
NBNet:抛开复杂的网络结构设计,旷世&快手提出子空间注意力模块用于图像降噪
点击下方“AI算法与图像处理”,关注一下
重磅干货,第一时间送达
导读
本文对旷视科技2021年关于图像去噪的新作"NBNet进行解读,该工作抛开复杂的网络结构设计和精确的图像噪声建模,创新性的提出子空间基向量生成和投影操作。前沿

论文地址:https://arxiv.org/abs/2012.15028
开源代码:https://github.com/megvii-research/NBNet
NBNet创新简述
本文从图像自适应投影这一新视角出发,提出一种新的图像去噪网络------NBNet,通过在特征空间中学习一系列重建基底使网络能分离信号和噪声。选择信号子空间相应的基底并将输入信号投影到信号子空间中,以实现图像去噪。核心是希望投影能保持输入信号的局部结构,尤其是低亮度和弱纹理的区域。为此,作者提出子空间注意力SSA,一个non-local注意力模块来显式地学习基底生成和子空间投影,最终设计一个UNet结构的网络完成端到端的图像去噪。大量实验表明提出的NBNet在PSNR和SSIM指标上都取得了最好的性能。
NBNet提出动机
图像去噪是图像处理和计算机视觉领域的基本任务,一个典型的加性噪声模型可用下式表示:y=x+n,想要恢复出干净的图像x其实是一个病态问题。传统方法是利用图像先验和噪声模型估计图像或是噪声,例如NLM和BM3D利用图像局部相似性和噪声独立性,小波去噪方法利用图像在变换域上的稀疏性。近年来,基于深度学习的去噪方法隐式地利用图像先验或从大规模的成对数据集中学习噪声分布。尽管基于深度学习的方法取得了很大成功,但在弱纹理或高频细节这样的困难场景下,恢复高质量图像仍然是一项挑战。因为卷积网络通常利用局部滤波器分离噪声和信号,但在低信噪比下,如果没有全局结构信息局部响应就会很容易失败。
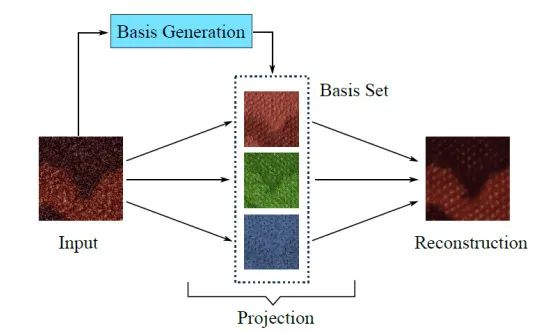
为解决上述问题,通过投影来利用非局部图像信息从而设计图像去噪网络。如上图是图像投影和基底示意图,从输入图像生成一系列的图像基底向量,然后从这些基底向量构成的子空间重建出去噪图像。因为自然图像通常处于低秩的信号空间,因此通过准确地学习和生成这些基底向量,重建图像能最大程度保留原始信息并抑制噪声。
NBNet的具体结构
