
全景分割第一名!南大+港大+英伟达提出新算法,霸榜全景分割!
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
本文转载自我爱计算机视觉,作者小马。文章仅用于学术分享。

论文链接:https://arxiv.org/abs/2109.03814
项目链接:未开源

01
统一表示things和stuff的query集 ,其中stuff被视为只有单一实例id的特殊类型; 利用things和stuff的位置信息来提高分割质量的位置解码器 ; Mask后处理策略 ,合并things和stuff的分割结果。
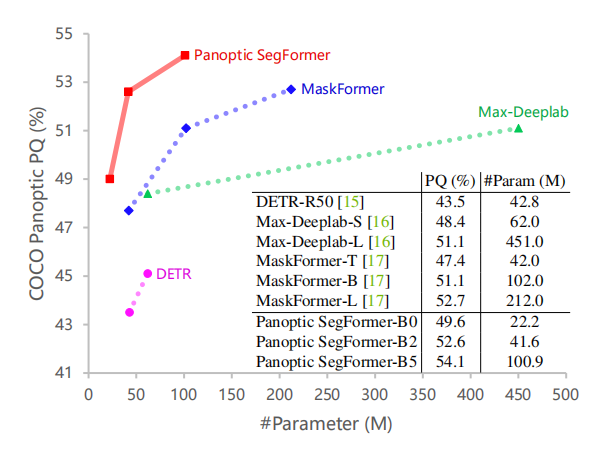
02
2.1.整体架构
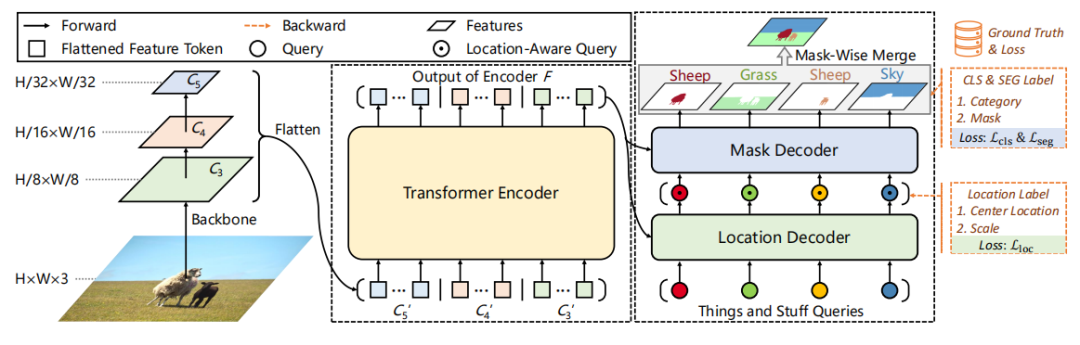
2.2.Transformer编码器
2.3.位置解码器
2.4.Mask解码器
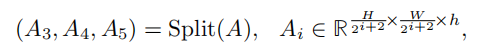
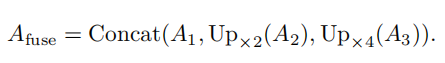
2.5.损失函数
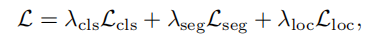
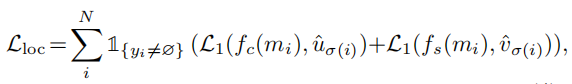
2.6.Mask-Wise Inference

03
Panoptic segmentation
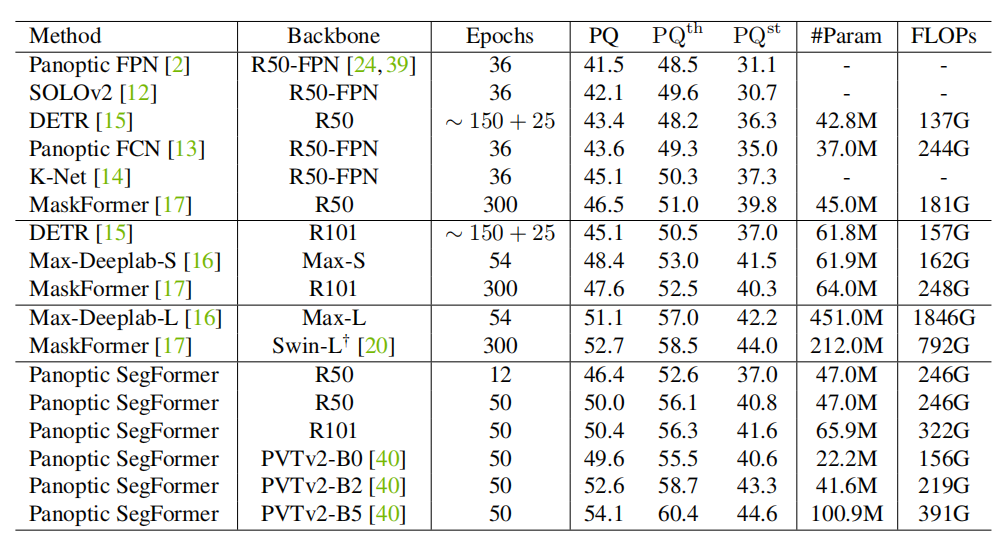


Instance segmentation
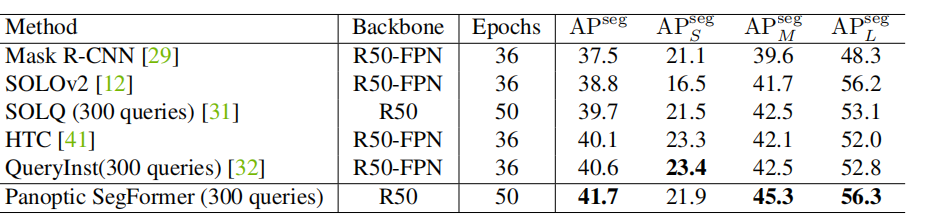
Visualization of attention maps

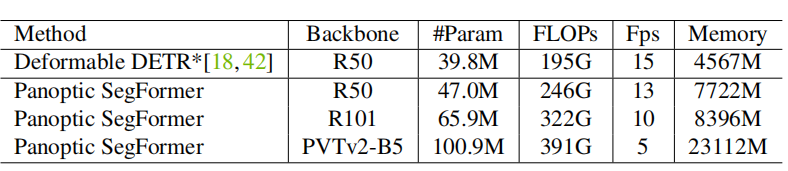
Complexity of Panoptic SegFormer
04
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文

评论