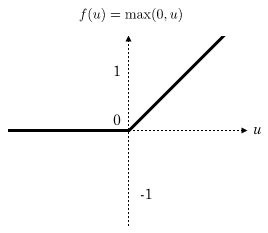
这一篇文章的主题是深度学习在基因组学中的应用情况的。文章较长,读完要花些时间,不过我的建议是通读第一部分——关于如何进行模型训练的内容,读完后你应该可以理解机器学习模型的训练过程和逻辑,剩下的部分可以挑重点的看。
基因组学其实是一门将数据驱动作为主要研究手段的学科,机器学习方法和统计学方法在基因组学中的应用一直都比较广泛。不过现在多组学数据进一步激增——这个从目前逐渐增多的各类大规模人群基因组项目上可以看出来,这其实带来了新的挑战——就是数据挖掘的难度增加了。我们要高效地从多组学数据中挖掘出有价值的信息,那么就需要掌握更富有表现力的方法,这个时候深度学习就成了一个合适的选择。因为就目前来说深度学习本身就适合用来挖掘大量的、多维度数据背后的潜在规则,它也已经改变了多个计算机领域,包括图片识别、人脸识别、机器翻译、自然语言处理等。近年来深度学习在基因组学领域也有了不少的研究和应用,我这篇文章主要基于 Nature Reviews Genetics 上《Deep learning- new computational modelling techniques for genomics》的内容,同时我也做了一些额外的补充,目的是和大家一起梳理一下目前深度学习在基因组学研究方面的应用情况。- 第一,介绍有监督学习中四个主要的神经网络,分别是:全连接网络、深度卷积、循环卷积和图卷积,同时解释了如何将它们用来抽取基因组数据中常见的 Pattern;
- 第二,介绍多任务学习和多模态学习,这是两种适合于集成多维数据集的建模方法;
- 第三,讨论迁移学习,这是一种可以从现有模型中开发新模型的技术。这个方法对于多组学的研究和应用来说有着实际的价值;
- 第四,讨论自动编码器(Autoencoder, AE)和生成对抗网络(generative adversarial networks,GANs)这两个非监督学习方法。
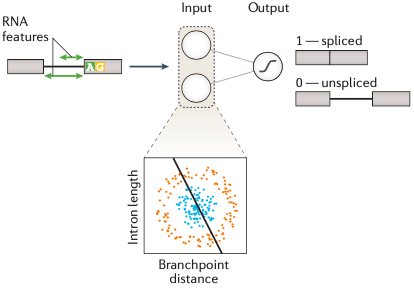
好,接下来,我将逐一展开介绍这四个方面的内容,同时为了让你可以更好地理解这篇文章,我穿插补充了一些关于机器学习的背景知识。这一部分的内容与有监督学习有关,因此我们要先了解什么是“有监督学习”。简单来说,有监督学习的过程是输入样本的特征值(这个特征值可以是一个值,也可以由是一系列值构成的向量),然后预测出样本属于哪一个结果标签(或叫做“标注”)。比如 图1 是一个预测 RNA 剪接位点的例子,这里模型要依据样本的特征值(如:位点序列信息、位置、内含子长度等)进行计算得到一个是否为剪接位点的预测结果。另外,图1 其实是一个由逻辑回归组成的单层神经网络分类模型。
所以,有监督学习是一种需要使用标签化数据进行训练,然后推断出输入特征和结果标签之间函数映射关系的机器学习方法,模型的训练数据需要有明确的结果标签,否则不能训练。搞清楚定义之后,那有监督机器学习是如何进行模型训练的呢?所谓训练其实就是求解模型参数。
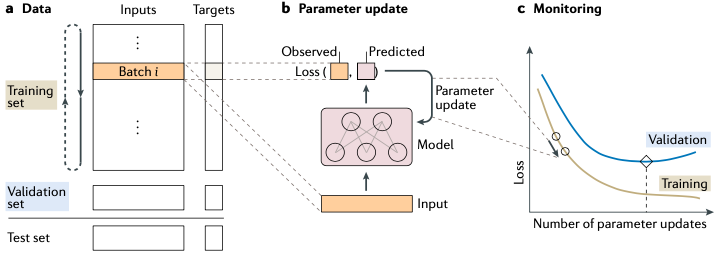 图2. 模型训练这个训练过程一共三步(图2)——这也是绝大多数机器学习算法进行模型训练的方式,具体如下:首先,要将训练数据分割为三个集合,分别是:训练集,验证集和测试集(如图2.a) 。其中,训练集用于模型参数的计算,验证集用于模型性能评估和超参调整,目的是为了保障模型可以在现有数据条件下达到最好的结果,而测试集则是用来评测最终模型的综合性能。