
机器学习概率基础:除了偏度、峰度还有矩量母函数
本篇介绍随机变量和概率分布的基本概念,以及有关概率分布的一些简单统计量,它们构成了概率和统计的基础知识。
11 基本概念
事件定义为样本空间的一个子集。例如,出现任意奇数点数的事件
没有样本点的事件称为空事件,用
至少发生了
另一方面,事件
如果事件
则
对照上面公式和下图,回忆一下中学集合论里的文氏图。

由集合的补集概念很容易想到所谓的补事件。样本空间中除去事件
22 概率
概率是对事件发生的可能性的度量,而事件
1.非负性:对于任意事件
2.归一性(幺正性):适用于整个样本空间。
3.可加性:对于不相交事件的任何可数序列,
从上述公理可以看出,事件
这同样使用于两个以上的事件:对于

投掷骰子示例(离散均匀分布
33 随机变量和概率分布
如果将概率分配给变量的每个取值,则该变量称为随机变量。概率分布是描述从随机变量的取值到概率的映射的函数。
可数集是其元素可以枚举为
其中,
投掷一个六面均匀的骰子
具有连续值的随机变量称为连续随机变量。如果连续随机变量
例如,旋转轮盘
比如,旋转轮盘赌的结果恰好是特定角度的可能性为零。
连续随机变量
称为累积分布函数。
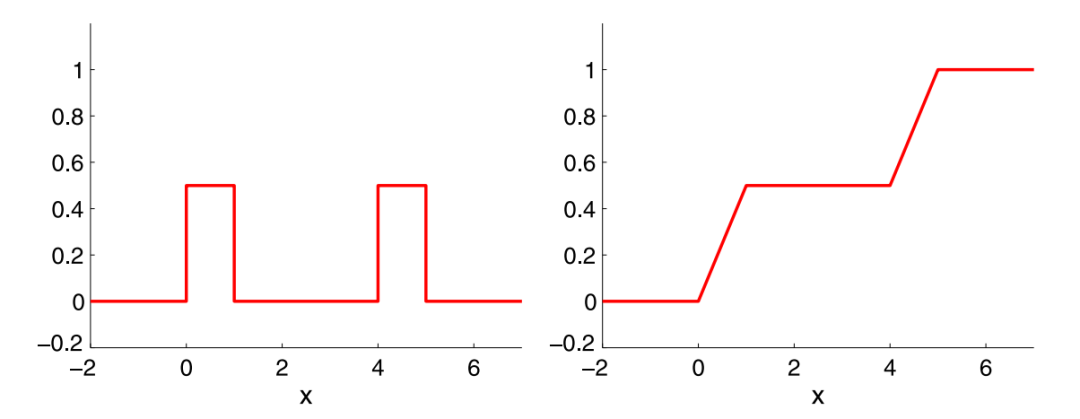
累积分布函数
单调非减:
时有 。 左极限:
。 右极限:
。
如果存在累积分布函数的导数,那么它就是概率密度函数:
上尾概率和下尾概率一起称为双侧概率,而它们中的任何一个都称为单侧概率。
44 概率分布的性质
在讨论概率分布的性质时,使用简单的统计量来概括概率质量/密度函数会带来方便。在本节中,将介绍此类统计量。
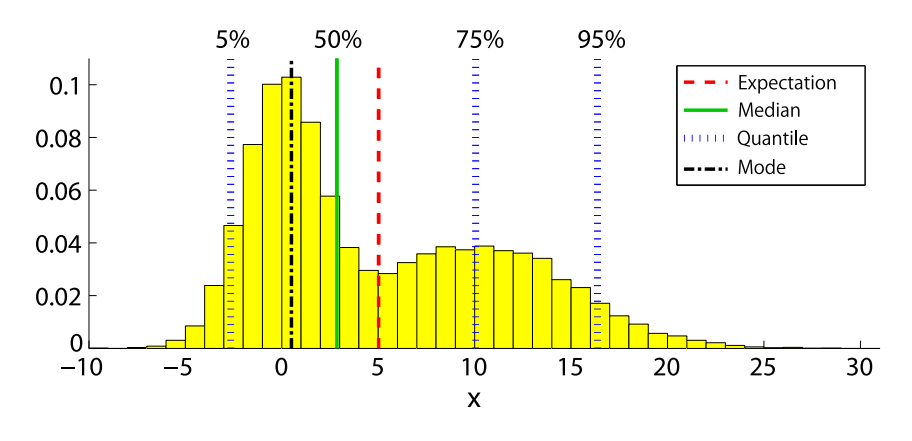
+数学期望、中位数和众数
数学期望(Expectation)字面上是指期望随机变量取到的值。当然用文字表达比较含糊,具体还是看公式。用
请注意,存在诸如柯西(Cauchy)分布之类的概率分布,它们的期望并不存在(例如趋于无穷大)。对于
对于常数
尽管期望代表了概率分布的中心,但当有异常值存在时,它与直观期望的差距可能很大。

