本文来源 机器之心 编辑:蛋酱
如何衡量一个视觉模型?又如何选择适合自己需求的视觉模型?MBZUAI和Meta的研究者给出了答案。
一直以来,ImageNet 准确率是评估模型性能的主要指标,也是它最初点燃了深度学习革命的火种。但对于今天的计算视觉领域来说,这一指标正变得越来越不「够用」。 因为计算机视觉模型已变得越来越复杂,从早期的 ConvNets 到 Vision Transformers,可用模型的种类已大幅增加。同样,训练范式也从 ImageNet 上的监督训练发展到自监督学习和像 CLIP 这样的图像 - 文本对训练。 ImageNet 并不能捕捉到不同架构、训练范式和数据所产生的细微差别。如果仅根据 ImageNet 准确率来判断,具有不同属性的模型可能看起来很相似。当模型开始过度拟合 ImageNet 的特异性并使准确率达到饱和时,这种局限性就会变得更加明显。 CLIP 就是个值得一提的例子:尽管 CLIP 的 ImageNet 准确率与 ResNet 相似,但其视觉编码器的稳健性和可迁移性要好得多。这引发了对 CLIP 独特优势的探索和研究,如果当时仅从 ImageNet 指标来看,这些优势并不明显。这表明,分析其他属性有助于发现有用的模型。 此外,传统的基准并不能完全反映模型处理真实世界视觉挑战的能力,例如不同的相机姿势、光照条件或遮挡物。例如,在 ImageNet 等数据集上训练的模型往往很难将其性能应用到现实世界的应用中,因为现实世界的条件和场景更加多样化。 这些问题,为领域内的从业者带来了新的困惑:如何衡量一个视觉模型?又如何选择适合自己需求的视觉模型? 在最近的一篇论文中,MBZUAI 和 Meta 的研究者对这一问题开展了深入讨论。