还是以图2为例——我们这里图2是一个神经网络模型,训练开始时,首先要给这个网络中的各个参数进行一次随机初始化,然后再代入训练数据去迭代更新模型参数。每一次的迭代时,通常都是随机地从训练集中抽取一小撮数据(图2.a中的Batch)代入模型进行计算——注意这个过程非常重要,然后和真实结果比较获得函数损失量。在神经网络的训练中目前要通过反向传播算法做梯度运算获得能让模型的参数往损失函数最小化的方向走的值,模型的参数要依据这个极值的结果进行更新。接着再重新到训练数据中随机抽取另一小撮的数据集重复这一轮迭代,直到损失函数收敛。
图2. 模型训练这个训练过程一共三步(图2)——这也是绝大多数机器学习算法进行模型训练的方式,具体如下:首先,要将训练数据分割为三个集合,分别是:训练集,验证集和测试集(如图2.a) 。其中,训练集用于模型参数的计算,验证集用于模型性能评估和超参调整,目的是为了保障模型可以在现有数据条件下达到最好的结果,而测试集则是用来评测最终模型的综合性能。还是以图2为例——我们这里图2是一个神经网络模型,训练开始时,首先要给这个网络中的各个参数进行一次随机初始化,然后再代入训练数据去迭代更新模型参数。每一次的迭代时,通常都是随机地从训练集中抽取一小撮数据(图2.a中的Batch)代入模型进行计算——注意这个过程非常重要,然后和真实结果比较获得函数损失量。在神经网络的训练中目前要通过反向传播算法做梯度运算获得能让模型的参数往损失函数最小化的方向走的值,模型的参数要依据这个极值的结果进行更新。接着再重新到训练数据中随机抽取另一小撮的数据集重复这一轮迭代,直到损失函数收敛。反向传播算法是神经网络模型的基础,没有这个算法就无法高效地实现梯度下降算法中梯度值的计算。
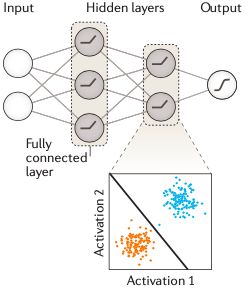
这种训练时仅从训练集里随机抽取一小撮数据集的做法与一次性使用整个训练集的做法相比有两个好处:- 第一,模型训练所需的内存将比较恒定。因为不必将大量的数据一次性加载到内存里,因此,模型能不受计算机的内存所限,可以使用尽可能大的训练集数据,训练过程的可拓展性比较高;
- 第二,在机器学习领域其实已经证明,这种小批量数据集的方法会给模型带来一定程度的随机波动,而这种波动有利于模型性能的提升。
所谓超参,就是“超级参数”,它是模型中一个(或一些)需要人为设定的外部参数,而且是无法通过训练集进行训练的,只能进行手动调整。比如,我们要在进行模型训练之前,先给模型的某部分乘上某一个固定的常数/向量,这个常数/向量无法训练,它就是“超参”。通常只能一边调整一边在验证集上评估结果,最后留下一个“看起来”能够最准确贴近验证结果的参数。这是一个很繁琐的过程,需要多次尝试,直至模型性能不再出现改善为止。当你完成最后的调参之后,用另一个独立数据——也就是这里的测试集,综合评估这个最佳模型的性能,主要是看看是否存在过拟合或者功效不足的情况,没问题之后就可以用到项目中了。以上,就是训练一个神经网络模型的主要过程。再次强调一次:一共是三步,分别是:分割数据、使用训练集计算模型参数、通过验证集调整模型超参并用测试数据综合评估最终模型的性能。了解了以上背景内容之后,我们就可以转入深度学习的内容了。对于很多比较简单的问题而言,一个单层的神经网络通常是可以满足要求的。但对于维度更多、更复杂的生物学问题来说,单层是不够用的,只能通过更复杂的模型才能处理这类数据。图3是一个多层神经网络模型的示意图。这个网络有两层,而且你可以看到中间一层不与输出层相连接,对于输出来说是一个不可见的“层”,所以也被称为隐藏层,它的作用是将上一层的输入数据做转换,将其映射到一个可以对特征值进行线性分离的空间,然后通过激活函数进行非线性化,再给到后一层作为输入。