
图像超分辨率网络中的注意力机制

来源:DeepHub IMBA 本文约2100字,建议阅读8分钟
本文为你介绍的论文试图量化和可视化静态注意力机制,并表明并非所有的注意模块都是有益的。
图像超分辨率(SR)是一种低层次的计算机视觉问题,其目标是从低分辨率观测中恢复出高分辨率图像。近年来,基于深度卷积神经网络(CNN)的SR方法取得了显著的成功,CNN模型的性能不断增长。近年来,一些方法开始将注意机制集成到SR模型中,如频道注意和空间注意。注意力机制的引入通过增强静态cnn的表示能力,极大地提高了这些网络的性能。
动机
图像的每个部分的注意力因素是高还是低? 注意力机制是否总是有利于SR模式?
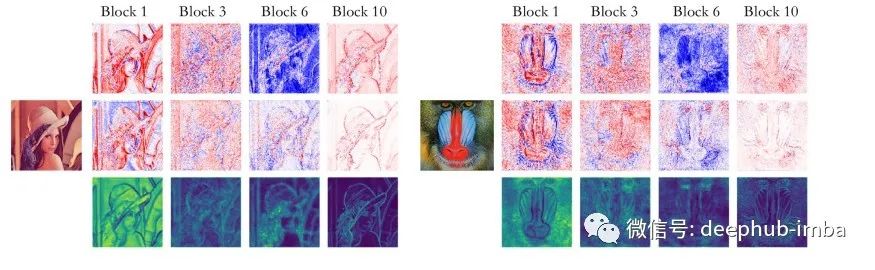
第一行:平均输入特征图。
第二行:平均输出特征图。
第三行:平均注意力地图。


方法

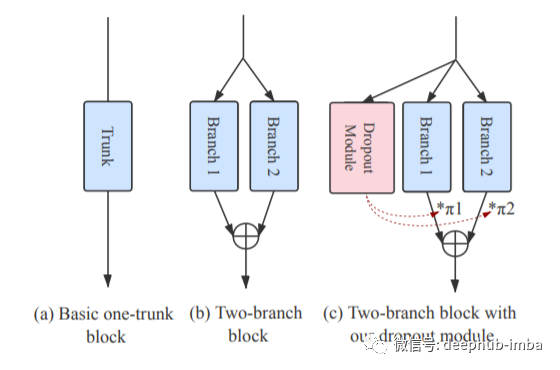
浅层的特征提取; 注意块深度特征提取中的注意力; 图像重建模块。
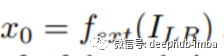

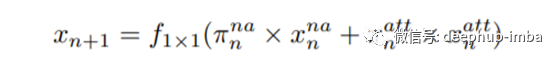
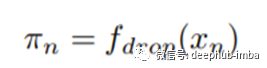
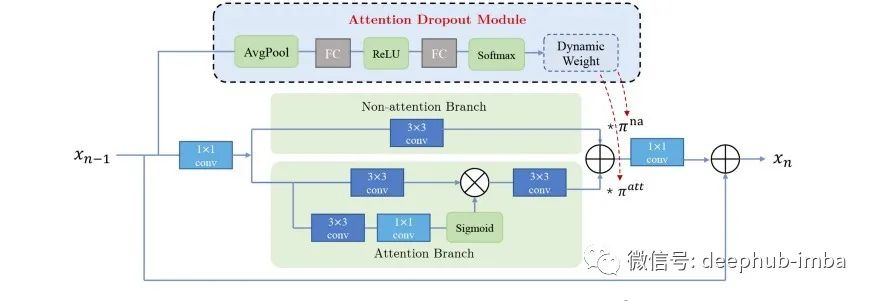
结论
编辑:黄继彦
校对:林亦霖
评论