
Panoptic SegFormer:全景分割第一名!南大&港大&英伟达提出新算法,霸榜全景分割

极市导读
在本文中,作者提出了一个用Transformer进行端到端的全景分割框架。该方法采用Deformable DETR结构,对things和stuff采用了统一的mask预测流程。使用ResNet-50主干网络,本文的方法在COCO test-dev split上实现了50.0% PQ,大大超过了以前的SOTA方法。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
今日分享论文 『Panoptic SegFormer』 全景分割第一名!由南大&港大&NVIDIA 联合提出 Panoptic SegFormer,霸榜全景分割。
话不多说,先放Leadboard:
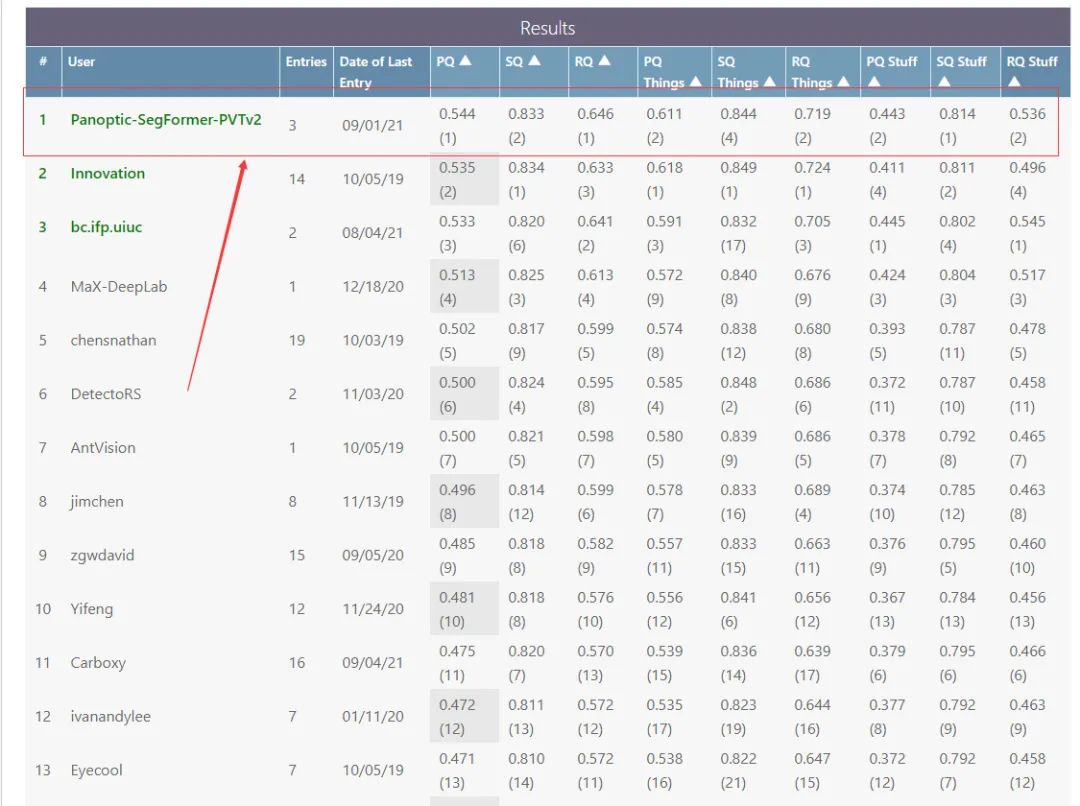
更多信息如下:

论文链接:https://arxiv.org/abs/2109.03814
项目链接:未开源
导言:
在本文中,作者提出了一个用Transformer进行端到端的全景分割框架。该方法采用Deformable DETR结构,对things和stuff采用了统一的mask预测流程,使全景分割更加简洁有效。使用ResNet-50主干网络,本文的方法在COCO test-dev split上实现了50.0% PQ,大大超过了以前的SOTA方法。使用更强的PVTv2-B5主干网络,Panoptic SegFormer在COCO test-dev split上实现了54.1% PQ 和54.4% PQ 的新记录。
01 Motivation
语义分割和实例分割是两个重要且相关的视觉问题。作为这两个任务的统一,他们的潜在联系最近推动了全景分割。在全景分割中,图像内容可分为things和stuff两类。things是可计数的实例(例如,人、汽车和自行车),每个实例都有一个唯一的id来区别于其他实例。stuff是指非定形和不可数的区域(例如,天空,草原和雪),没有实例id。