这个模型是深度神经网络的雏形,当你的模型有许多个中间隐藏层(>2)时,这个模型就称之为深度神经网络模型。深度神经网络使用隐藏层来自动学习非线性特征的各类变换。模型里的每一个隐藏层都可以是多个线性模型叠加一个激活函数所构成,激活函数非常重要,它起到了将线性模型非线性化的作用,否则你的模型就无法通过非线性的形式描述真实世界的生物学问题(因为这些问题本身通常就是线性模型无法解答的)。目前深度学习中用得最多的激活函数是ReLU,这是一个线性整流函数(负数赋值为0,正数不变):深度学习模型的训练也和上面所术的过程一致。区别就在于,它涉及的参数多,需要更多的训练数据和更长的时间才能得到理想的结果。对于我们来说深度神经网络的构建和训练可以用专门的深度学习框架来实现,比如:TensorFlow、PyTorch和Keras等。在说完上面的关于模型训练的内容之后,接下来要说的是第一部分中的第一个概念:全连接网络层(Fully connected layer)。全连接网络层一般是深度学习模型的倒数第二、第三层,它在网络中主要起分类器的作用,本质上就是将前面各层训练得到的特征空间线性地变换到另一个特征空间(即,结果空间——其实就是结果集)中。结果空间的每一个维度都会受到源空间所有维度的影响,数据被利用得很充分,所以可以很准确地将获得分类结果。这么说比较抽象的话,可以通俗理解为,经过全连接层的计算之后,目标预测结果就是前面各层结果的加权和了。以全连接层结成的神经网络也叫全连接神经网络,全连接神经网络在基因组学里也都有所应用,比如一开始我提到的剪接位点预测,还有致病突变预测、基因表达预测特定基因区域内顺式调控元件的预测等,但全连接层神经网络运算量很大。接下来,我们用深度卷积神经网络(也就是CNN)作为例子,介绍序列模式特征的发现过程。如图5 所示,这个模型要通过神经网络预测TAL1-GATA1转录因子复合物的结合亲和力。
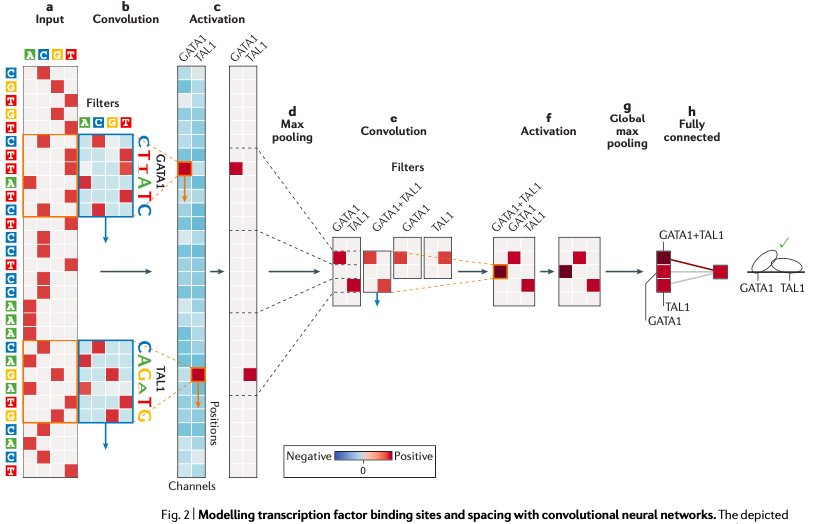 图5. 基于CNN的序列模式特征检测图中,从左到右,第一层分别以 GATA1 和 TAL1 转录因子的位置为权重滤波器,滑动扫描整个 DNA 序列,然后卷积计算每一个扫描框中的结果形成一个权重矩阵(b-c),再使用 ReLU 激活函数——这个激活函数会将负值重新赋为0,正值则保持不变,进一步做运算。然后再用最大池化操作(图中的Max pooling),获取位置轴上各个连续窗口内的最大加权结果,再传入下一个卷积层进行新一轮的运算和特征训练,过程与第一个卷积层类似,最后再经过一个全连接层,得到最终想要的预测结果。目前利用 CNN 对序列特征预测转录因子结合位点的方法有三个,分别是DeepBind、DeepSEA和Basset。而且这是目前 CNN 在基因组序列特征预测方面做的比较成功的例子。介绍完CNN之后,我们开始探讨循环卷积神经网络——简称RNN。鉴于它的特征,目前它主要在基因组远端调控预测方面有所运用。这是因为 RNN 相比于 CNN,它更加适合用于处理序列化的数据,包括时间序列数据、语言数据、文字翻译以及 DNA 序列数据,而且 RNN 对每一段序列单元都使用相同的操作,参数之间由一定的方式进行共享。
