
独家 | Python的“predict_prob”方法不能真实反映预测概率校准(如何实现校准)

作者: Samuele Mazzanti
翻译:欧阳锦
校对:王可汗
本文约2300字,建议阅读8分钟
图源自作者
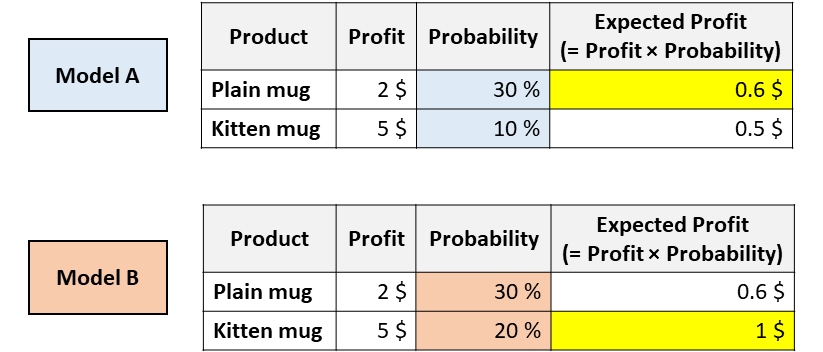
“predict_proba”的问题
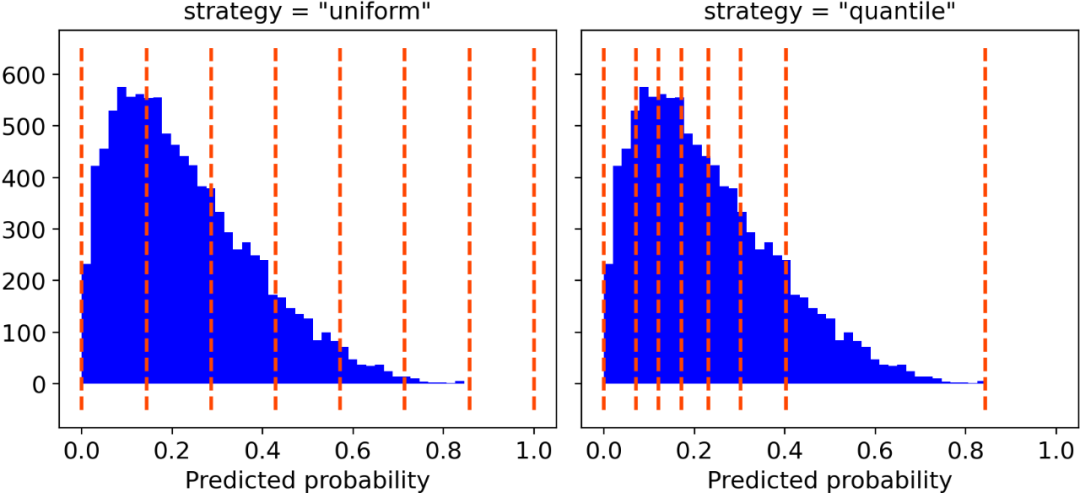
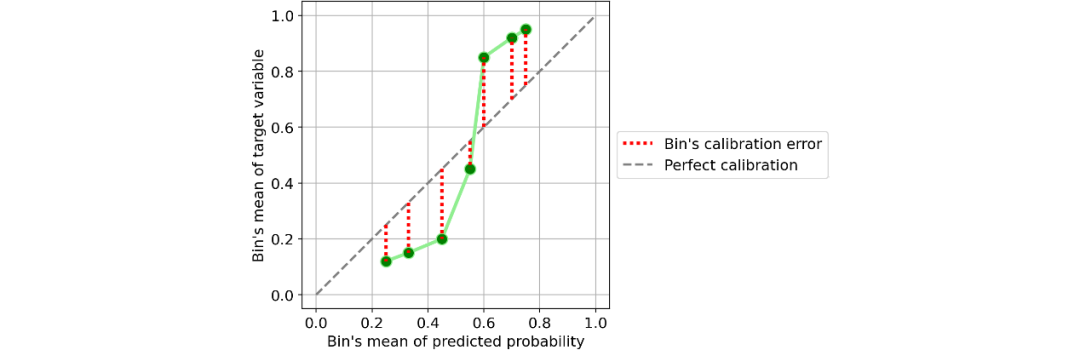
校准曲线