-
论文标题:ConvNet vs Transformer, Supervised vs CLIP:Beyond ImageNet Accuracy
-
论文链接:https://arxiv.org/pdf/2311.09215.pdf
论文聚焦 ImageNet 准确性之外的模型行为,分析了计算机视觉领域的四个主要模型:分别在监督和 CLIP 训练范式下的 ConvNeXt(作为 ConvNet 的代表)和 Vision Transformer (ViT) 。 所选模型的参数数量相似,且在每种训练范式下对 ImageNet-1K 的准确率几乎相同,确保了比较的公平性。研究者深入探讨了一系列模型特性,如预测误差类型、泛化能力、习得表征的不变性、校准等,重点关注了模型在没有额外训练或微调的情况下表现出的特性,为希望直接使用预训练模型的从业人员提供了参考。
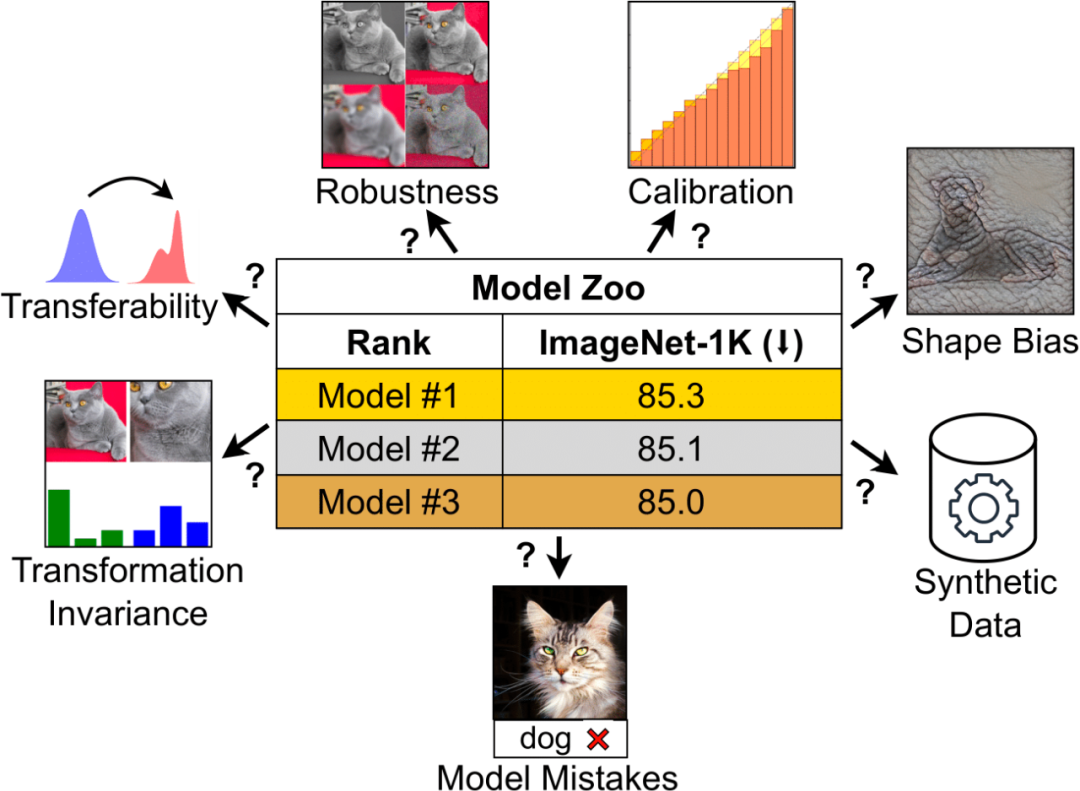
在分析中,研究者发现不同架构和训练范式的模型行为存在很大差异。例如,模型在 CLIP 范式下训练的分类错误少于在 ImageNet 上训练。不过,监督模型的校准效果更好,在 ImageNet 稳健性基准测试中普遍更胜一筹。ConvNeXt 在合成数据上有优势,但比 ViT 更偏重纹理。同时,有监督的 ConvNeXt 在许多基准测试中表现出色,其可迁移性表现与 CLIP 模型相当。 可以看出,各种模型以独特的方式展现了自己的优势,而这些优势是单一指标无法捕捉到的。研究者强调,需要更详细的评估指标来准确选择特定情境下的模型,并创建与 ImageNet 无关的新基准。 基于这些观察,Meta AI 首席科学家 Yann LeCun 转发了这项研究并点赞:

模型选择 对于监督模型,研究者使用了 ViT 的预训练 DeiT3- Base/16,它与 ViT-Base/16 架构相同,但训练方法有所改进;此外还使用了 ConvNeXt-Base。对于 CLIP 模型,研究者使用了 OpenCLIP 中 ViT-Base/16 和 ConvNeXt-Base 的视觉编码器。 请注意,这些模型的性能与最初的 OpenAI 模型略有不同。所有模型检查点都可以在 GitHub 项目主页中找到。详细的模型比较见表 1:

对于模型的选择过程,研究者做出了详细解释:
1、由于研究者使用的是预训练模型,因此无法控制训练期间所见数据样本的数量和质量。
2、为了分析 ConvNets 和 Transformers,之前的许多研究都对 ResNet 和 ViT 进行了比较。这种比较通常对 ConvNet 不利,因为 ViT 通常采用更先进的配方进行训练,能达到更高的 ImageNet 准确率。ViT 还有一些架构设计元素,例如 LayerNorm,这些元素在多年前 ResNet 被发明时并没有纳入其中。因此,为了进行更平衡的评估,研究者将 ViT 与 ConvNeXt 进行了比较,后者是 ConvNet 的现代代表,其性能与 Transformers 相当,并共享了许多设计。
3、在训练模式方面,研究者对比了监督模式和 CLIP 模式。监督模型在计算机视觉领域一直保持着最先进的性能。另一方面,CLIP 模型在泛化和可迁移性方面表现出色,并提供了连接视觉和语言表征的特性。