图5. 基于CNN的序列模式特征检测图中,从左到右,第一层分别以 GATA1 和 TAL1 转录因子的位置为权重滤波器,滑动扫描整个 DNA 序列,然后卷积计算每一个扫描框中的结果形成一个权重矩阵(b-c),再使用 ReLU 激活函数——这个激活函数会将负值重新赋为0,正值则保持不变,进一步做运算。然后再用最大池化操作(图中的Max pooling),获取位置轴上各个连续窗口内的最大加权结果,再传入下一个卷积层进行新一轮的运算和特征训练,过程与第一个卷积层类似,最后再经过一个全连接层,得到最终想要的预测结果。目前利用 CNN 对序列特征预测转录因子结合位点的方法有三个,分别是DeepBind、DeepSEA和Basset。而且这是目前 CNN 在基因组序列特征预测方面做的比较成功的例子。介绍完CNN之后,我们开始探讨循环卷积神经网络——简称RNN。鉴于它的特征,目前它主要在基因组远端调控预测方面有所运用。这是因为 RNN 相比于 CNN,它更加适合用于处理序列化的数据,包括时间序列数据、语言数据、文字翻译以及 DNA 序列数据,而且 RNN 对每一段序列单元都使用相同的操作,参数之间由一定的方式进行共享。
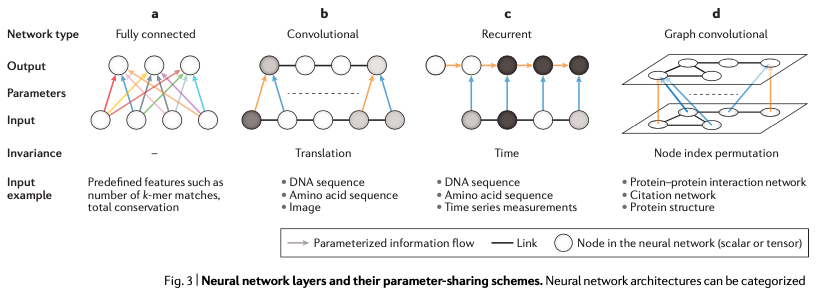 图6. RNN鉴于 RNN 模型的这些特点,它既可以有效地在DNA序列的任意位置上进行开放读码框的预测,也可以用来识别某类特定的输入序列,比如起始密码子预测、终止密码子预测等。相比于CNN,RNN模型的主要优势在于,RNN模型可以很自然地处理长度变化很大的DNA序列,比如mRNA序列就很适合通过RNN模型来进行处理和分析。如果CNN要达到类似的效果,需要作出很多繁琐的模型调整。不过,由于 RNN 只能对序列进行从前到后的顺序操作,因此也不太容易进行并行化处理,这就导致它的速度要比 CNN 模型慢很多。在基因组学的应用方面,RNN 主要是用在单细胞 DNA 甲基化预测、RNA binding protein预测和表观遗传学中DNA长序列可及性的预测(也就是长序列调控的预测)。如果你对这一块感兴趣可以试试 deepTarget/deepMiRGene,它们就是干这些事情的。此外,最近有一项研究发现,RNN模型还可用在测序数据的碱基识别(即Base-calling)。这在三代测序数据的Base-calling中有应用,DeepNano 就是通过构造合适的 RNN 模型对 Oxford Nanopore 测序仪所产出的长读长测序序列进行碱基识别的方法。图卷积神经网络模型(GCN)图6(d),在基因组学中涉及的应用还很少。它比较合适的应用场景是蛋白质之间互作用的网络或者基因与基因之间的调控网络上。因为这两个方面的网络,在逻辑上都将是以图结构的形式呈现。图卷积神经网络通过图中代表个体特征的节点和节点与节点之间的连接性来实行机器学习任务。虽然应用还比较少,但GCN实际上提供了一种分析图结构数据的新方法,值得在基因组学中进行更多的尝试和应用,比如可以尝试利用它来解决肿瘤亚型的分类等。第二部分要介绍的内容是“多任务学习和多模态学习”。之所以涉及到这个方面,是因为基因数据实际上并非只有 DNA 序列这一类遗传方面的数据,还涉及到转录组、表观组修饰、蛋白组等多组学数据,而且数据在彼此之间存在着一定的内在关系。如何处理和整合这些多组学数据就涉及到“多任务和多模态学习”这个问题了。在多模态学习模型的构成中,它有一个总损失函数,它的值是各个模态数据损失函数之和或者加权和,这取决于各个模态之间损失函数的结果是否差异巨大。下面图7.a-c 是一个多任务和多模态学习的示意图。这类模型的训练往往比较困难,因为需要同时优化学习网络中多个不同的损失函数,并且往往还得做出合适的取舍,每一个取舍都要有合理的内在理由。而且如果不同的类型的数据之间,出现了较为严重的权重失衡的话——比如出现”一超无强”的情况,那么最终的模型可能仅能代表一小撮数据的结果,这就会让模型出现严重偏差。
