拿transformer做E2E全景分割,这个通用框架霸榜挑战赛,南大、港大联合提出
视学算法报道
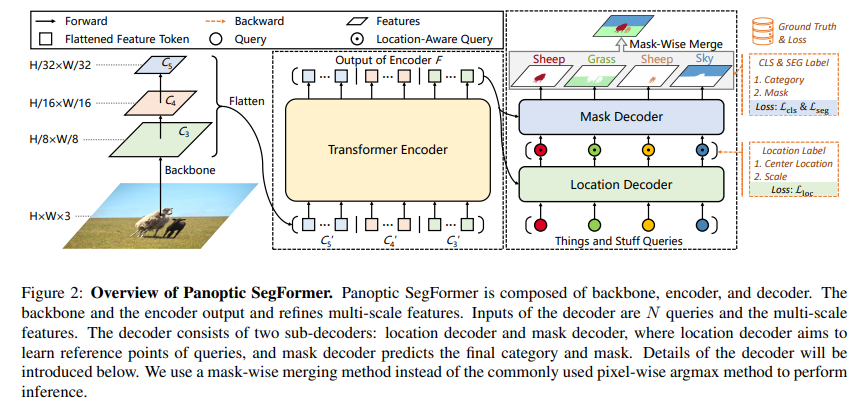
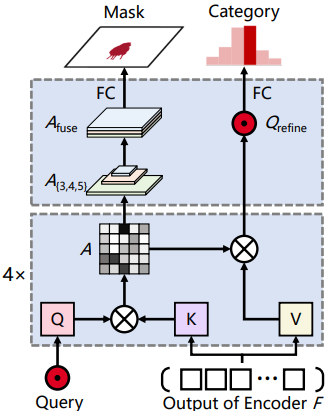
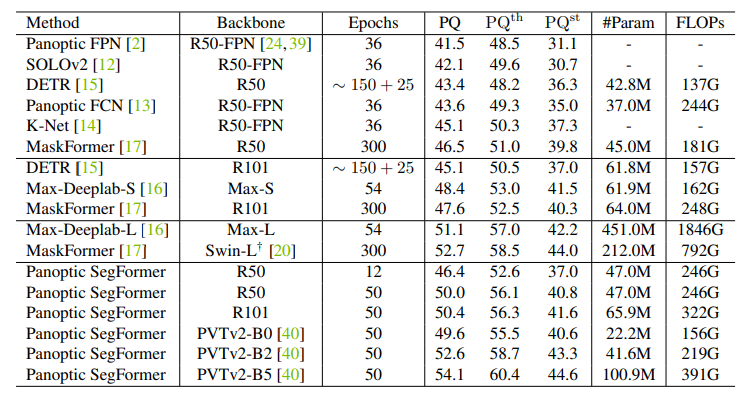
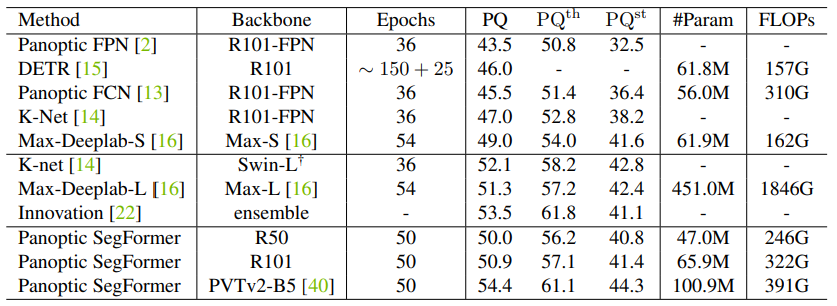
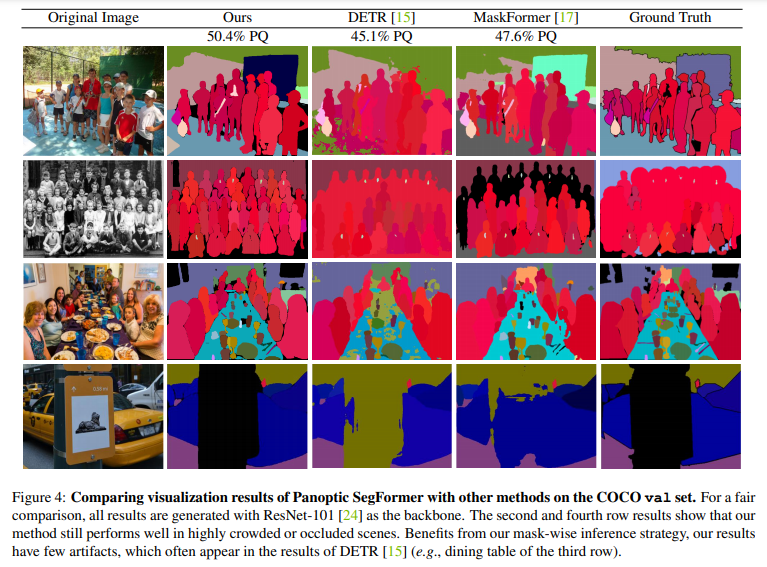
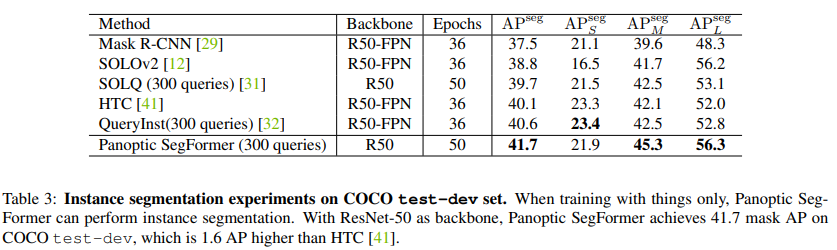
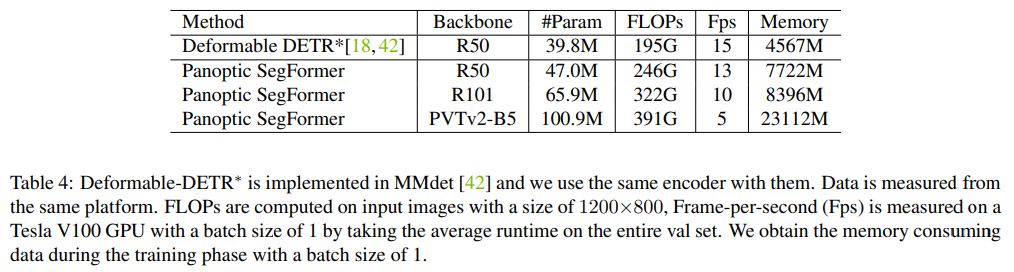
本文中,来自南大、港大、英伟达等机构的研究者提出了一个使用 transformer 进行端到端全景分割的通用框架,不仅为语义分割与实例分割提供了统一的 mask 预测工作流程,而且使得全景分割 pipeline 更加简洁高效。



© THE END
转载请联系机器之心公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论
 下载APP
下载APP视学算法报道
本文中,来自南大、港大、英伟达等机构的研究者提出了一个使用 transformer 进行端到端全景分割的通用框架,不仅为语义分割与实例分割提供了统一的 mask 预测工作流程,而且使得全景分割 pipeline 更加简洁高效。
© THE END
转载请联系机器之心公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
点个在看 paper不断!