Python的“predict_prob”方法不能真实反映预测概率校准
大数据文摘授权转载自数据派THU
作者: Samuele Mazzanti
翻译:欧阳锦
校对:王可汗
数据科学家通常根据准确性或准确性来评估其预测模型,但几乎不会问自己:
“我的模型能够预测实际概率吗?”
但是,从商业的角度来看,准确的概率估计是非常有价值的(准确的概率估计有时甚至比好的精度更有价值)。来看一个例子。
想象一下,你的公司正在出售2个杯子,一个是普通的白色杯子,而另一个则上面印有小猫的照片。你必须决定向这位给定的客户展示哪个杯子。为此,你需要预测给定的用户购买每个杯子的可能性。因此,你训练了几个不同的模型,你会得到以下结果:
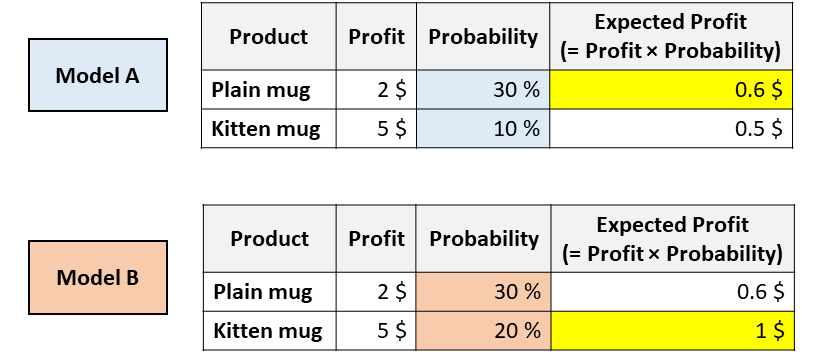
具有相同ROC(receiver operating characteristic)但校准不同的模型。[图源自作者]
现在,你会向该用户推荐哪个杯子?
以上两种模型都认为用户更有可能购买普通马克杯(因此,模型A和模型B在ROC曲线下具有相同的面积,因为这个指标仅仅对分类进行评估)。
但是,根据模型A,你可以通过推荐普通马克杯来最大化预期的利润,然而根据模型B,小猫马克杯可以最大化预期的利润。
在像这样的现实应用中,搞清楚哪种模型能够估算出更好的概率是至关重要的事情。
在本文中,我们将了解如何度量概率的校准(包括视觉和数字),以及如何“纠正”现有模型以获得更好的概率。
“predict_proba”的问题
Python中所有最流行的机器学习库都有一种称为“ predict_proba”的方法:Scikit-learn(例如LogisticRegression,SVC,RandomForest等),XGBoost,LightGBM,CatBoost,Keras…
但是,尽管它的名字是预测概率,“predict_proba”并不能完全预测概率。实际上,不同的研究(尤其是这个研究和这个研究)表明,最为常见的预测模型并没有进行校准。
数值在0与1之间不代表它就是概率!
但是,什么时候可以说一个数值实际上代表概率呢?
想象一下,你已经训练了一种预测模型来预测患者是否会患上癌症。如果对于给定的患者,模型预测的概率为5%。原则上,我们应该在多个平行宇宙中观察同一位患者,并查看其实际上患上癌症的频率是否为5%。
但是这种观察条件这是不可能发生的事,所以最好的替代方法是将所有概率在5%附近的患者都接受治疗,并计算其中有多少人真的患了癌症。如果观察到的患癌百分比实际上接近5%,则可以说该模型提供的概率是“已校准”的。
当预测的概率反映了真实情况的潜在概率时,这些预测概率被称为“已校准”。
那么,如何检查一个模型是否已校准?
校准曲线
评估一个模型校准的最简单的方法是通过一个称为“校准曲线”的图(也称为“可靠性图”,reliability diagram)。
这个方法主要是将观察到的结果通过概率划分为几类(bin)。因此,属于同一类的观测值具有相近的概率。在这一点上,对于每个类,校准曲线将预测这个类的平均值(即预测概率的平均值),然后将预测概率的平均值与理论平均值(即观察到的目标变量的平均值)进行比较。
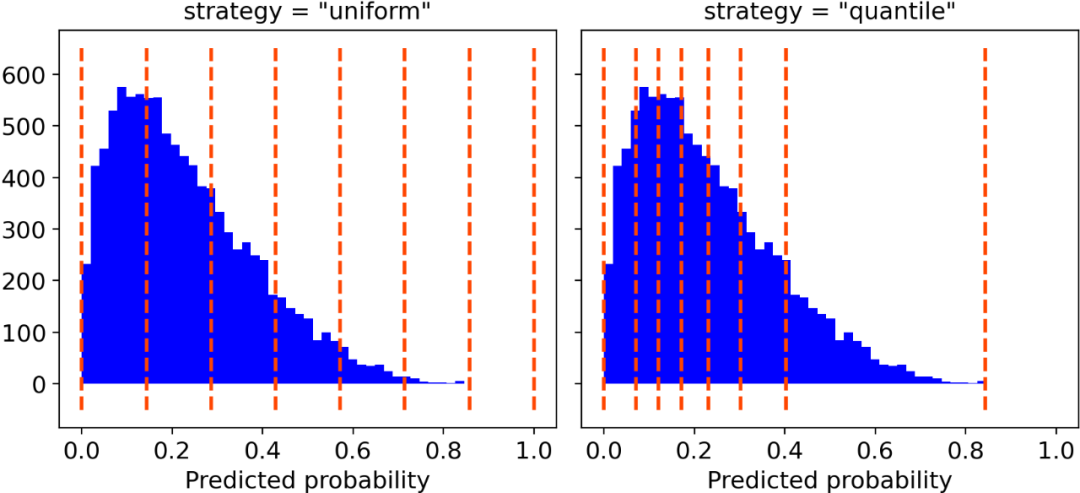
Scikit-learn通过“ calibration_curve”函数可以完成所有这些工作:

你只需要确定类的数量和以下两者之间的分类策略(可选)即可:
“uniform”,一个0-1的间隔被分为n_bins个类,它们都具有相同的宽度; “quantile”,类的边缘被定义,从而使得每个类都具有相同数量的观测值。

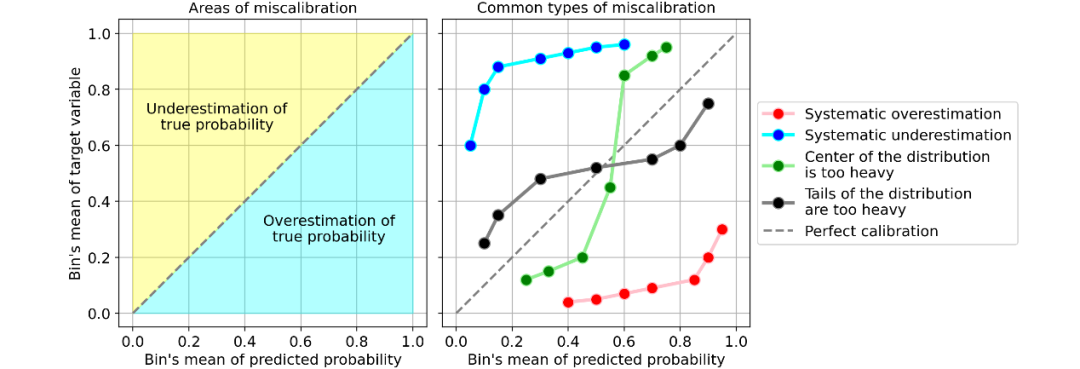
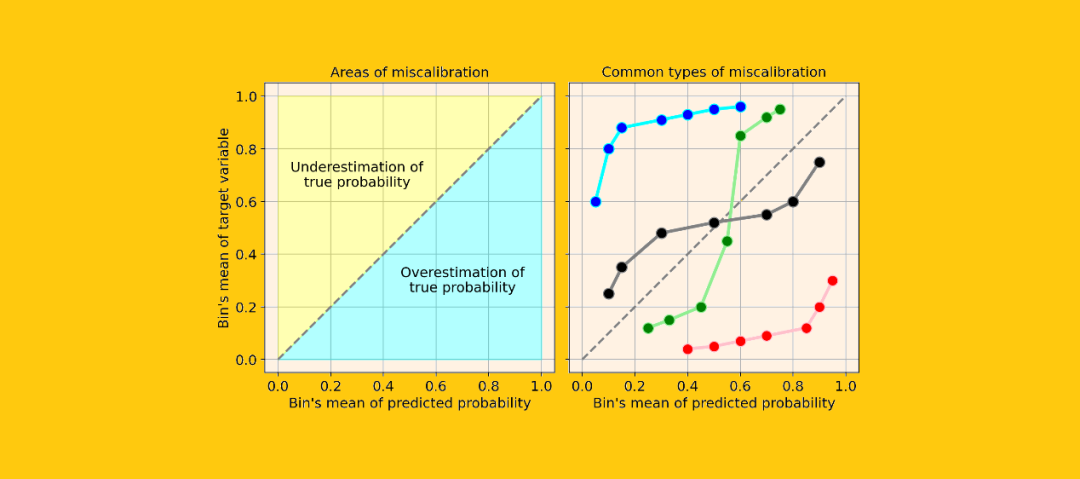
系统高估。与真实分布相比,预测概率的分布整体偏右。当您在正数极少的不平衡数据集上训练模型时,这种错误校准很常见。(如红线) 系统低估。与真实分布相比,预测概率的分布整体偏左。(如蓝线) 分布中心太重。当“支持向量机和提升树之类的算法趋向于将预测概率推离0和1”(引自《Predicting good probabilities with supervised learning》)时,就会发生这类错误校准。(如绿线) 分布的尾巴太重。例如,“其他方法(如朴素贝叶斯)具有相反的偏差(bias),并且倾向于将预测概率趋近于0和1”(引自《Predicting good probabilities with supervised learning》)。(如黑线)
如何解决校准错误(Python)
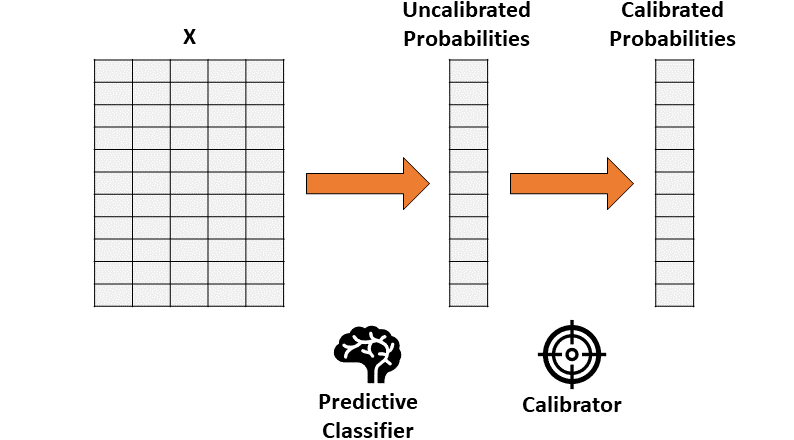
保序回归。一种非参数算法,这种非参数算法将非递减的自由格式行拟合到数据中。行不会减少这一事实是很重要的,因为它遵从原始排序。 逻辑回归。