图6. RNN鉴于 RNN 模型的这些特点,它既可以有效地在DNA序列的任意位置上进行开放读码框的预测,也可以用来识别某类特定的输入序列,比如起始密码子预测、终止密码子预测等。相比于CNN,RNN模型的主要优势在于,RNN模型可以很自然地处理长度变化很大的DNA序列,比如mRNA序列就很适合通过RNN模型来进行处理和分析。如果CNN要达到类似的效果,需要作出很多繁琐的模型调整。不过,由于 RNN 只能对序列进行从前到后的顺序操作,因此也不太容易进行并行化处理,这就导致它的速度要比 CNN 模型慢很多。在基因组学的应用方面,RNN 主要是用在单细胞 DNA 甲基化预测、RNA binding protein预测和表观遗传学中DNA长序列可及性的预测(也就是长序列调控的预测)。如果你对这一块感兴趣可以试试 deepTarget/deepMiRGene,它们就是干这些事情的。此外,最近有一项研究发现,RNN模型还可用在测序数据的碱基识别(即Base-calling)。这在三代测序数据的Base-calling中有应用,DeepNano 就是通过构造合适的 RNN 模型对 Oxford Nanopore 测序仪所产出的长读长测序序列进行碱基识别的方法。图卷积神经网络模型(GCN)图6(d),在基因组学中涉及的应用还很少。它比较合适的应用场景是蛋白质之间互作用的网络或者基因与基因之间的调控网络上。因为这两个方面的网络,在逻辑上都将是以图结构的形式呈现。图卷积神经网络通过图中代表个体特征的节点和节点与节点之间的连接性来实行机器学习任务。虽然应用还比较少,但GCN实际上提供了一种分析图结构数据的新方法,值得在基因组学中进行更多的尝试和应用,比如可以尝试利用它来解决肿瘤亚型的分类等。第二部分要介绍的内容是“多任务学习和多模态学习”。之所以涉及到这个方面,是因为基因数据实际上并非只有 DNA 序列这一类遗传方面的数据,还涉及到转录组、表观组修饰、蛋白组等多组学数据,而且数据在彼此之间存在着一定的内在关系。如何处理和整合这些多组学数据就涉及到“多任务和多模态学习”这个问题了。在多模态学习模型的构成中,它有一个总损失函数,它的值是各个模态数据损失函数之和或者加权和,这取决于各个模态之间损失函数的结果是否差异巨大。下面图7.a-c 是一个多任务和多模态学习的示意图。这类模型的训练往往比较困难,因为需要同时优化学习网络中多个不同的损失函数,并且往往还得做出合适的取舍,每一个取舍都要有合理的内在理由。而且如果不同的类型的数据之间,出现了较为严重的权重失衡的话——比如出现”一超无强”的情况,那么最终的模型可能仅能代表一小撮数据的结果,这就会让模型出现严重偏差。
 图7. 多任务与多模态学习模型基因组学领域,已经成功应用多任务学习和多模态学习的一个场景是对多种不同的分子表型的预测,比如前面提到的转录因子结合位点、组蛋白标记、DNA可及性分析和不同组织中的基因表达等这一类与转录组学和表观基因组学相关的多组学研究。迁移学习与上述内容都不同,它是一种解决训练数据稀缺问题的机器学习方法。因为数据稀缺或者数据缺失的情况下,从头训练整个模型可能是不可行的。那么一个取而代之的方法就是使用相似结构的任务,以及由它训练得到的模型的大多数参数来初始化我们的目标模型。你可以理解为,这是一种将先验知识整合到新模型中的机器学习方法,它可以在一定程度上解决训练数据不足的问题。比如 图8 这个例子,你可以看到在这个例子中,源模型的数据很充足,且源模型中第一个子模型的结构和预测结果的形式都跟目标模型相似(都是椭圆),那么这时我们就可以将源模型里这个子模型的相关参数迁移到下方的目标模型里,对目标模型进行初始化,接着再利用有限的训练数据对目标模型进行更新就可以了。