things和stuff之间的差异也导致了处理他们的不同预测方法。许多工作只是简单地将全景分割分解为实例分割任务和语义分割任务。然而,这种分离的策略往往会增加模型的复杂性。一些工作进一步考虑了bottom-up(没有proposal)的全景分割方法,但仍然保持类似的独立策略。最近的一些方法试图通过使用统一的框架处理things和stuff来简化全景分割pipeline。这些方法大多采用双分支结构,其中内核分支(kernel branch)编码目标/区域信息,并与图像级特征分支(image-level feature branch)动态地进行卷积以生成目标/区域mask。
近年来,视觉Transformer被广泛应用于实例定位和识别任务中。视觉Transformer通常将输入图像分割为多个patch,并将其编码为token。对于目标检测任务,DETR和Deformable DETR都有一组可学习的query,用于预测边界框,并与ground truth进行动态匹配。
在这项工作中,作者提出了Panoptic SegFormer,一个简洁和有效的框架,端到端用Transformer进行全景分割。具体来说,Panoptic SegFormer包含三个关键的设计:
统一表示things和stuff的quer****y集 ,其中stuff被视为只有单一实例id的特殊类型; 利用things和stuff的位置信息来提高分割质量的位置解码器 ; Mask后处理策略 ,合并things和stuff的分割结果。
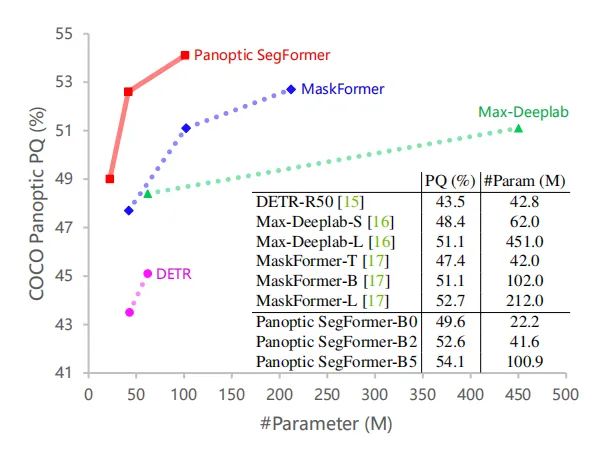
受益于这三种设计,Panoptic SegFormer高效地实现了SOTA的全精分割任务的性能。(性能对比如上图所示)
02 方法
2.1.整体架构
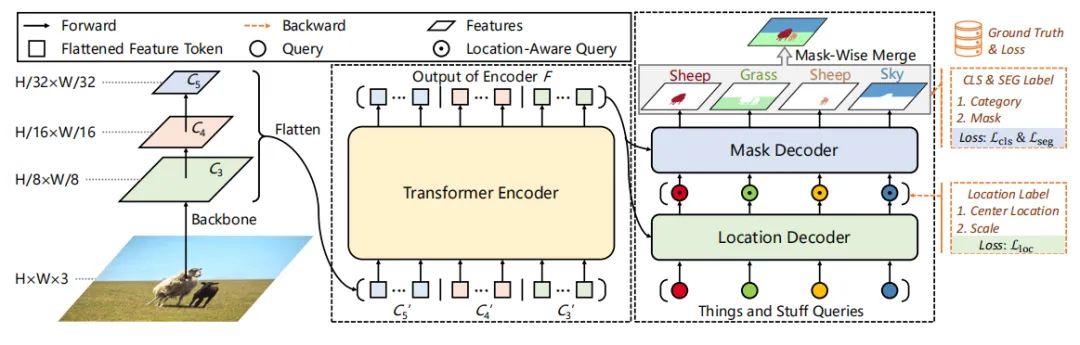
模型的整体架构如上图所示,Panoptic SegFormer由三个关键模块组成:Transformer编码器、位置解码器和Mask解码器。其中利用Transformer编码器对主干提取的多尺度特征图进行细化;利用位置解码器捕捉物体的位置线索;Mask解码器用于最终的分类和分割。
在前向阶段,我们首先将图像输入到主干网络,从最后三个阶段获得特征图、、和,与输入图像相比,其分辨率分别为1/8、1/16和1/32。然后,通过全连接(FC)层将这三个特征投影到具有256个通道的特征中,并将它们flatten为特征token 、、和。、、和的维度分别为,,。