NBNet整体是UNet形式的网络,其中关键的是子空间注意力模块SSA,其学习子空间基底向量,如图1是NBNet的整体结构。NBNet的创新在于子空间投影,包括两个主要的步骤:基底向量生成和投影。
1 、基底向量生成,从输入图像特征图谱生成子空间基底向量。基底生成函数用 表示, 以编码阶段的中间特征图谱为输入, 则生成的基底矩阵为 。基底生成函数用 可以一个残差卷积 block 实现,输出通道数为 , 然后将输出变形为 。下图中(b) 为残差卷积 block;(c) 为子空间注意力模块 SSA,其中 basis vectors 即 为生成的基底向量。
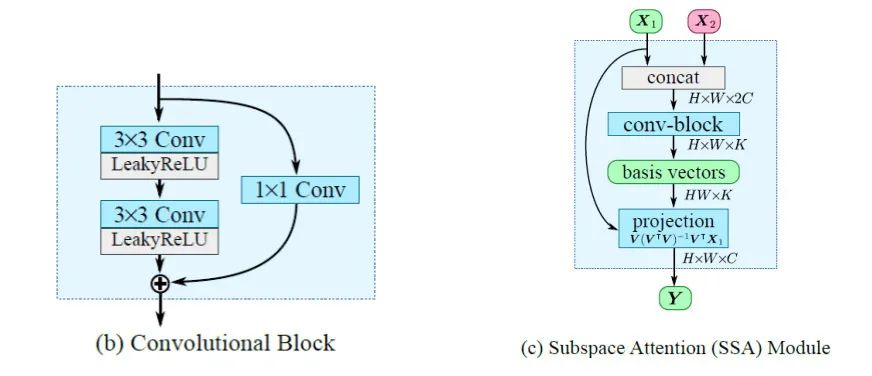
2、投影,如上图中(c)的 projection, 通过正交线性投影将图像特征 投影到子空间 中。用 表示信号子空间的正交投影矩阵,则 可由 计算得到,如下式:
其中标准化项 是必要的,因为基底生成过程不能保证基向量间是相互正交的。最终 图像特征 在信号子空间重建为 , 即 。投影运算其实仅包含线性矩阵运算,经过 适当的变形,投影运算是完全可微,在现代神经网络框架中易于实现。
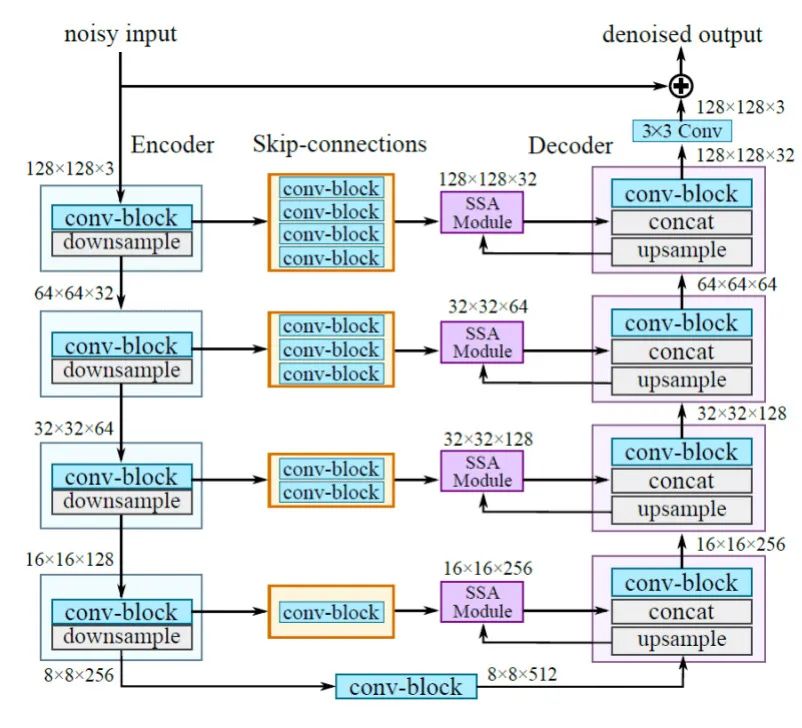
图 1 NBNet网络整体结构
3、NBNet具体实现和损失函数。NBNet整体结构是典型的UNet形式,如上图1,包括4个编码阶段和4个相应的解码阶段。下采样使用k4s2的卷积操作,上采样使用反卷积。每个卷积层激活函数都使用LeakyReLU。
提出的SSA模块放置在跳转连接中。因为大尺寸低层特征图谱包含更多原始图像的细节信息,因此以编码阶段低层特征图谱为,解码阶段高层特征图谱为。即利用上采样的高层特征指导来自跳转连接的低层特征投影到信号子空间中。经投影变换后的特征与原始高层特征concat,再进行解码。与传统UNet形式结构相比,NBNet中的低层特征在与高层特征融合前先由SSA模块进行投影变换。最后一个解码器的输出通过一个线性3×3卷积层输出全局残差(针对有噪声的输入而言),再加上输入后得到最终的去噪结果。
以L1距离为网络训练的损失函数:
实验部分
在合成数据和真实数据集上进行了大量实验以验证NBNet的有效性和先进性。其中子空间K=16。
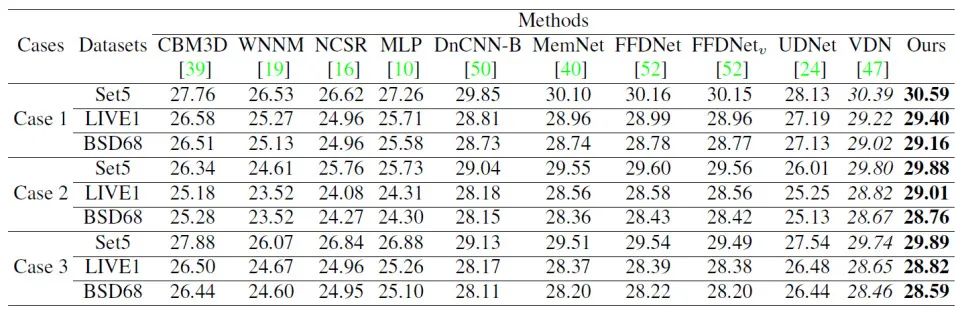
1、合成的高斯噪声。测试集有Set5、LIVE1和BSD68。本文方法取得了最好PSNR值。
