
DeiT III:打造ViT最强基准!还是ViT最牛!
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
继Three things everyone should know about Vision Transformers这个工作后,meta AI团队(原DeiT作者团队)又发布了DeiT III: Revenge of the ViT,DeiT III通过改进训练策略将ViT模型在ImageNet上的有监督训练性能提升到新的基准,其中的改进包括简化数据增强和采用FixRes(即先在较低的图像分辨率下训练,然后在目标分辨率下进行微调)。相比其它的训练方案,改进后的DeiT III性能有较大的提升,而且在大模型如ViT-H上表现优异。在类似的配置下,DeiT III性能可以媲美最近的一些模型如Swin和ConvNext,而且DeiT III性能也达到了近期的基于图像掩码的自监督学习方法如BeiT和MAE的水准。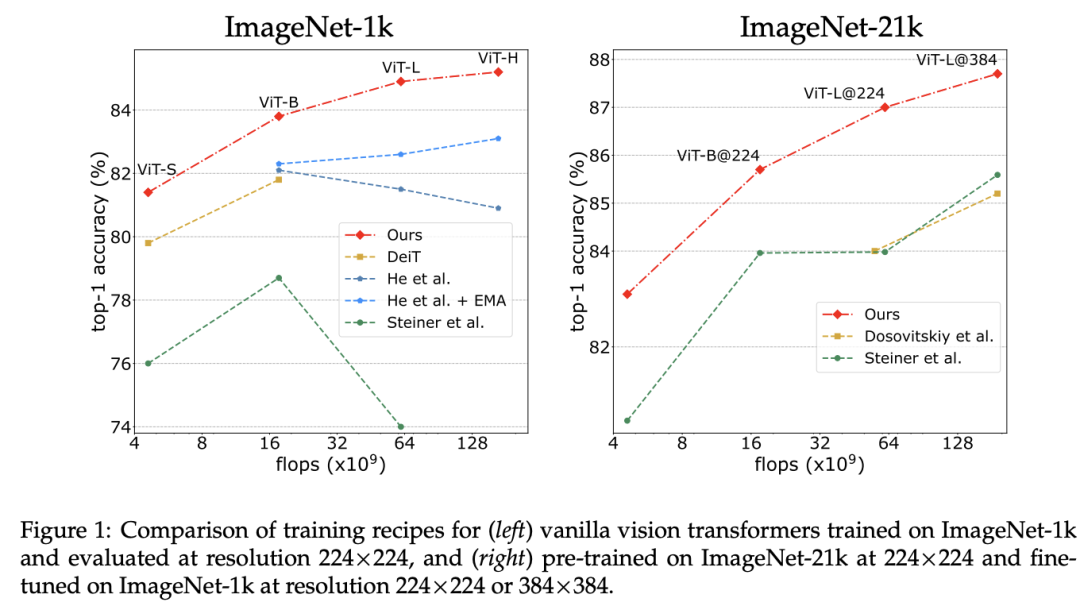
训练策略
DeiT III采用的训练策略如下表所示,它是构建在timm库的ResNet最新训练策略和DeiT的训练策略之上,这里ImageNet-1K和ImageNet-21K数据集上的训练策略有所区别,其中ImageNet-1K上的训练时长默认为400 epochs,而ImageNet-21K预训练时长为90 epochs,然后在mageNet-1K上微调50 epochs。