4、由于自监督模型在初步测试中表现出与监督模型类似的行为,因此未被纳入结果中。这可能是由于它们最终在 ImageNet-1K 上进行了有监督的微调,而这会影响到许多特性的研究。
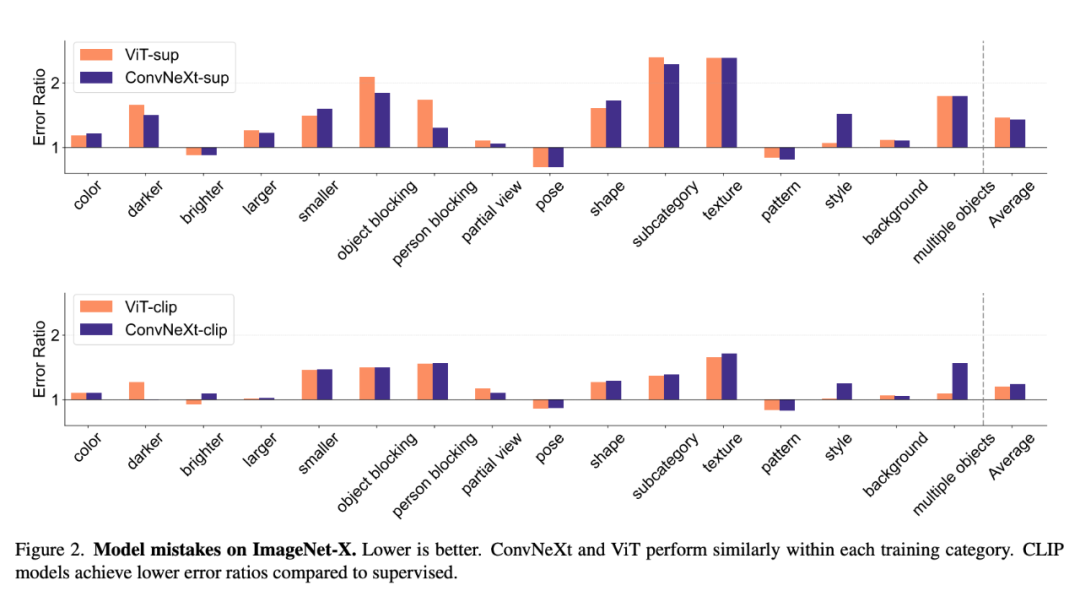
接下来,我们看下研究者如何对不同的属性进行了分析。 分析 模型错误 ImageNet-X 是一个对 ImageNet-1K 进行扩展的数据集,其中包含对 16 个变化因素的详细人工注释,可对图像分类中的模型错误进行深入分析。它采用错误比例度量(越低越好)来量化模型在特定因素上相对于整体准确性的表现,从而对模型错误进行细致入微的分析。ImageNet-X 的结果表明:
1. 相对于监督模型,CLIP 模型在 ImageNet 准确性方面犯的错误更少。
2. 所有模型都主要受到遮挡等复杂因素的影响。
3. 纹理是所有模型中最具挑战性的因素。
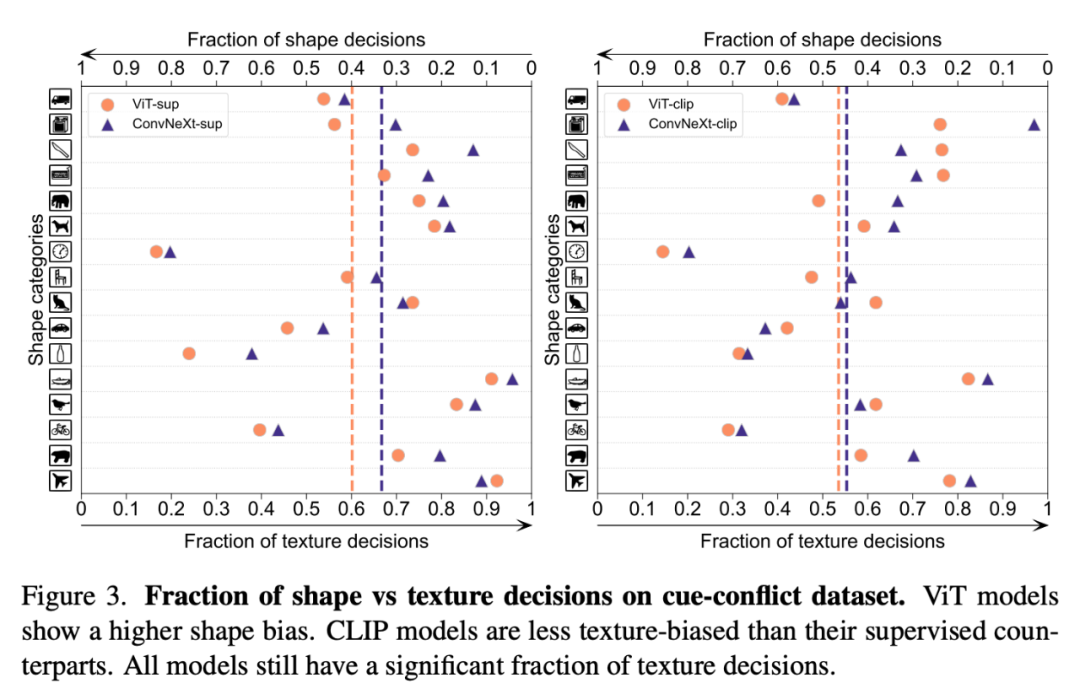
形状 / 纹理偏差
形状 - 纹理偏差会检测模型是否依赖于脆弱的纹理捷径,而不是高级形状线索。这种偏差可以通过结合不同类别的形状和纹理的线索冲突图像来研究。这种方法有助于了解,与纹理相比,模型的决策在多大程度上是基于形状的。研究者对线索冲突数据集上的形状 - 纹理偏差进行了评估,发现 CLIP 模型的纹理偏差小于监督模型,而 ViT 模型的形状偏差高于 ConvNets。