保序回归

逻辑回归
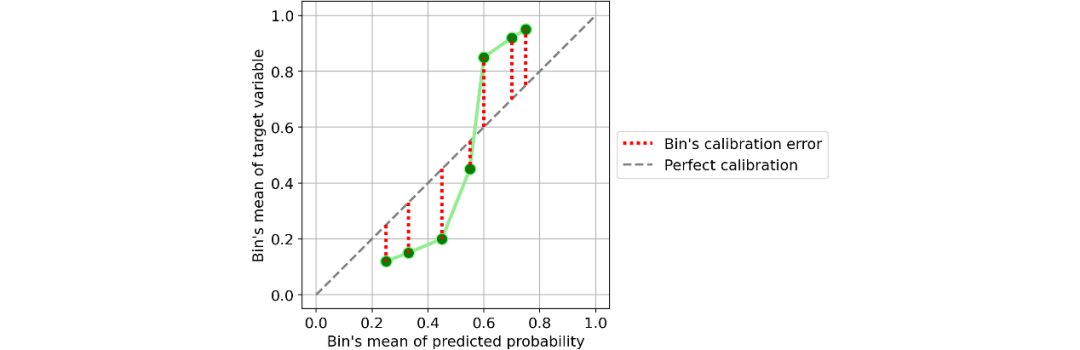
量化校准错误
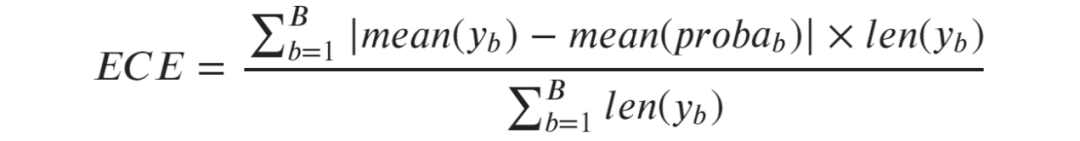


引用
«Predicting good probabilities with supervised learning» (2005) by Caruana and Niculescu-Mizil. «On Calibration of Modern Neural Networks» (2017) by Guo et al. «Obtaining Well Calibrated Probabilities Using Bayesian Binning» (2015) by Naeini et al.
https://towardsdatascience.com/pythons-predict-proba-doesn-t-actually-predict-probabilities-and-how-to-fix-it-f582c21d63fc