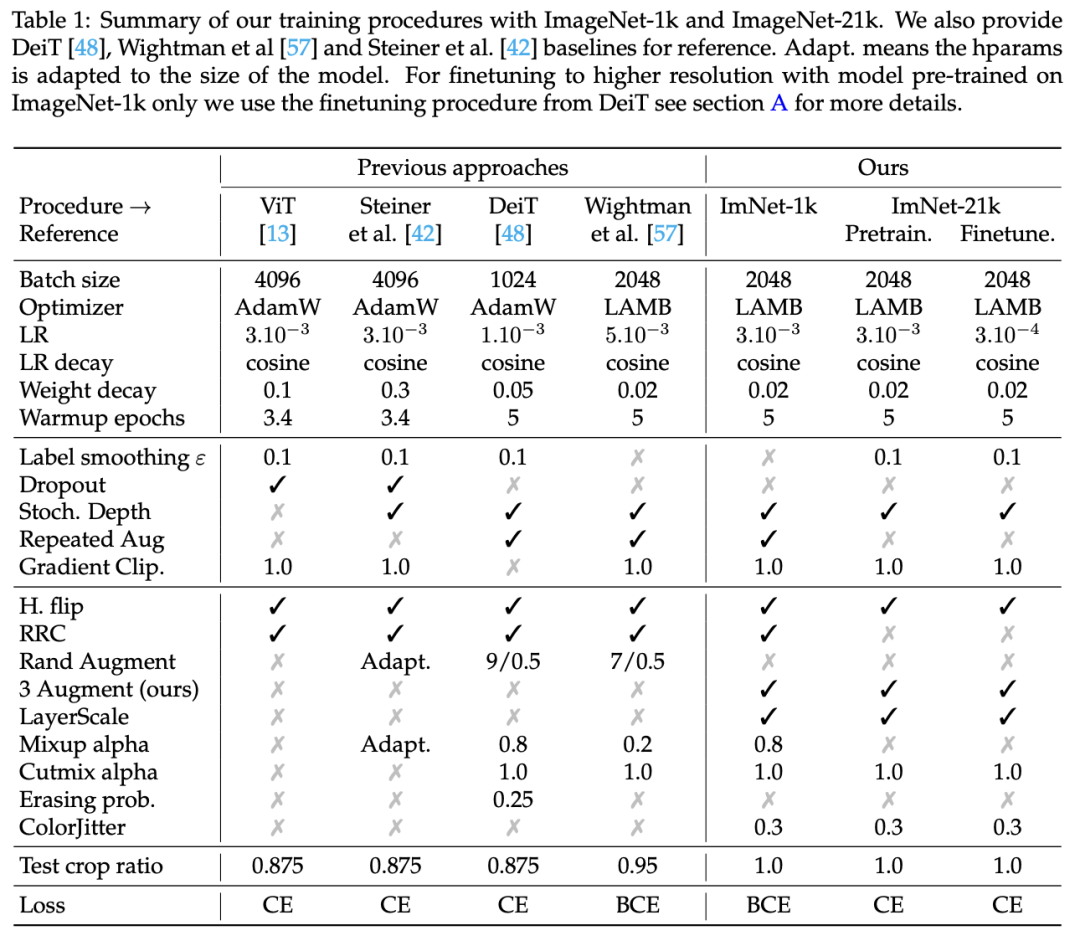 相比之前的训练策略,DeiT III采用的训练策略主要有以下几点主要的改动。(1)采用LayerScale
相比之前的训练策略,DeiT III采用的训练策略主要有以下几点主要的改动。(1)采用LayerScale
LayerScale有助于提升深度ViT模型的收敛,这里发现采用LayerScale可以带来模型准确度的提升,这方面也可以见之间的文章:?关于ViT,你必须要知道的三点改进。
(2)采用BCE损失
图像分类模型默认都采用CE损失,但timm的训练策略采用BCE损失,这主要是因为采用MixUp和CutMix数据增强后图像会产生语义歧义,采用非互斥的BCE损失更合适。论文发现采用BCE虽然对小模型ViT-S影响不大,但是能给ViT-B带来较大的性能提升(300 epochs):80.9 vs 82.2。但是实验发现BCE在ImageNet-21K上预训练并没有效果,所以还是采用CE损失(包括后面的微调)。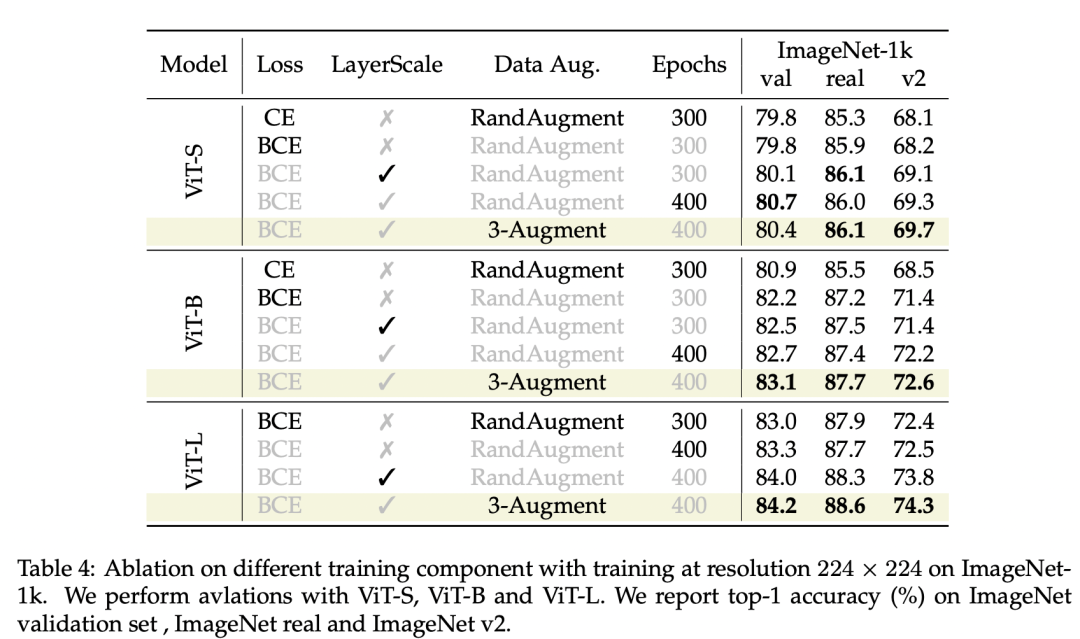 (3)用3-Augment替换RandAugment
(3)用3-Augment替换RandAugment