图7. 多任务与多模态学习模型基因组学领域,已经成功应用多任务学习和多模态学习的一个场景是对多种不同的分子表型的预测,比如前面提到的转录因子结合位点、组蛋白标记、DNA可及性分析和不同组织中的基因表达等这一类与转录组学和表观基因组学相关的多组学研究。迁移学习与上述内容都不同,它是一种解决训练数据稀缺问题的机器学习方法。因为数据稀缺或者数据缺失的情况下,从头训练整个模型可能是不可行的。那么一个取而代之的方法就是使用相似结构的任务,以及由它训练得到的模型的大多数参数来初始化我们的目标模型。你可以理解为,这是一种将先验知识整合到新模型中的机器学习方法,它可以在一定程度上解决训练数据不足的问题。比如 图8 这个例子,你可以看到在这个例子中,源模型的数据很充足,且源模型中第一个子模型的结构和预测结果的形式都跟目标模型相似(都是椭圆),那么这时我们就可以将源模型里这个子模型的相关参数迁移到下方的目标模型里,对目标模型进行初始化,接着再利用有限的训练数据对目标模型进行更新就可以了。
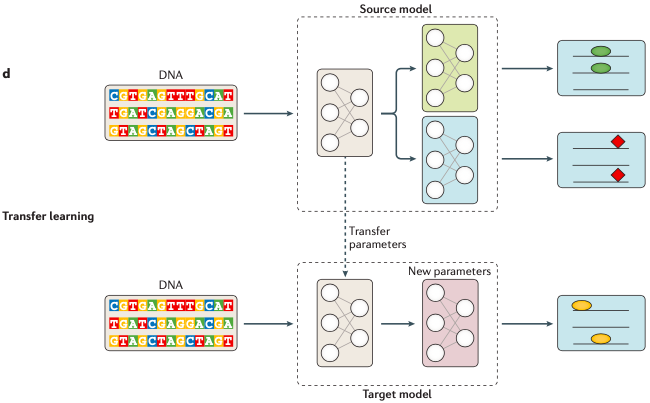 图8. 迁移学习在基因组学中,远程调控的预测模型就应用到了迁移学习。不过迁移学习在组学方面的应用还缺少深入的研究,比如目前依然不清楚应该如何选择合适的源模型、以及源模型中有哪些参数适合共享到目标模型中等。这个问题对于深度学习来说是天生的,但它关系着深度学习是否适合被充分应用到生命健康领域。我们知道深度学习模型的一个问题是黑盒子效应——我们无法得知模型的具体训练细节以及中间特征参数的变化。这对于基因组学研究来说是不利的,这是因为组学研究最后的服务对象是我们人类自身的健康(特别是重大的健康问题),没有人真的愿意将重大的健康问题交给一个没人理解的黑盒子处理,所以我们还是有必要对深度学习模型的可解释性进行一定的研究。但遗憾的是目前对深度学习模型的黑盒子效应,似乎尚未有特别有效的解密方法。目前主要是通过不断给出示例数据,探查输入和输出结果之间的关系来推测和评估模型所用到的特征和权重,给出特征重要性评分(Feature important score),可用的方法包括:归因分数、相关性系数或权重共享系数等。不过在深度学习领域,最近有一个称为DCell的模型,它提出了一种称为“可见神经网络”的技术,通过它可以检查神经网络的训练情况,进而再改善神级网络的可解释性。最后这部分讨论非监督学习在基因组学方面应用的问题,这里主要介绍自动编码机(Autoencoder, AE)和生成对抗网络(generative adversarial networks,GANs)这两类非监督学习方法,其中生成对抗网络在基因组学的首次应用是在单细胞基因组研究中。非监督学习与有监督学习不同,它的训练数据并不需要标记。模型的目的是通过学习数据集中有用的特征和属性来表征整个数据集的结构。最典型、最被熟知的非监督学习方法就是k-means聚类和降维算法(如PCA、tSNE)。神经网络也有类似的方法,比如自动编码机(AE),就是一种能够将数据嵌入到一个含有隐藏瓶颈层的低维空间中并对原始数据进行重建的方法,如图9所示。这个方法很特别,而且非常有用的一点是它能够对原始数据进行有效的“降噪”!这是因为网络中间有一个维度较低的瓶颈层存在,它会迫使网络在学习的过程中尽可能提取更有用的特征,那些不重要的特征变化会被自动遗漏。而且,在该瓶颈层中的数据已经实现了降维,这个正好可以与PCA相呼应。