模型校准 校准可量化模型的预测置信度与其实际准确度是否一致,可以通过预期校准误差 (ECE) 等指标以及可靠性图和置信度直方图等可视化工具进行评估。研究者在 ImageNet-1K 和 ImageNet-R 上对校准进行了评估,将预测分为 15 个等级。在实验中,研究者观察到以下几点:
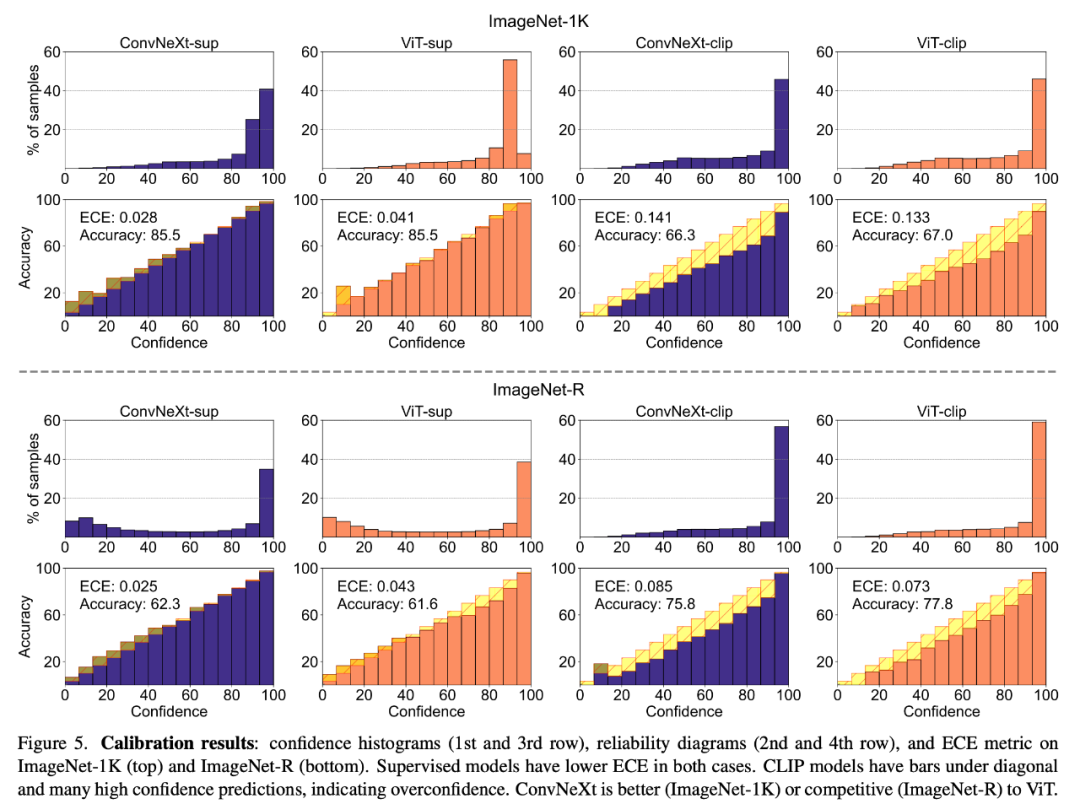
1. CLIP 模型过于自信,而监督模型则略显不足。
2. 有监督的 ConvNeXt 比有监督的 ViT 校准效果更好。
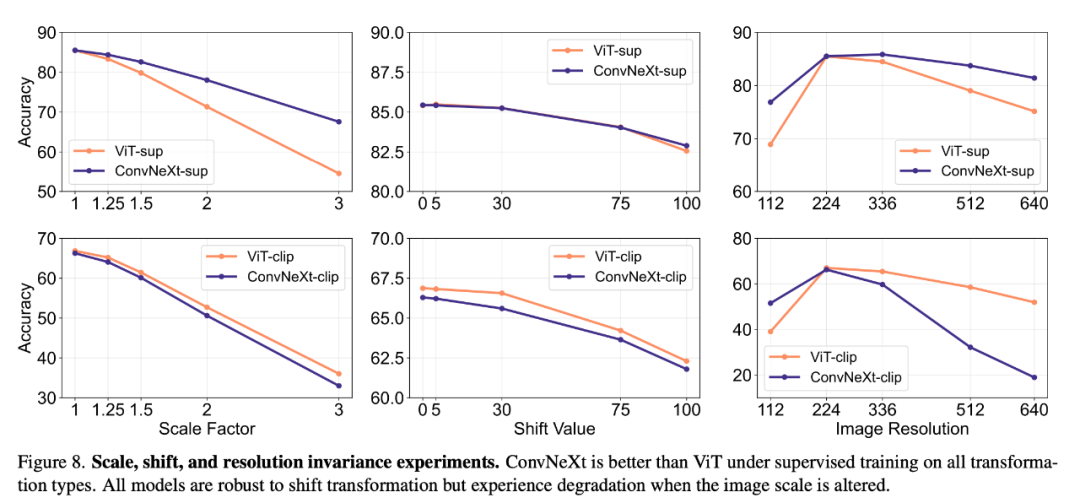
稳健性和可迁移性 模型的稳健性和可迁移性对于适应数据分布变化和新任务至关重要。研究者使用各种 ImageNet 变体对稳健性进行了评估,结果发现,虽然 ViT 和 ConvNeXt 模型的平均性能相当,但除 ImageNet-R 和 ImageNet-Sketch 外,有监督模型在稳健性方面普遍优于 CLIP。在可迁移性方面,通过使用 19 个数据集的 VTAB 基准进行评估,有监督的 ConvNeXt 优于 ViT,几乎与 CLIP 模型的性能相当。
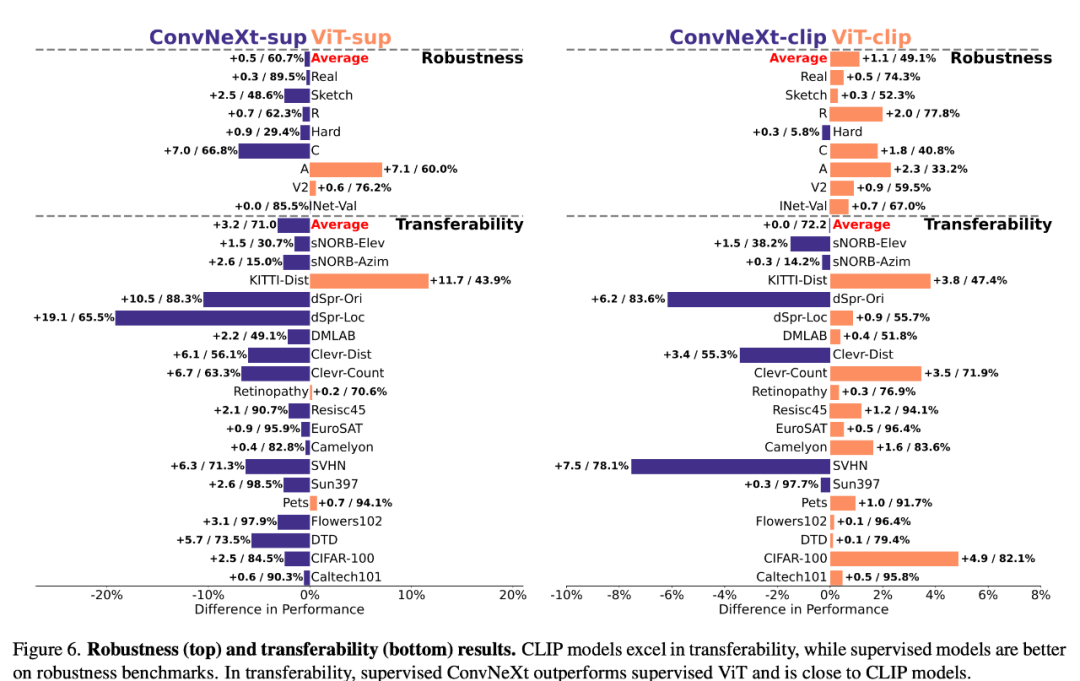
合成数据 PUG-ImageNet 等合成数据集可以精确控制摄像机角度和纹理等因素,是一种很有前景的研究路径,因此研究者分析了模型在合成数据上的性能。PUG-ImageNet 包含逼真的 ImageNet 图像,姿态和光照等因素存在系统性变化,性能以绝对 top-1 准确率为衡量标准。研究者提供了 PUG-ImageNet 中不同因素的结果,发现 ConvNeXt 在几乎所有因素上都优于 ViT。这表明 ConvNeXt 在合成数据上优于 ViT,而 CLIP 模型的差距较小,因为 CLIP 模型的准确率低于监督模型,这可能与原始 ImageNet 的准确率较低有关。