这里采用一个简单的数据增强策略来替换RandAugment(包含14个数据增强),它包括3个简单的数据增强:Grayscale(灰度化),Gaussian Blur(高斯模糊)和Solarization(过曝),称为3-Augment,效果图如下所示: 对于每个图像,以相同的概率随机选择3个数据增强的某一个进行增强,此外,还额外采用了ColorJitter(亮度,对比度,饱和度和色调变换)。相比RandAugment,采用3-Augment可以带来性能的提升,如下表所示:
对于每个图像,以相同的概率随机选择3个数据增强的某一个进行增强,此外,还额外采用了ColorJitter(亮度,对比度,饱和度和色调变换)。相比RandAugment,采用3-Augment可以带来性能的提升,如下表所示: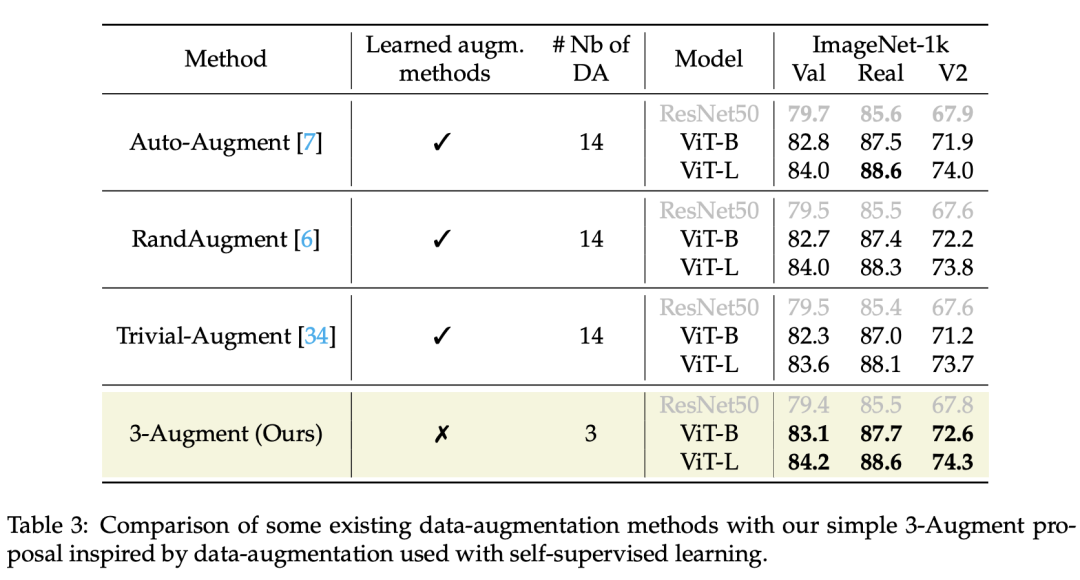 (4)简化图像裁剪(RRC vs SRC)
(4)简化图像裁剪(RRC vs SRC)
Random Resized Crop (RRC)是最常用的图像裁剪方法:首先根据设定的scale和ratio范围随机选择某个scale和ratio,然后从原图裁剪一块区域,并resize到固定大小如224。