“uniform”,一个0-1的间隔被分为n_bins个类,它们都具有相同的宽度;
“quantile”,类的边缘被定义,从而使得每个类都具有相同数量的观测值。

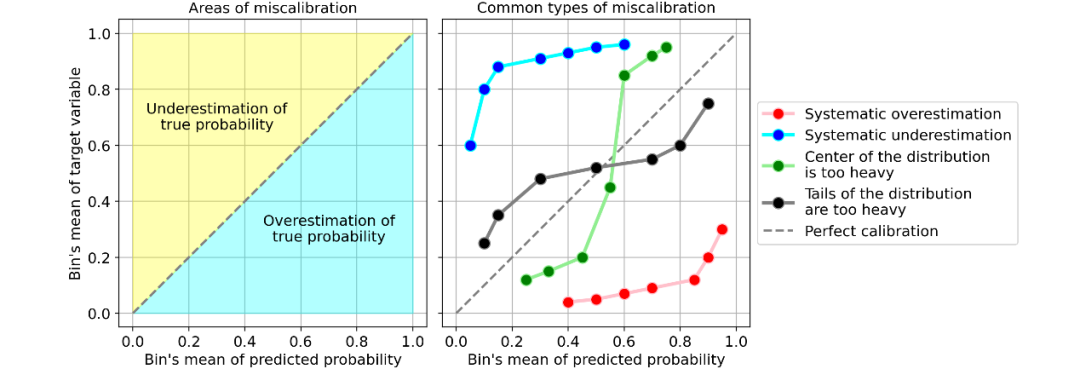
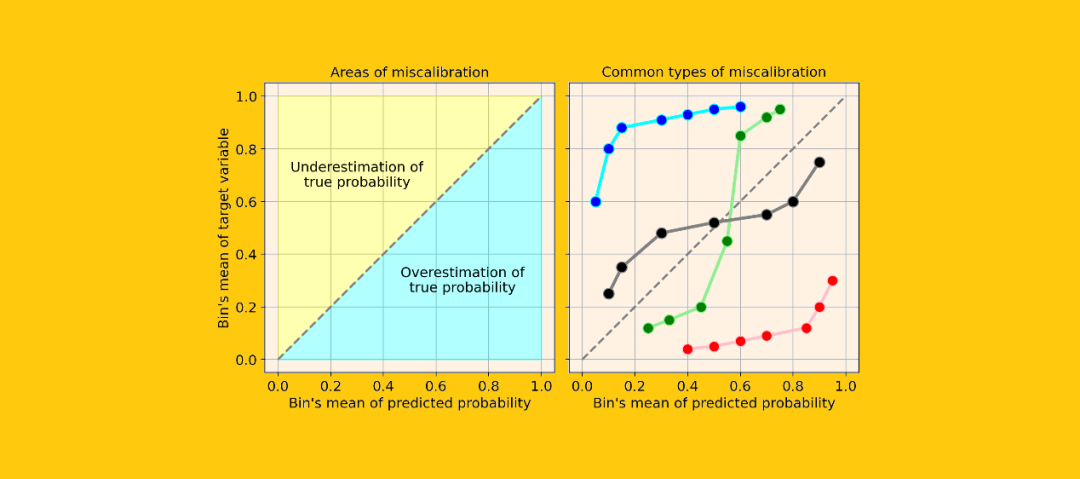
系统高估。与真实分布相比,预测概率的分布整体偏右。当您在正数极少的不平衡数据集上训练模型时,这种错误校准很常见。(如红线)
系统低估。与真实分布相比,预测概率的分布整体偏左。(如蓝线)
分布中心太重。当“支持向量机和提升树之类的算法趋向于将预测概率推离0和1”(引自《Predicting good probabilities with supervised learning》)时,就会发生这类错误校准。(如绿线)
分布的尾巴太重。例如,“其他方法(如朴素贝叶斯)具有相反的偏差(bias),并且倾向于将预测概率趋近于0和1”(引自《Predicting good probabilities with supervised learning》)。(如黑线)
如何解决校准错误(Python)
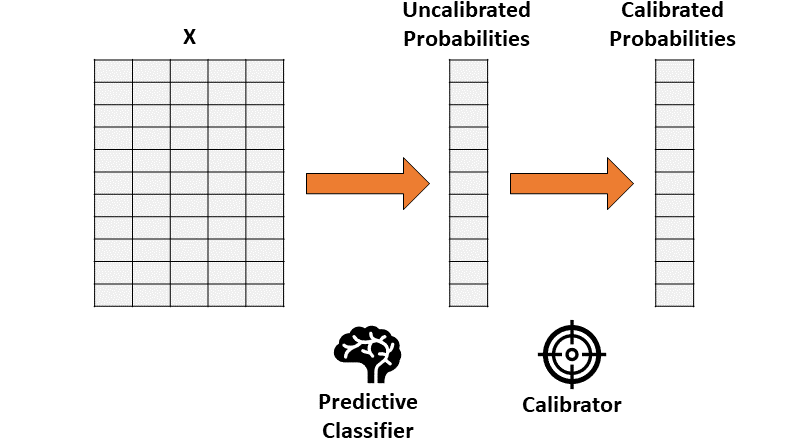