接下来,concat这些token作为Transformer编码器的输入,Transformer编码器输出的细化特征大小为。然后使用N个初始化的query来描述things和stuff,获取position信息。最后使用mask-wise strategy来融合预测的mask,得到最终的分割结果。
2.2.Transformer编码器
高分辨率和多尺度特征图对于分割任务具有重要意义。由于多头注意层的计算成本高,以往基于Transformer的方法只能在其编码器中处理低分辨率的特征图(如ResNet的C5),这限制了分割性能。与这些方法不同,作者使用可变形的注意层(deformable attention)来实现Transformer编码器。由于可变形注意层的计算复杂度较低,本文的编码器可以拓展到高分辨率和多尺度特征图F。
2.3.位置解码器
在全景分割任务中,位置信息在区分具有不同实例id的things方面起着重要的作用。受此启发,作者设计了一个位置解码器,将things的位置信息(即中心位置和尺度)引入到可学习的query中。
具体来说,给定N个随机初始化的query和由Transformer编码器生成的细化的特征token,解码器将输出N个具有位置感知性的query。在训练阶段,作者在位置感知query的基础上应用一个辅助的MLP头来预测目标对象的尺度和中心位置,并使用位置损失来监督预测。MLP头是一个辅助分支,可以在推理阶段被丢弃。由于位置解码器不需要预测分割mask,因此作者用计算和内存更高效的可变形注意(deformable attention)来实现。
2.4.Mask解码器
Mask解码器,可以根据给定的query来预测对象的类别和Mask。Mask解码器的query Q是来自位置解码器的位置感知query,Mask解码器的key K和value V是来自Transformer编码器的细化特征token F。作者首先将query通过4个解码器层,然后从最后一个解码器层获取注意力映射和细化的query ,其中N为query数量,h为多头注意层的head数量,为特征token F的长度。
与之前的方法类似,作者直接通过最后一个解码器层的细化query 之上的FC层执行分类。同时,为了预测物体mask,作者将注意力图A split并reshape为注意图,如下所示:
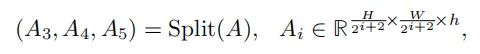
然后,将这些attention map上采样到H/8×W/8的分辨率,并沿着通道维度concat它们,如下所示:
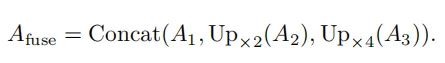
最后,基于融合注意图,通过1×1卷积来预测二进制mask。这里的attention作者没有使用deformable attention,而是采用了Transformer中的multi-head attention。
2.5.损失函数
训练过程中,训练目标是使得预测结果和ground-truth 尽可能相似,其中,ground truth 用进行pad,使之维度与相同。具体来说,作者利用Hungarian算法搜索具有最小匹配cost的排列σ。
Panoptic SegFormer的整体损失函数可以表示为:
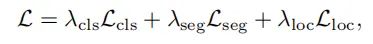
位置损失计算如下:
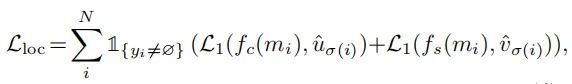
其中是 L1 loss。σ和σ是从位置解码器预测的中心点和尺度大小。和分别表示目标mask 的中心位置和尺度大小。
2.6.Mask-Wise Inference

全景分割要求为每个像素分配一个类别标签(或空)和实例id(对于stuff忽略id)。一种常用的后处理方法是采用类似NMS的过程为things生成不重叠的实例segments,作者称之为mask-wise strategy。这种启发式过程还对stuff使用像素级的argmax策略,并解决stuff和things之间的重叠,从而有利于stuff类。
本文提出的mask-wise strategy算法如上图所示。mask合并策略以c、s和m作为输入,分别表示预测的类别、置信度分数和分割mask。输出为一个语义mask 和一个实例id mask ,为每个像素分配一个类别标签和一个实例id。和首先用0初始化。
然后,将预测结果按置信分数降序排序,并将排序后的预测mask填充到 和。置信度分数低于的结果将被丢弃,较低的置信度重叠部分将会被移除,从而来生成无重叠的全景分割结果。最后,添加类别标签和实例Id(仅对于things)。
03 实验
Panoptic segmentation