RRC在torchvision中的对应函数为:RandomResizedCrop(224, scale=(0.08, 1.0), ratio=(3/4, 4/3)),scale的默认下限为0.08,即只从原图中裁剪一块较小的区域(这个造成了训练和测试的不一致,FixRes可以缓解这个问题),所以这是一种非常heavy的数据增强,有可能原图中的标注物体并没有被裁剪到。作者认为对于ImageNet-1K数据集,RRC作为一种较强的数据增强可以防止过拟合,但是对于更大的数据集ImageNet-21K(比ImageNet-1K大10倍),存在较小的过拟合风险,所以这里提出了一种更简单的图像裁剪方法:Simple Random Crop (SRC)**,SRC的操作相对简单:首先将图像的最短边resize到目标大小,然后各个位置补零4个像素(reflect padding),最后按照目标大小从图像中随机裁剪一个区域。相比RRC,SRC会覆盖原图的大部分区域,对比如下所示:
 在ImageNet-21K预训练实验中,采用SRC训练的模型效果要优于RRC:
在ImageNet-21K预训练实验中,采用SRC训练的模型效果要优于RRC: (5)更长的训练时长
(5)更长的训练时长
DeiT训练300 epochs,而这里默认训练400 epochs,作者发现进一步增加训练时长,模型依然能够持续提升,而没有出现饱和的迹象,对比之下,原来的DeiT训练策略却出现饱和现象。训练800 epochs可以带来不小的性能提升,如下所示: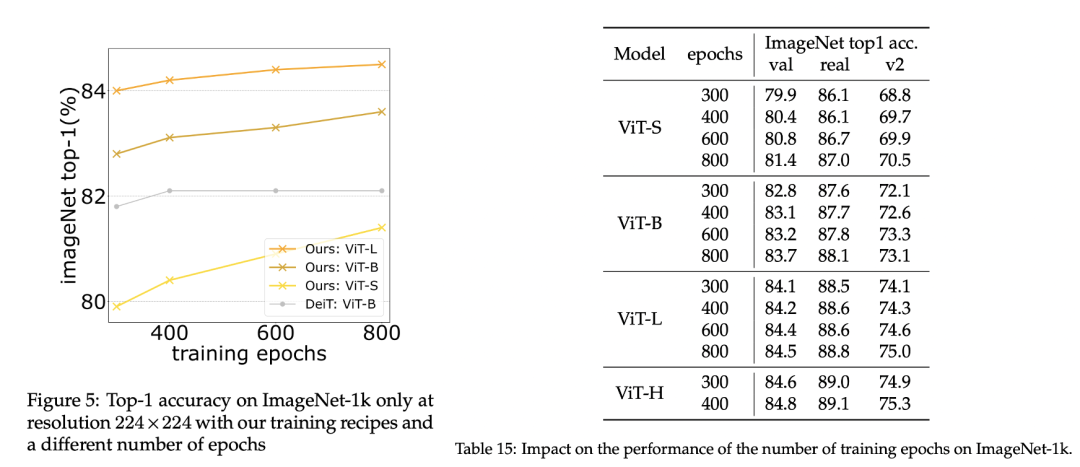 (6)采用FixRes