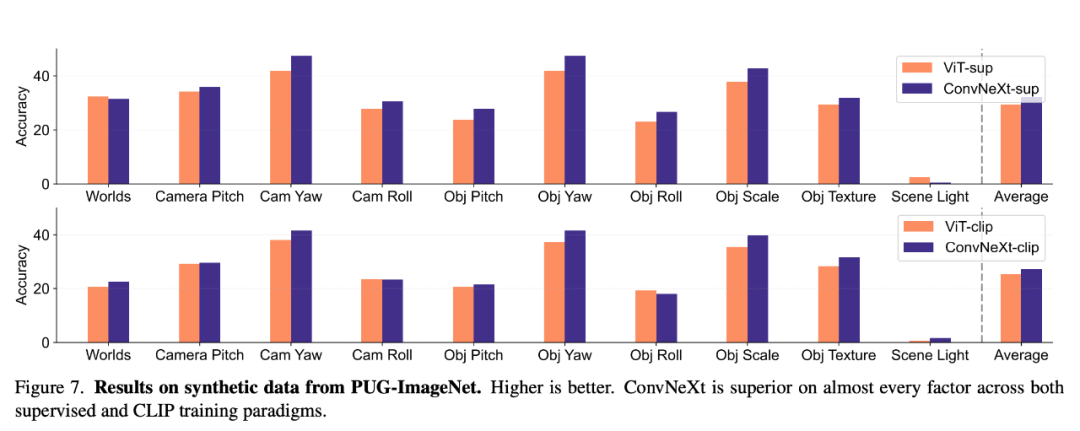
变换不变性 变换不变性是指模型能够产生一致的表征,不受输入变换的影响从而保留语义,如缩放或移动。这一特性使模型能够在不同但语义相似的输入中很好地泛化。研究者使用的方法包括调整图像大小以实现比例不变性,移动 crops 以实现位置不变性,以及使用插值位置嵌入调整 ViT 模型的分辨率。 他们在 ImageNet-1K 上通过改变 crop 比例 / 位置和图像分辨率来评估比例、移动和分辨率的不变性。在有监督的训练中,ConvNeXt 的表现优于 ViT。总体而言,模型对规模 / 分辨率变换的稳健性高于对移动的稳健性。对于需要对缩放、位移和分辨率具有较高稳健性的应用,结果表明有监督的 ConvNeXt 可能是最佳选择。
总结 总体来说,每种模型都有自己独特的优势。这表明模型的选择应取决于目标用例,因为标准性能指标可能会忽略特定任务的关键细微差别。此外,许多现有的基准都来自于 ImageNet,这也会使评估产生偏差。开发具有不同数据分布的新基准对于在更具现实世界代表性的环境中评估模型至关重要。 以下是本文结论的概括: ConvNet 与 Transformer
1. 在许多基准上,有监督 ConvNeXt 的性能都优于有监督 ViT:它的校准效果更好,对数据转换的不变性更高,并表现出更好的可迁移性和稳健性。
2. ConvNeXt 在合成数据上的表现优于 ViT。
