
视觉Transformer的复仇!Meta AI提出DeiT III:ViT训练的全新baseline
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
转载自:机器之心
作者:Adam Zewe | 编辑:赵阳、张倩
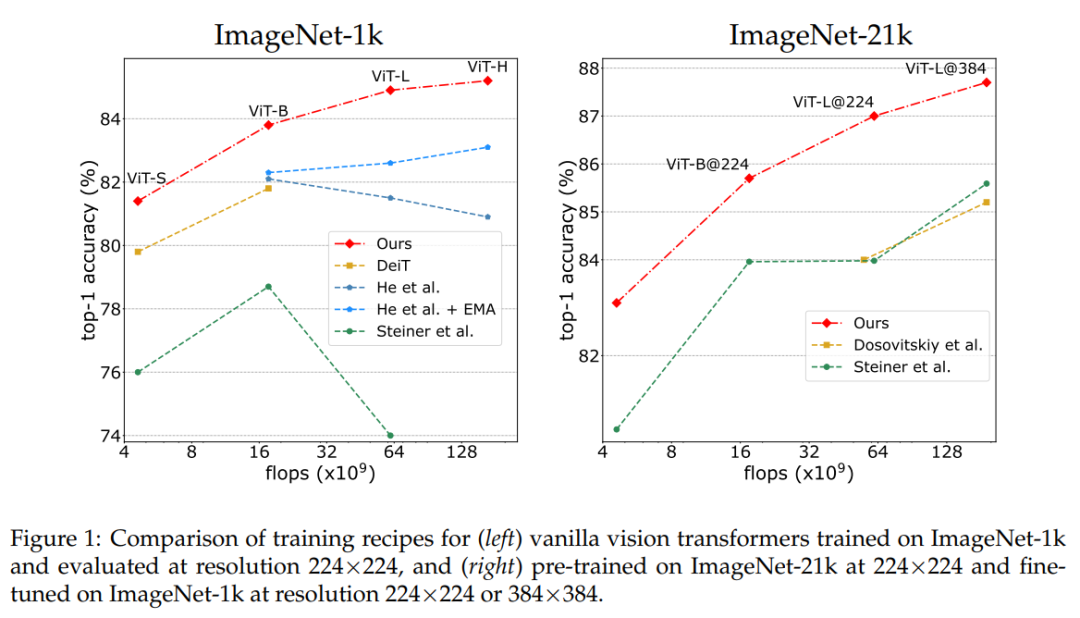
本文提出了训练视觉 Transformer(ViT)的三种数据增强方法:灰度、过度曝光、高斯模糊,以及一种简单的随机剪枝方法 (SRC)。实验结果表明,这些新方法在效果上大大优于 ViT 此前的全监督训练方法。
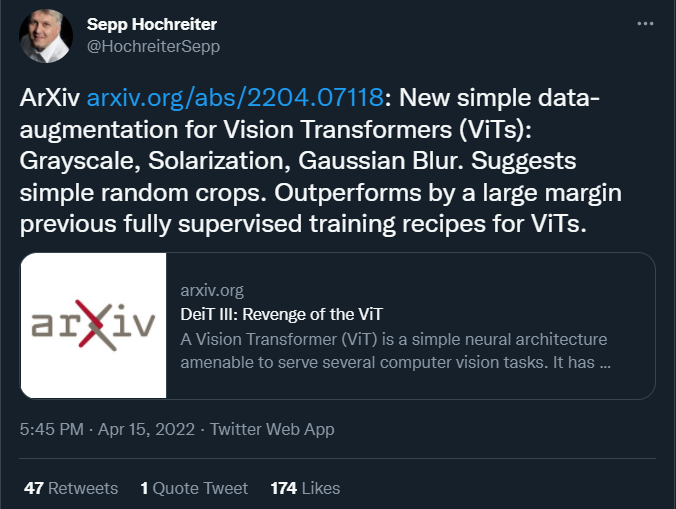

作者以 Wightman 等人的工作 [57] 为基础,同样使用 ResNet50 。特别之处在于,仅对 Imagenet1k 的训练过程采用二元交叉熵损失,这一步可以通过引入一些显著改善大型 ViT [51] 训练的方法,即 stochastic depth [24] 和 LayerScale [51],来实现。
3-Augment:这是一种简单的数据增强方式,灵感来自于自监督学习。令人惊讶的是,在使用 ViT 时,作者观察到这种方法比用于训练 ViT 的常用自动 / 学习数据增强(如 RandAugment [6])效果更好。