(6)采用FixRes
FixRes策略是先在一个较小的分辨率下训练,然后在目标分辨率下进行微调。作者发现先在192x192或者160x160大小下训练,然后在224x224大小下微调20个epochs,能得到更好的效果(与直接在224x224下训练),而且这可以减少显存消耗,提升训练速度,对比结果如下所示: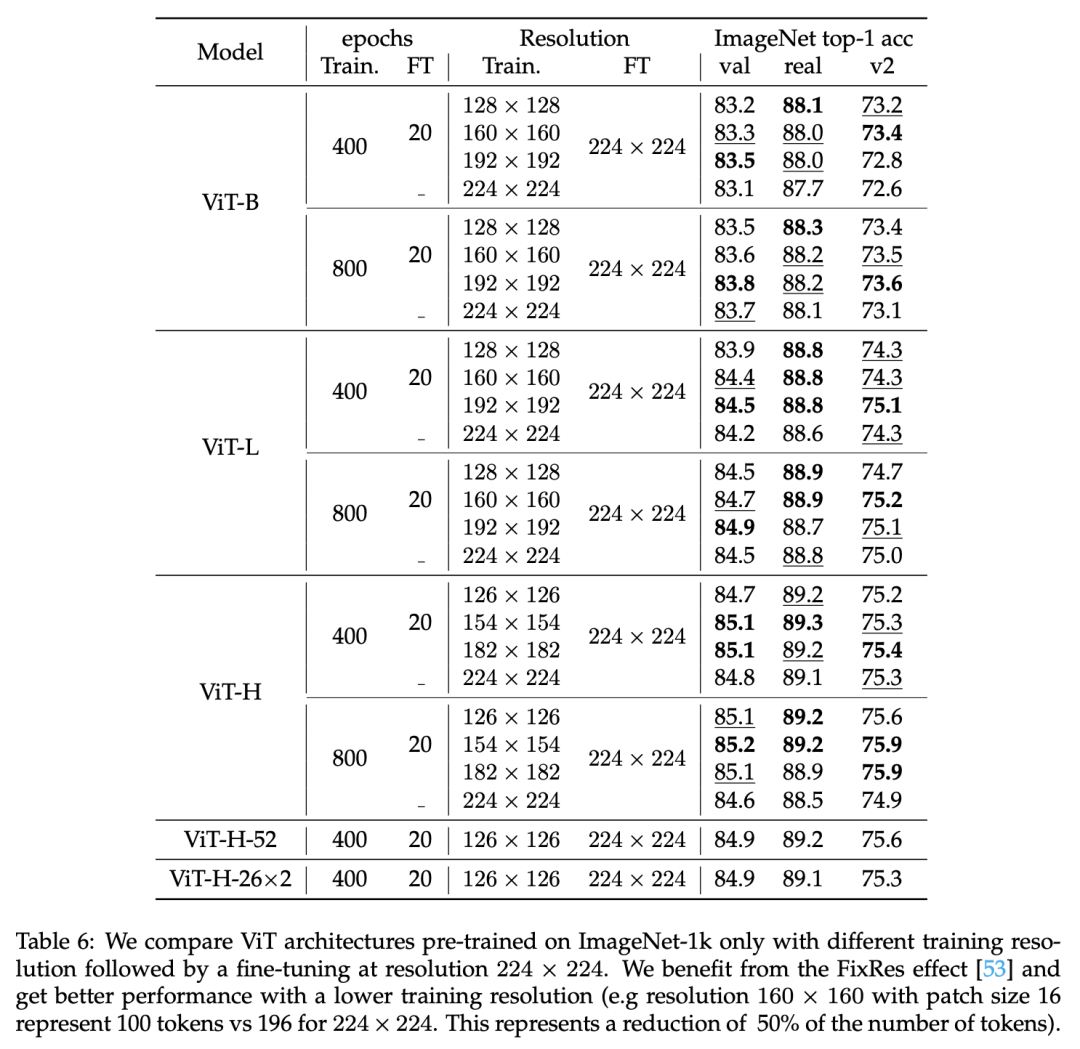 作者发现FixRes对大模型可以起到一种正则化作用,减少在长时间训练过程的过拟合,比如ViT-H直接在224x224下训练,800 epochs下的效果比400 epochs下还要差,但是采用FixRes后就可以消除这种gap。由于FixRes降低了显存使用,这也使训练更大的模型称为了可能,这里训练了52层的ViT-H,其参数量达到了10亿,不过效果并没有太大提升,应该还需要在更大规模的数据集上预训练。
作者发现FixRes对大模型可以起到一种正则化作用,减少在长时间训练过程的过拟合,比如ViT-H直接在224x224下训练,800 epochs下的效果比400 epochs下还要差,但是采用FixRes后就可以消除这种gap。由于FixRes降低了显存使用,这也使训练更大的模型称为了可能,这里训练了52层的ViT-H,其参数量达到了10亿,不过效果并没有太大提升,应该还需要在更大规模的数据集上预训练。