例如,收入分配中,由于一个人赚取 100 万美元,直接把期望值拉高到 被平均。
在这种情况下,中位数(Median)比期望值更合适,中位数定义为使得下式成立的
也就是说,中位数是概率分布的中心,就其而言,它是不管从左侧还是右侧开始数的中间点。在示例中,中位数为
也就是说,
让我们考虑在区间
使得它取极小值的
取最小值的
使得它取极小值的
另一个常用的统计量是众数(Mode),它是一组数据中出现次数最多的数值,被定义为使得
+方差和标准差
尽管期望是表征概率分布的有用统计量,但是即使概率分布具有相同的期望,它们也可以不同。接下来我们引入另一个称为方差的统计量,以表示概率分布的分散情况。随机变量
实际上,可以将以上表达式展开,
通常会使计算变得更容易。对于常数
可以看到,这些性质与期望的性质完全不同。
方差的平方根称为标准差,用
通常,方差和标准差分别用
+偏度、峰度和矩
除了期望和方差之外,还经常使用诸如偏度(Skewness)和峰度(Kurtosis)之类的高阶统计量。偏度和峰度分别表示概率分布的不对称性和尖锐度,它们分别定义为
分母中的
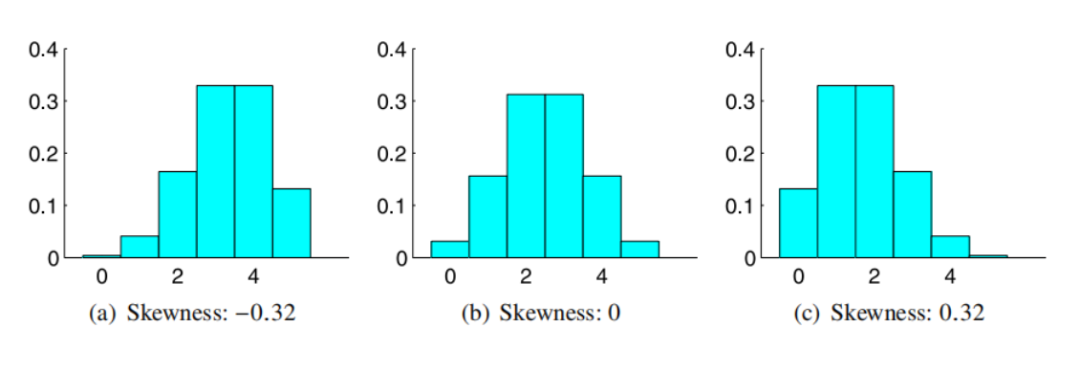
如上图所示,如果偏度为正,则右侧尾比左侧尾要长;如果偏度为负,则左侧尾比右侧尾长。如果偏度为零,则分布是完全对称的。

如上图所示,如果峰度为正,则概率分布比正态分布更尖锐;如果峰度为正,则概率分布比正态分布更钝。
以上讨论说明了该统计量,
在表征概率分布中起着重要作用。
被称为关于原点的第
期望值:
, 方差: 偏度:
峰度:
5矩量母函数
如果指定了期望、方差、偏度和峰度,那么概率分布在一定程度上就被确定下来了。但是,如果我们该如何用更多的特征来描述分布呢?
其实,像平均值、方差、偏度和峰度这些特征统一被称为矩,那么有没有一个函数能够计算所有矩呢?有的,那就是所谓的矩量母函数(Moment generating function)。有了它,我们可以通过微分来计算各种矩,而不是用积分算,这样就简化了计算。
作为一个极限情况,如果指定了所有阶的矩,那么概率分布可以唯一地确定下来。矩量母函数使我们能够系统地处理所有阶的矩:
的确,将零代入矩量母函数关于
下面证明了这一事实。
函数
两边分别计算期望,得
两边求导,得
将
对于某些概率分布,矩量母函数可能并不存在(例如发散到无穷大)。但它有个兄弟却是始终存在,即特征函数(Characteristic function),
其中
那么,这些函数有什么用途呢?关于这个我们下回再谈。