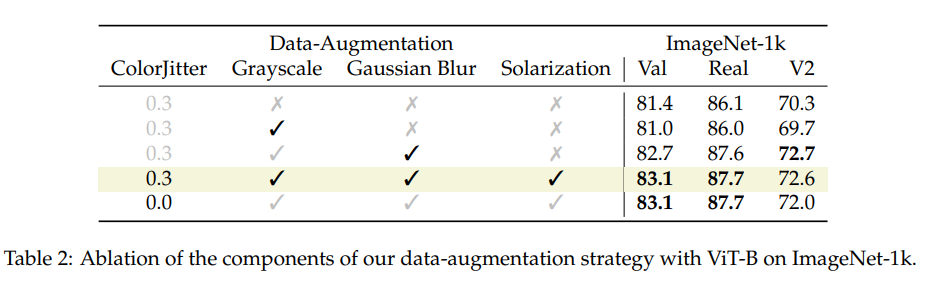
在像 ImageNet-21k 这样的更大数据集上进行预训练时,简单随机裁剪的方式比调整大小后再随机裁剪的方式更有效。
训练时降低分辨率。这种选择减少了训练和测试过程的差异 [53],而且还没有被 ViT 使用。作者观察到这样做还能通过防止过拟合,来使得对最大的模型产生正则化效果。例如,目标分辨率是 224 × 224 ,在分辨率 126 × 126(81 个 token)下预训练的 ViT-H 在 ImageNet-1k 上的性能比在分辨率 224 × 224(256 个 token)下预训练时更好。并且在预训练时的要求也较低,因为 token 数量减少了 70%。从这个角度来看,这样做提供了与掩码自编码器 [19] 类似的缩放属性。
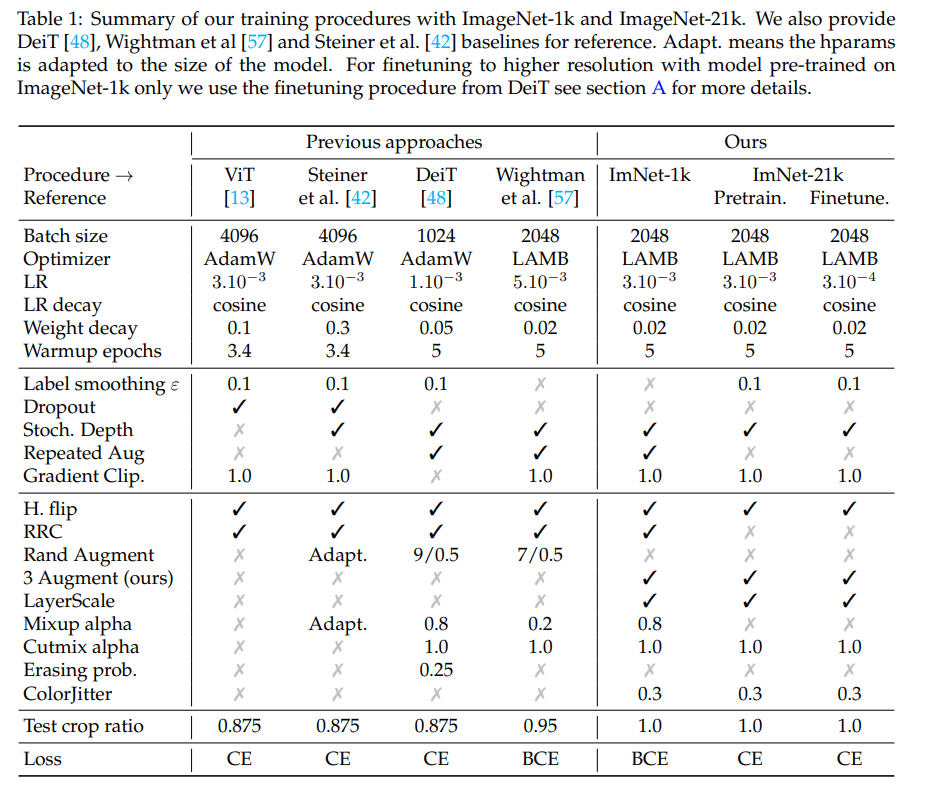
灰度:有利于颜色不变性并更加关注形状。
过度曝光:会在颜色上添加强烈的噪点,以更加适应颜色强度的变化,从而更加关注形状。
高斯模糊:为了稍微改变图像中的细节。




点个在看 paper不断!
评论