对比实验
对比实验主要包括四个部分:与其它架构的对比,与自监督学习方法的对比,迁移学习对比,以及在下游分割任务上的对比。
(1)与其它架构的对比
首先是ImageNet-1K数据集上,与其它主流架构的对比,如下表所示,可以看到同样的参数下的模型,ViT可以和Swin和ConvNext效果相当,比如ViT-B模型性能为83.8,而同量级下的Swin-B和ConvNext-B分别为83.5和83.8,不过它们都是在300 epochs下训练的,而ViT训练了800+20 epochs。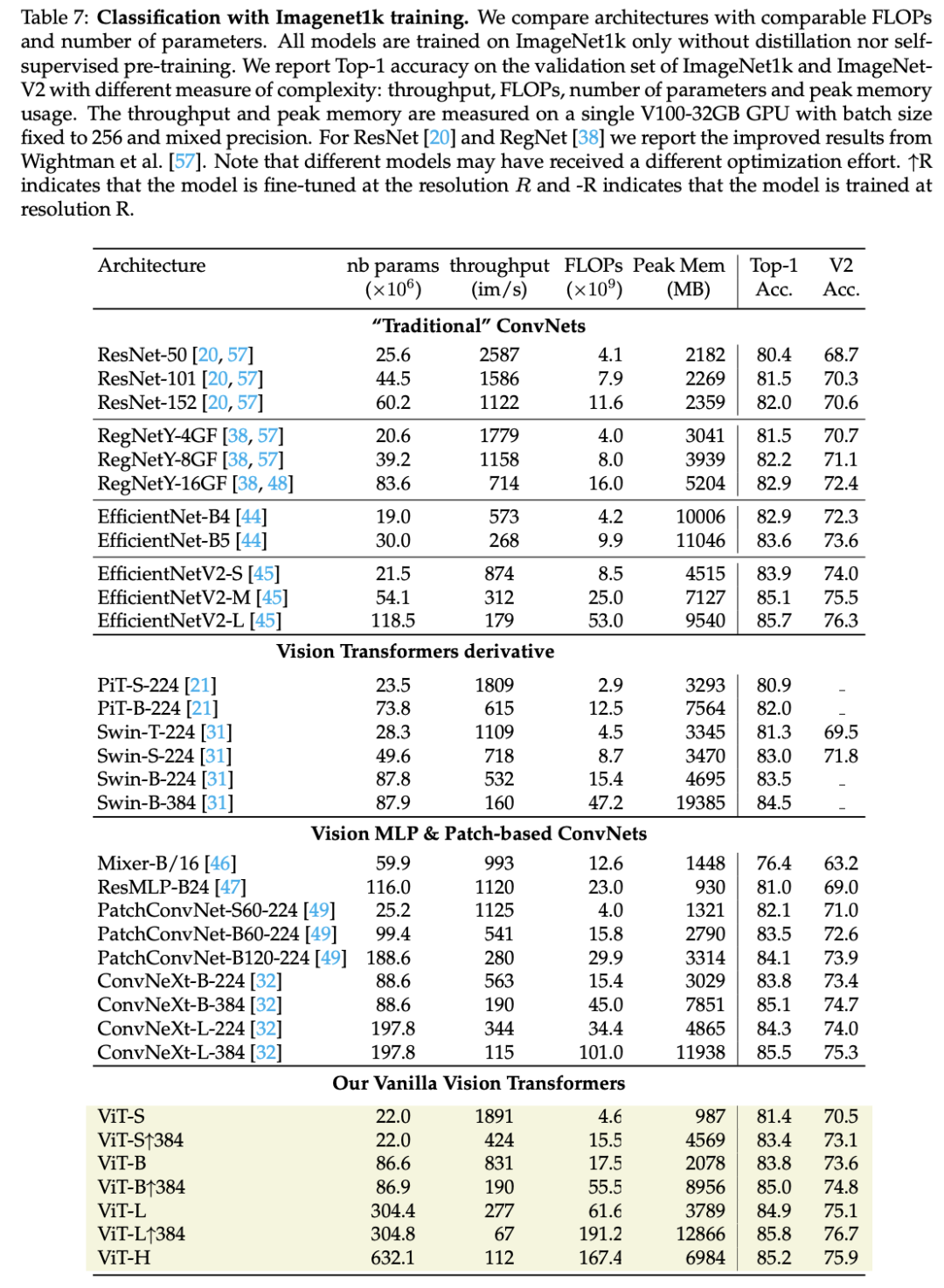 如果在ImageNet-21K上预训练,可以得到类似的结论:
如果在ImageNet-21K上预训练,可以得到类似的结论: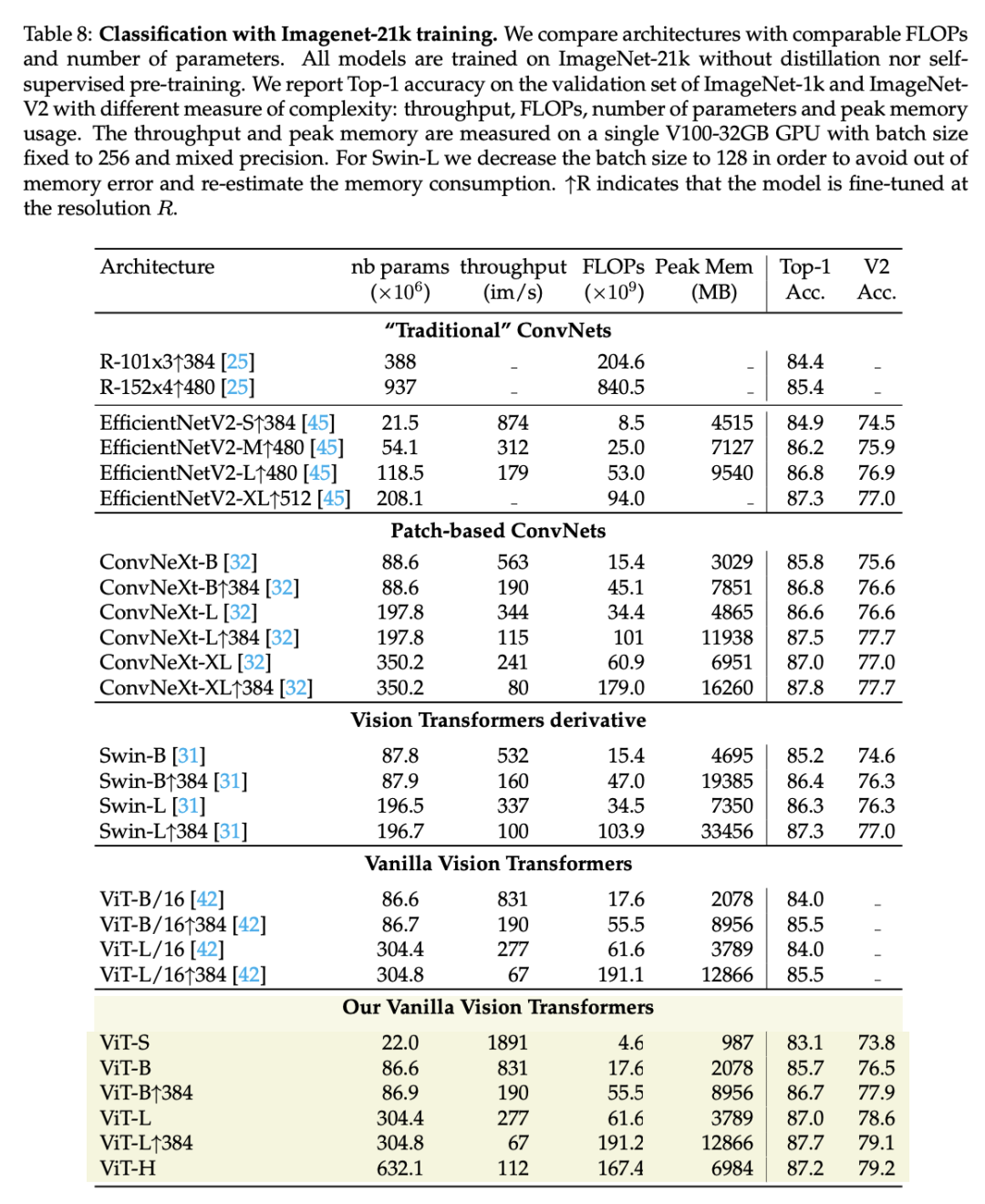 另外,这里还对比了在ImageNetV2上的效果,它可以衡量模型的泛化能力,相比其它模型,ViT在ImageNetV2上的效果更好,特别是采用ImageNet-21K数据预训练后。
另外,这里还对比了在ImageNetV2上的效果,它可以衡量模型的泛化能力,相比其它模型,ViT在ImageNetV2上的效果更好,特别是采用ImageNet-21K数据预训练后。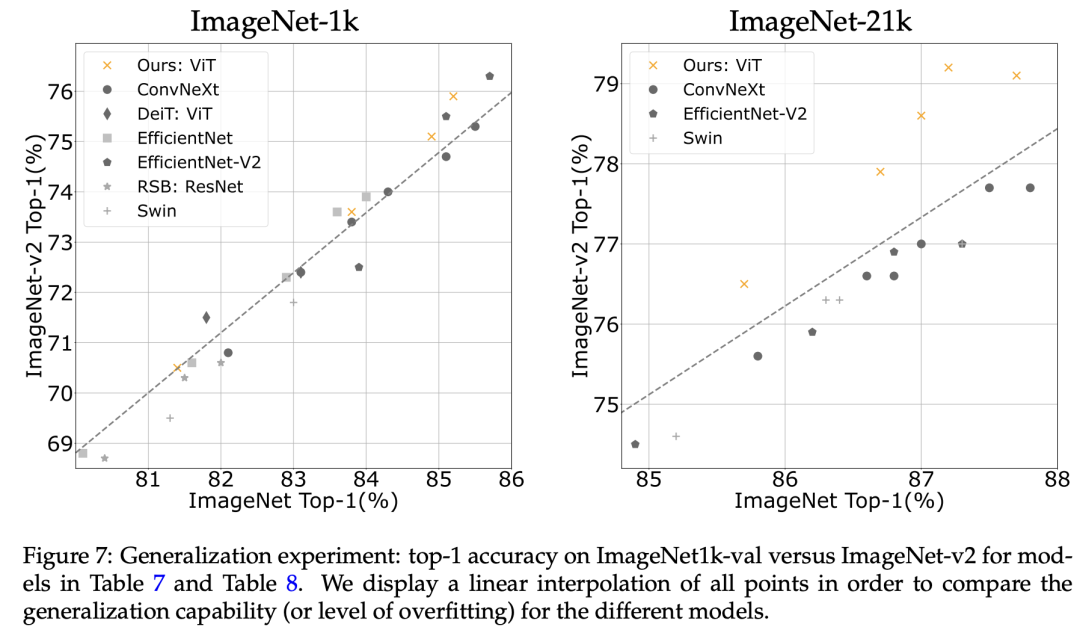 (2)与自监督模型的对比