另外,自动编码机适合用于缺失数据的填补,特别是可以用来填补基因芯片数据的缺失值和处理RNA-seq中基因表达数据中的异常值处理。另一个非监督神经网络是生成模型。生成模型不同于前面提到的方法,它的目的是学习数据的生成过程。代表性的例子就是生成对抗网络(GANs)和可变自动编码器(VAEs)。其中,VAEs方法可以生成新的随机样本,可以用在单细胞和RNA-seq数据中,用来协助寻找统计意义的结果。GANs是另一种生成模型,它包含一个鉴别器和一个生成器网络。这两个网络会进行共同训练,生成器用来生成真实的数据点,而鉴别器则用于区分样本是真实的或是由生成器所生成,图9(c)也是对该过程的一个描述。不过目前GANs,在基因组学中的应用非常有限,目前只看到在设计和蛋白质相关的DNA探针方面有所应用。关于目前深度学习在基因组学方面的应用和研究情况就介绍到这里了。在未来深度学习肯定是会深刻影响这个领域的,具体来说主要有三个方面:
图8. 迁移学习在基因组学中,远程调控的预测模型就应用到了迁移学习。不过迁移学习在组学方面的应用还缺少深入的研究,比如目前依然不清楚应该如何选择合适的源模型、以及源模型中有哪些参数适合共享到目标模型中等。这个问题对于深度学习来说是天生的,但它关系着深度学习是否适合被充分应用到生命健康领域。我们知道深度学习模型的一个问题是黑盒子效应——我们无法得知模型的具体训练细节以及中间特征参数的变化。这对于基因组学研究来说是不利的,这是因为组学研究最后的服务对象是我们人类自身的健康(特别是重大的健康问题),没有人真的愿意将重大的健康问题交给一个没人理解的黑盒子处理,所以我们还是有必要对深度学习模型的可解释性进行一定的研究。但遗憾的是目前对深度学习模型的黑盒子效应,似乎尚未有特别有效的解密方法。目前主要是通过不断给出示例数据,探查输入和输出结果之间的关系来推测和评估模型所用到的特征和权重,给出特征重要性评分(Feature important score),可用的方法包括:归因分数、相关性系数或权重共享系数等。不过在深度学习领域,最近有一个称为DCell的模型,它提出了一种称为“可见神经网络”的技术,通过它可以检查神经网络的训练情况,进而再改善神级网络的可解释性。最后这部分讨论非监督学习在基因组学方面应用的问题,这里主要介绍自动编码机(Autoencoder, AE)和生成对抗网络(generative adversarial networks,GANs)这两类非监督学习方法,其中生成对抗网络在基因组学的首次应用是在单细胞基因组研究中。非监督学习与有监督学习不同,它的训练数据并不需要标记。模型的目的是通过学习数据集中有用的特征和属性来表征整个数据集的结构。最典型、最被熟知的非监督学习方法就是k-means聚类和降维算法(如PCA、tSNE)。神经网络也有类似的方法,比如自动编码机(AE),就是一种能够将数据嵌入到一个含有隐藏瓶颈层的低维空间中并对原始数据进行重建的方法,如图9所示。这个方法很特别,而且非常有用的一点是它能够对原始数据进行有效的“降噪”!这是因为网络中间有一个维度较低的瓶颈层存在,它会迫使网络在学习的过程中尽可能提取更有用的特征,那些不重要的特征变化会被自动遗漏。而且,在该瓶颈层中的数据已经实现了降维,这个正好可以与PCA相呼应。另外,自动编码机适合用于缺失数据的填补,特别是可以用来填补基因芯片数据的缺失值和处理RNA-seq中基因表达数据中的异常值处理。另一个非监督神经网络是生成模型。生成模型不同于前面提到的方法,它的目的是学习数据的生成过程。代表性的例子就是生成对抗网络(GANs)和可变自动编码器(VAEs)。