2、SIDD Benchmark
SIDD可以用作测试智能手机摄像头的去噪性能基准,因此用SIDD验证NBNet对真实图像的去噪性能。下表和图展示了性能指标和计算量,本文方法NBNet在PSNR和SSIM两个指标上都比MIRNet有所提高,同时计算量和参数量大幅度降低。
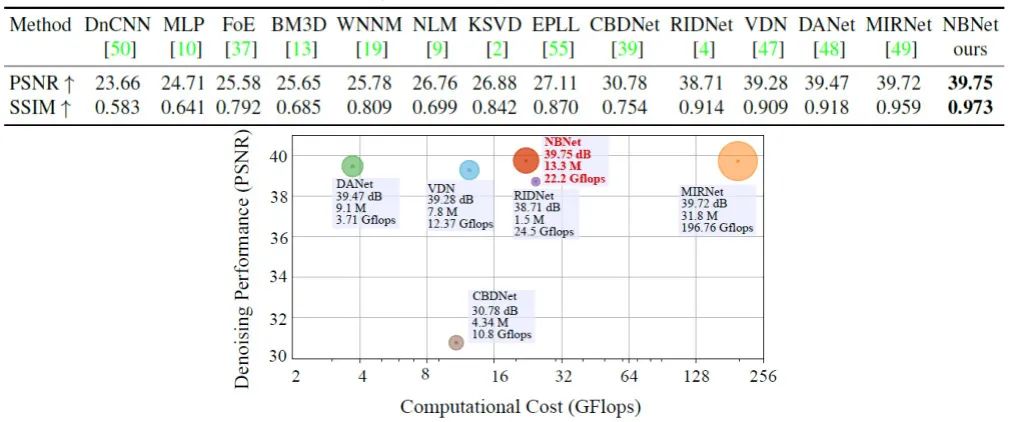
下图是在SIDD Benchmark上的去噪实例。本文方法在点、线等弱纹理区域去噪更好。

3、DND Benchmark
DND Benchmark并没有提供任何训练数据,因此组合SIDD和Renoir数据集训练网络。提交在SIDD Benchmark验证数据上最好的模型到DND Benchmark。下表展示了性能指标,本文方法NBNet在PSNR指标上比MIRNet有所提高,但计算量和参数量大幅度降低。

下图是在DND Benchmark上的去噪实例。本文方法更好地保持了纹理和锐度。

4、消融实验
(1)为了验证SSA模块有效性,又选择DnCNN为基线模型。嵌入SSA模块后比DnCNN提供了0.55dB。
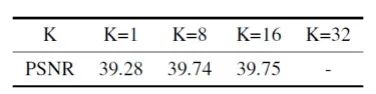
(2)研究子空间K不同取值的影响,下表是在SIDD上的实验结果。当K=32是网络不能收敛,因为第一个编码阶段的通道数是32,导致SSA模型不能有效的进行子空间投影。K=1是会造成信息的显著丢失。K=8和16时性能很接近,说明子空间维数K在合理的范围内是一个鲁棒的超参数。
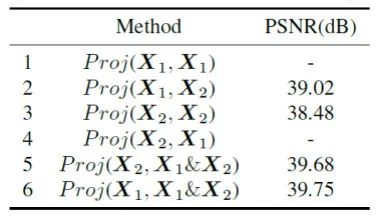
(3)研究投影过程中不同输入的影响,下表是实验结果。对比第 1 、 2 行,仅使用 生成基向量不能使网络收玫。对比第 3、4行,仅使用 生成基向量得到的性能不好。当使用 和 生成基向量,并对 进行投影时得到的性能最好,即最后一行
结论
本文以子空间投影的视角重新思考了图像去噪问题。抛开复杂的网络结构设计和精确的图像噪声建模,创新性的提出子空间基向量生成和投影操作,从而将全局结构信息引入到图像去噪过程中,实现了更好的局部细节保持。这种子空间学习的方法有希望应用于其它底层视觉任务中。
本文亮点总结
努力分享优质的计算机视觉相关内容,欢迎关注:
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看