(2)与自监督模型的对比
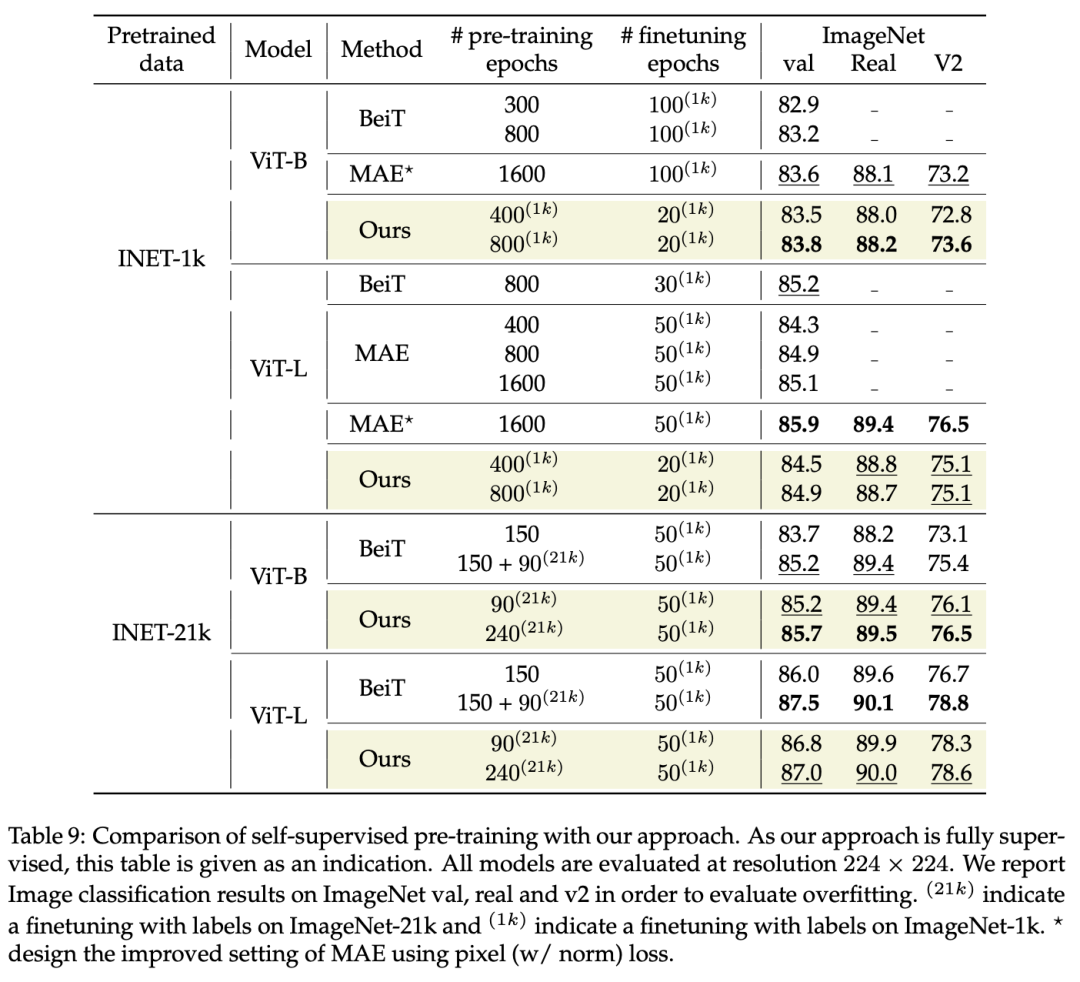
作者还和基于图像掩码的自监督学习方法BeiT和MAE做了对比,如下表所示,在类似的训练时长下,有监督的ViT可以和自监督学习方法达到类似的效果,这说明有监督方法在合适的训练策略下是能够达到自监督方法的效果的。不过这里没有对比其它自监督学习方法,如ViT-B采用?PeCo训练可以达到84.5,这还是有一定的性能差距。
 (3)迁移学习对比
(3)迁移学习对比
这里对比了6个不同的分类数据集,可以看到新的ViT也具有更好的迁移学习效果: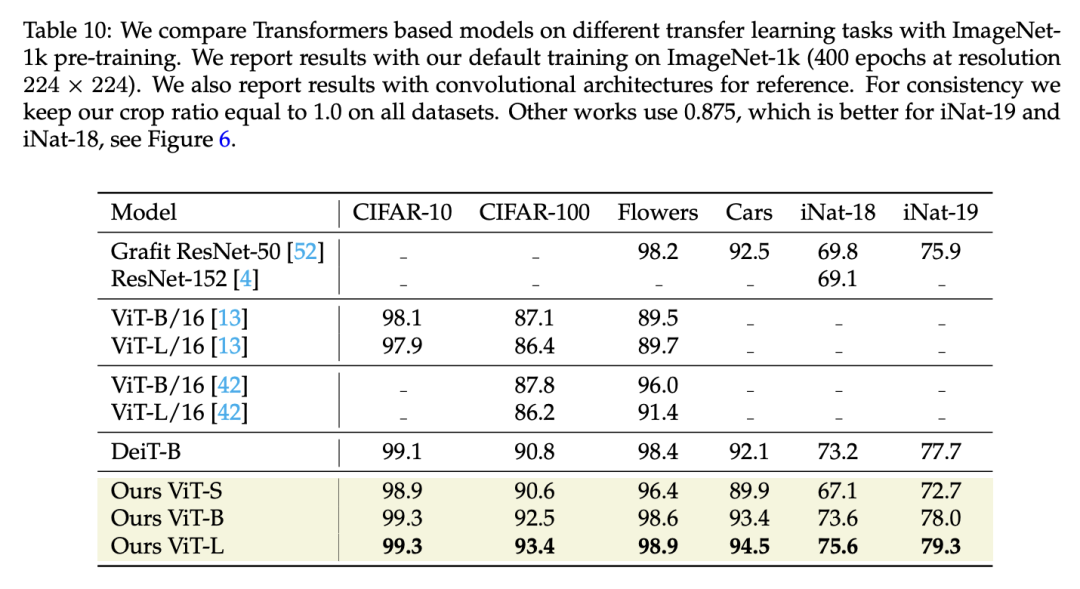 (4)语义分割对比
(4)语义分割对比
最后作者对比了采用ViT做为骨干网络在语义分割任务上的效果,可以看到新的ViT可以超过Swin,另外有监督的ViT-B也可以超过自监督MAE训练的ViT-B。这里一个额外的疑问是,论文?Benchmarking Detection Transfer Learning with Vision Transformers指出基于MAE的ViT做为检测模型的骨干网络要比有监督的ViT要好,如果换成更好的有监督模型,是否能够也推翻这个结论?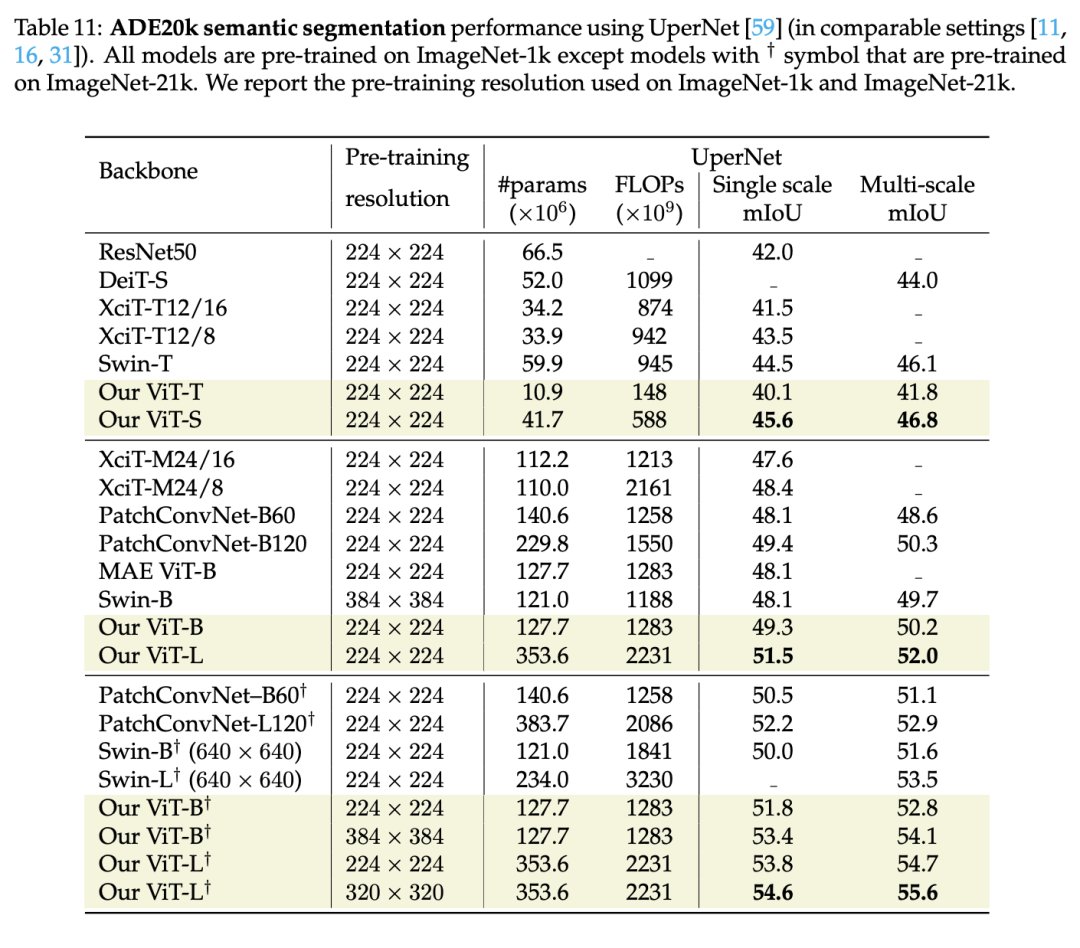 此外,作者还尝试将这种训练策略用在其它模型上,但是从结果来看,大部分的模型训练效果并不太好,这或许也说明不同的架构确实需要特定的训练策略才能得到最佳的效果。