其中,VAEs方法可以生成新的随机样本,可以用在单细胞和RNA-seq数据中,用来协助寻找统计意义的结果。GANs是另一种生成模型,它包含一个鉴别器和一个生成器网络。这两个网络会进行共同训练,生成器用来生成真实的数据点,而鉴别器则用于区分样本是真实的或是由生成器所生成,图9(c)也是对该过程的一个描述。不过目前GANs,在基因组学中的应用非常有限,目前只看到在设计和蛋白质相关的DNA探针方面有所应用。关于目前深度学习在基因组学方面的应用和研究情况就介绍到这里了。在未来深度学习肯定是会深刻影响这个领域的,具体来说主要有三个方面:- 第一,协助对非编码区变异的功能进行预测,这是目前传统方法做得比较差的一个方面;
- 第二,深度学习是一种完全由数据驱动的方法,它会进一步革新当前的生物信息学工具,我可以将它称为新生信,这个也是目前最热的,除了文章中所提到的新算法之外,变异检测算法DeepVariants和Clair也属于这一方面;
除此之外,对于未来还有一个非常重要的领域,那就是因果推断。不管是传统的机器学习方法,或是现在的深度学习方法,都很难用于预测数据之间的因果联系,而因果关系对于生命科学研究来说十分重要,目前虽有过一些尝试——比如孟德尔随机,但其实都比较初步。总的来说,这是一个很值得我们去进一步探索的地方,可以从零开始,而这也是我们的机会!
最后还有一句话:不要迷信模型。模型是解决问题的工具,用好工具是我们的追求,但问题的解决应以人为本。
参考文献
Deep learning- new computational modelling techniques for genomics
What I cannot create, I do not understand.- Richard P.Feynman(理查德.菲利普斯.费曼)
机器学习系列教程
从随机森林开始,一步步理解决策树、随机森林、ROC/AUC、数据集、交叉验证的概念和实践。
文字能说清的用文字、图片能展示的用、描述不清的用公式、公式还不清楚的写个简单代码,一步步理清各个环节和概念。
再到成熟代码应用、模型调参、模型比较、模型评估,学习整个机器学习需要用到的知识和技能。
机器学习算法 - 随机森林之决策树初探(1)
机器学习算法-随机森林之决策树R 代码从头暴力实现(2)
机器学习算法-随机森林之决策树R 代码从头暴力实现(3)
机器学习算法-随机森林之理论概述
随机森林拖了这么久,终于到实战了。先分享很多套用于机器学习的多种癌症表达数据集 https://file.biolab.si/biolab/supp/bi-cancer/projections/。
机器学习算法-随机森林初探(1)
机器学习 模型评估指标 - ROC曲线和AUC值
机器学习 - 训练集、验证集、测试集
机器学习 - 随机森林手动10 折交叉验证
一个函数统一238个机器学习R包,这也太赞了吧
基于Caret和RandomForest包进行随机森林分析的一般步骤 (1)
Caret模型训练和调参更多参数解读(2)
机器学习相关书籍分享
基于Caret进行随机森林随机调参的4种方式
送你一个在线机器学习网站,真香!
UCI机器学习数据集
机器学习第17篇 - 特征变量筛选(1)
机器学习第18篇 - 基于随机森林的Boruta特征变量筛选(2)
机器学习系列补充:数据集准备和更正YSX包
机器学习第20篇 - 基于Boruta选择的特征变量构建随机森林
机器学习第21篇 - 特征递归消除RFE算法 理论
RFE筛选出的特征变量竟然是Boruta的4倍之多
更多特征变量却未能带来随机森林分类效果的提升
一图感受各种机器学习算法