保序回归。一种非参数算法,这种非参数算法将非递减的自由格式行拟合到数据中。行不会减少这一事实是很重要的,因为它遵从原始排序。
逻辑回归。
看看使用Python如何在玩具数据集中实际应用校准器:
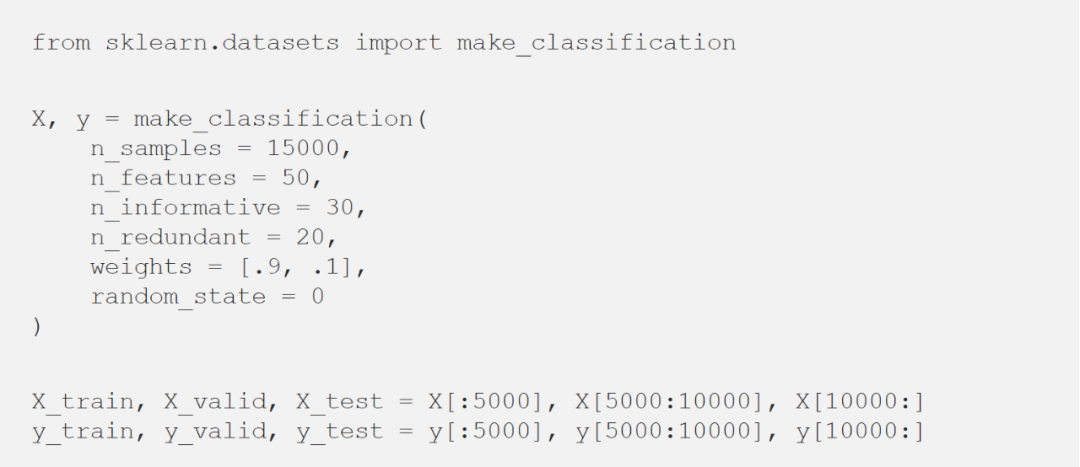

保序回归

逻辑回归
量化校准错误
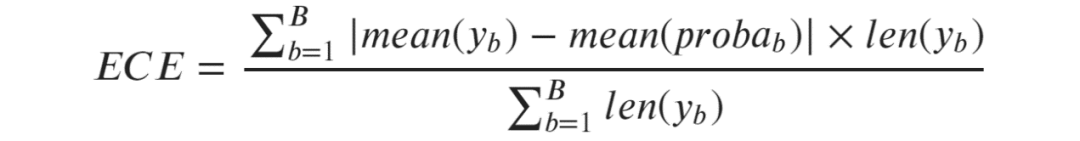


引用
«Predicting good probabilities with supervised learning» (2005) by Caruana and Niculescu-Mizil.
«On Calibration of Modern Neural Networks» (2017) by Guo et al.
«Obtaining Well Calibrated Probabilities Using Bayesian Binning» (2015) by Naeini et al.
编辑:于腾凯
校对:林亦霖
译者简介

欧阳锦,一名在埃因霍温理工大学就读的硕士生。喜欢数据科学和人工智能相关方向。欢迎不同观点和想法的交流与碰撞,对未知充满好奇,对热爱充满坚持。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”拥抱组织