此外,作者还尝试将这种训练策略用在其它模型上,但是从结果来看,大部分的模型训练效果并不太好,这或许也说明不同的架构确实需要特定的训练策略才能得到最佳的效果。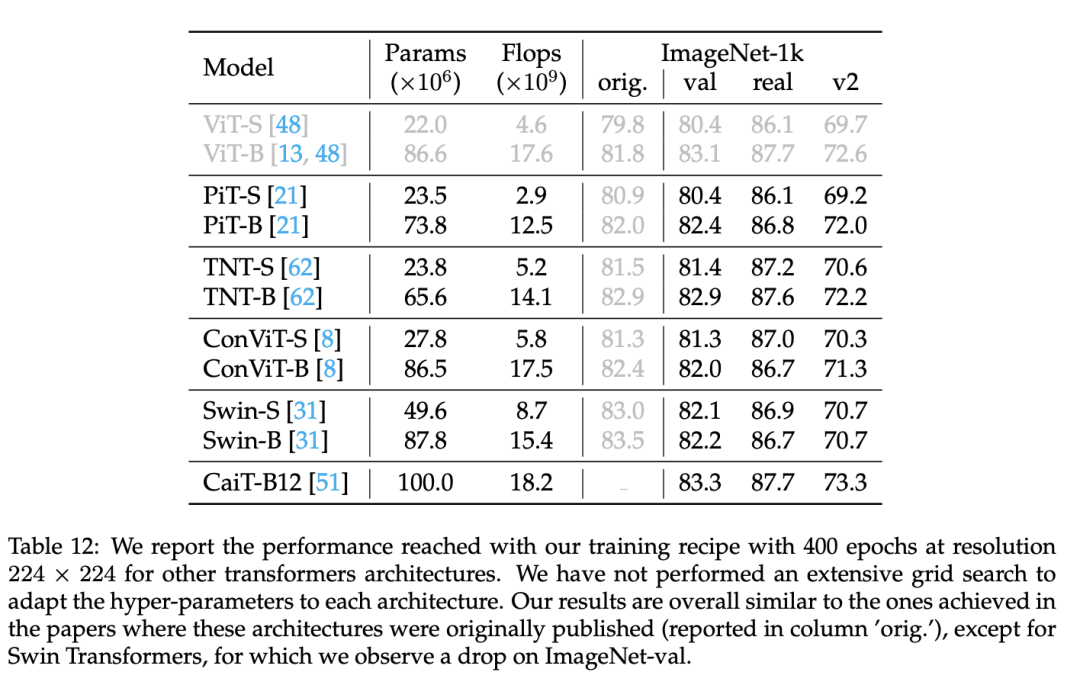
小结
从直观上看,这个工作就是一个调参报告,但是我觉得这个工作还是有很大的意义:一方面它将ViT的效果提升到了和其它架构类似的水平,这说明简单的ViT架构其实是足够的;另外一方面它将ViT的有监督训练效果和自监督方法拉到了同样的层次,这也让我们要重新审视自监督方法。
参考
?DeiT III: Revenge of the ViT ?Three things everyone should know about Vision Transformers ?An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale ?Training data-efficient image transformers & distillation through attention
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
