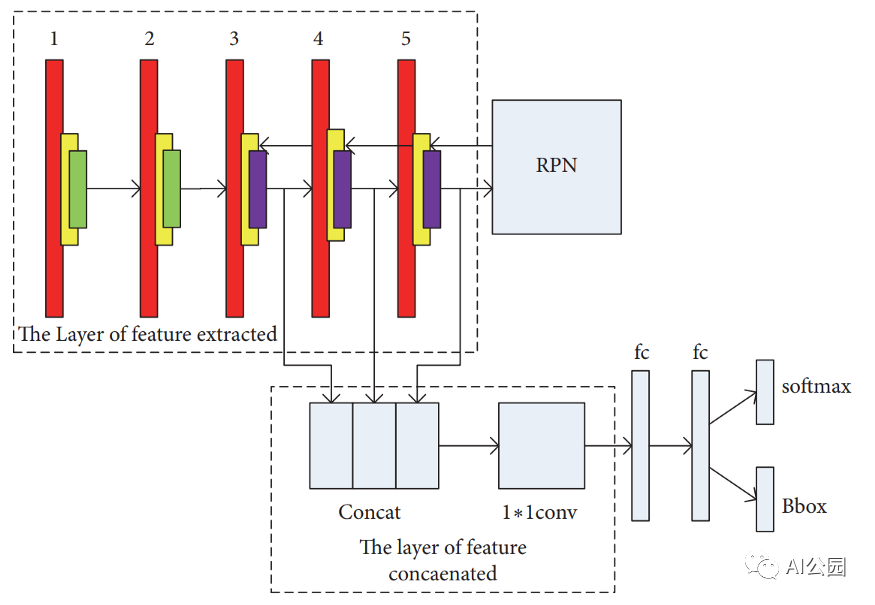
在结果表中,他们显示,与普通的Faster-RCNN相比,这种方法使mAP增加了0.1。
SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network
首先,在读到这种方法的名称后,你可能会想:“等等,使用GAN来检测目标?”。但请耐心等待,这种方法的作者做了一件相当聪明的事情。你可能之前就想到过:“如果物体都很小,为什么我们不放大它们呢?”简单地使用插值将图像放大的问题在于,对于原来的5×5的模糊的像素,我们将得到10×10(或20×20,或任何你设置的倍增因子)甚至更模糊的像素。这在某些情况下可能有所帮助,但通常情况下,这以处理更大的图像和更长时间的训练为代价,提供了相对较小的性能提升。但是如果我们有一种方法可以放大图像同时保留细节呢?这就是GANs发挥作用的地方。你可能知道,它们被证明在放大图像时非常有效。所谓的超分辨率网络(SRN)可以可靠地将图像缩放到x4倍,如果你有时间训练它们并收集数据集的话,甚至可以更高。
但作者们也不仅仅是简单地使用SRN来提升图像,他们训练SRN的目的是创建图像,使最终的检测器更容易找到小物体,检测器与生成器一起训练。因此,这里的SRN不仅用于使模糊的图像看起来清晰,而且还用于为小物体创建描述性特征。正如你在之前的图中看到的,它工作得很好,提供了一个显著的提高准确性。
总结
今天我们学到的是:
小目标检测仍然不是一个完全解决的问题, 上下文问题 放大图像是个好主意 结合不同层的输出 检查预训练网络的数据集,更好地评估其性能和利用它。
英文原文:https://medium.datadriveninvestor.com/small-objects-detection-problem-c5b430996162
来源:AI公园
 End
End
声明:部分内容来源于网络,仅供读者学术交流之目的。文章版权归原作者所有。如有不妥,请联系删除。