3. ViT 的形状偏差更大。
监督与 CLIP 1. 尽管 CLIP 模型在可转移性方面更胜一筹,但有监督的 ConvNeXt 在这项任务中表现出了竞争力。这展示了有监督模型的潜力。 2. 有监督模型在稳健性基准方面表现更好,这可能是因为这些模型都是 ImageNet 变体。 3. CLIP 模型的形状偏差更大,与 ImageNet 的准确性相比,分类错误更少。
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
不是一杯奶茶喝不起,而是我T M直接用来跟进 AIGC+CV视觉 前沿技术,它不香?!
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
经典GAN不得不读:StyleGAN
 戳我,查看GAN的系列专辑~! 最新最全100篇汇总!生成扩散模型Diffusion Models ECCV2022 | 生成对抗网络GAN部分论文汇总
戳我,查看GAN的系列专辑~! 最新最全100篇汇总!生成扩散模型Diffusion Models ECCV2022 | 生成对抗网络GAN部分论文汇总
CVPR 2022 | 25+方向、最新50篇GAN论文
ICCV 2021 | 35个主题GAN论文汇总
超110篇!CVPR 2021最全GAN论文梳理
超100篇!CVPR 2020最全GAN论文梳理
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击 跟进 AIGC+CV视觉 前沿技术,真香! ,加入 AI生成创作与计算机视觉 知识星球!