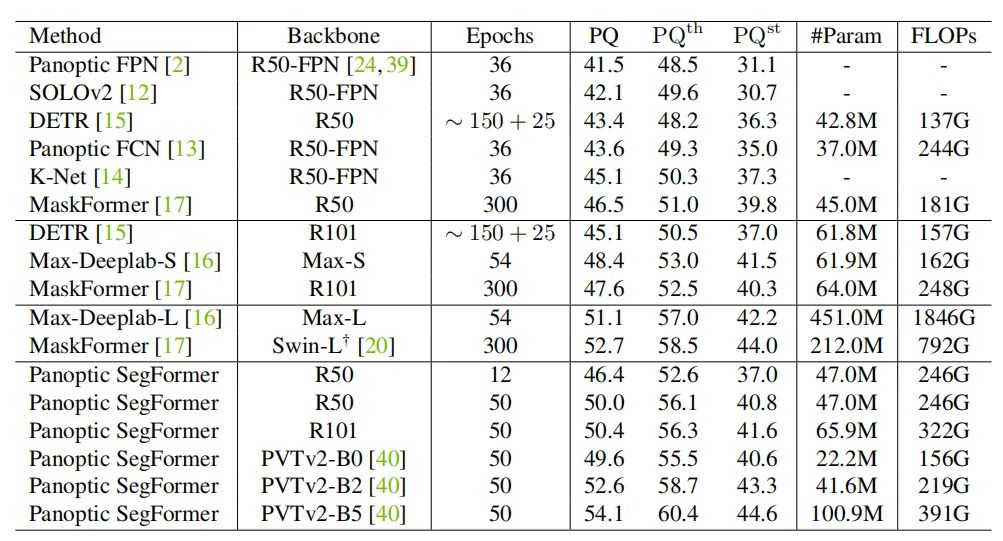
上表为全景分割COCO val set的实验结果。
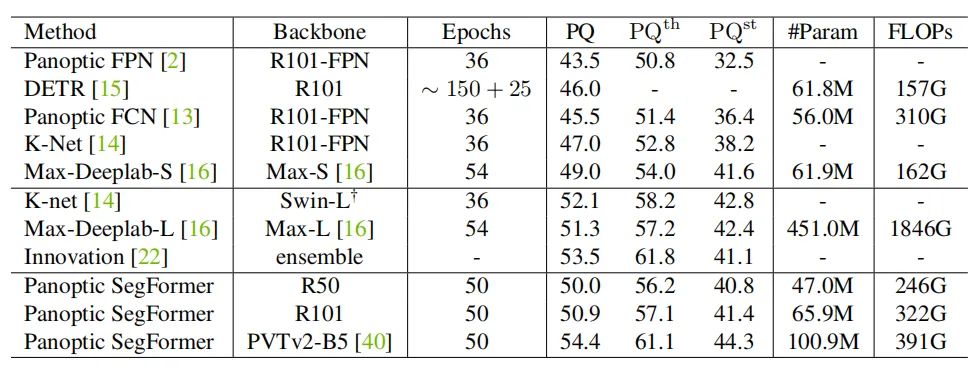
上表为全景分割COCO test-dev set的实验结果。
可以看出,本文方法与SOTA方法相比,具有明显的性能优势。
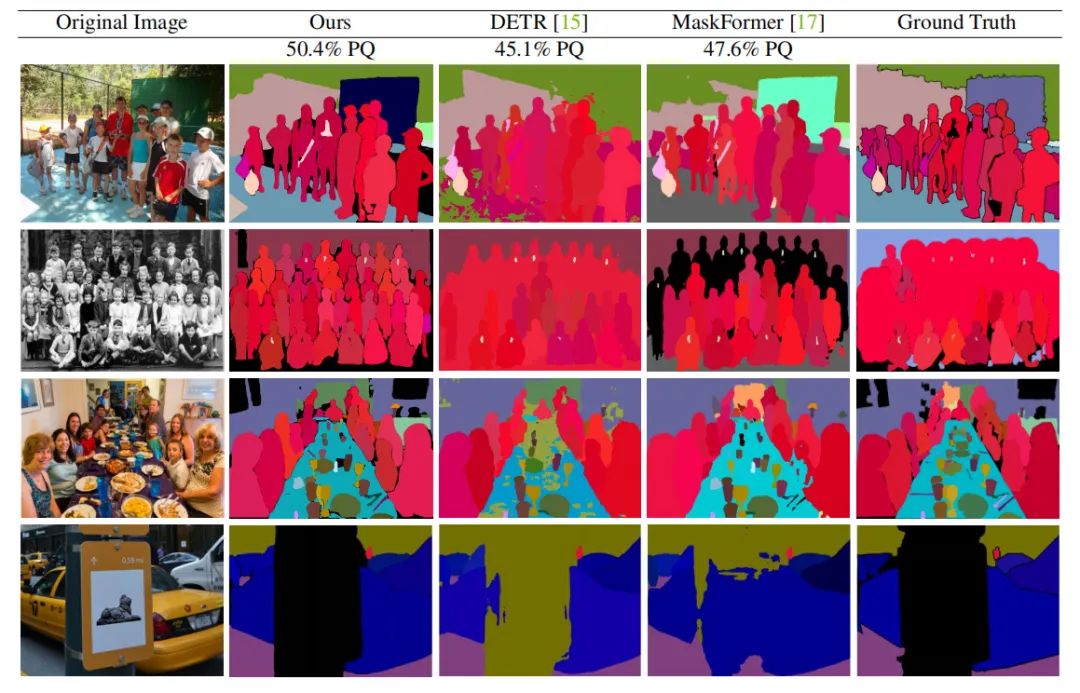
上图为全景分割的一些可视化结果。
Instance segmentation
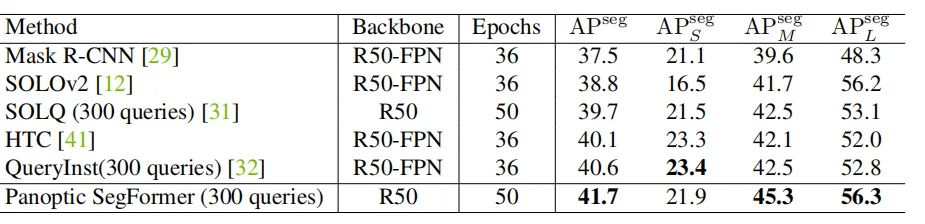
上表为本文方法和SOTA方法在实例分割上的结果,同样具有明显的性能优势。
Visualization of attention maps

上图为mask解码器中多头注意图及其相应的输出的可视化结果。我们观察到,一些head注意前景区域,一些head更关注边界,而另一些head更关注背景区域。这表明,每个mask都是通过考虑图像中的各种综合信息而生成的。
Complexity of Panoptic SegFormer
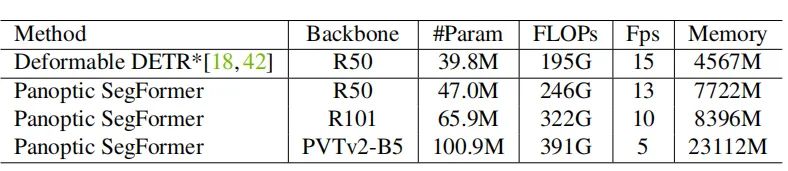
上表展示了模型的复杂性和推理效率,我们可以看到Panoptic SegFormer在可接受的推理速度上,在全景分割任务上达到SOTA的性能。
04 总结
在本文中,作者提出了Panoptic SegFormer,统一了things和stuff的处理流程。Panoptic SegFormer可以超越以前的SOTA方法,并证明了用相同的方式处理things和stuff的优越性。相比于其他全景分割框架,Panoptic SegFormer主要有以下三个设计的创新点:(1)统一表示things和stuff的query集 ;(2)利用things和stuff的位置信息来提高分割质量的位置解码器 ;(3)用于合并things和stuff的分割结果的Mask后处理策略 。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21分割”获取CVPR2021分割类论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
