
机器学习笔记——初识逻辑回归、两种方法推导梯度公式

作者:奶糖猫
来源:奶糖猫
一、算法概述
逻辑回归(Logistic)虽带有回归二字,但它却是一个经典的二分类算法,它适合处理一些二分类任务,例如疾病检测、垃圾邮件检测、用户点击率以及上文所涉及的正负情感分析等等。首先了解一下何为回归?假设现在有一些数据点,我们利用一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合的过程就称作回归。利用逻辑回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。线性回归算法后面的笔记会介绍,这里简单对比一下两者,逻辑回归和线性回归的本质相同,都意在拟合一条直线,但线性回归的目的是拟合输入变量的分布,尽可能让所有样本到该条直线的距离最短;而逻辑回归的目的是拟合决策边界,使数据集中不同的样本尽可能分开,所以两个算法的目的是不同的,处理的问题也不同。二、Sigmoid函数与相关推导
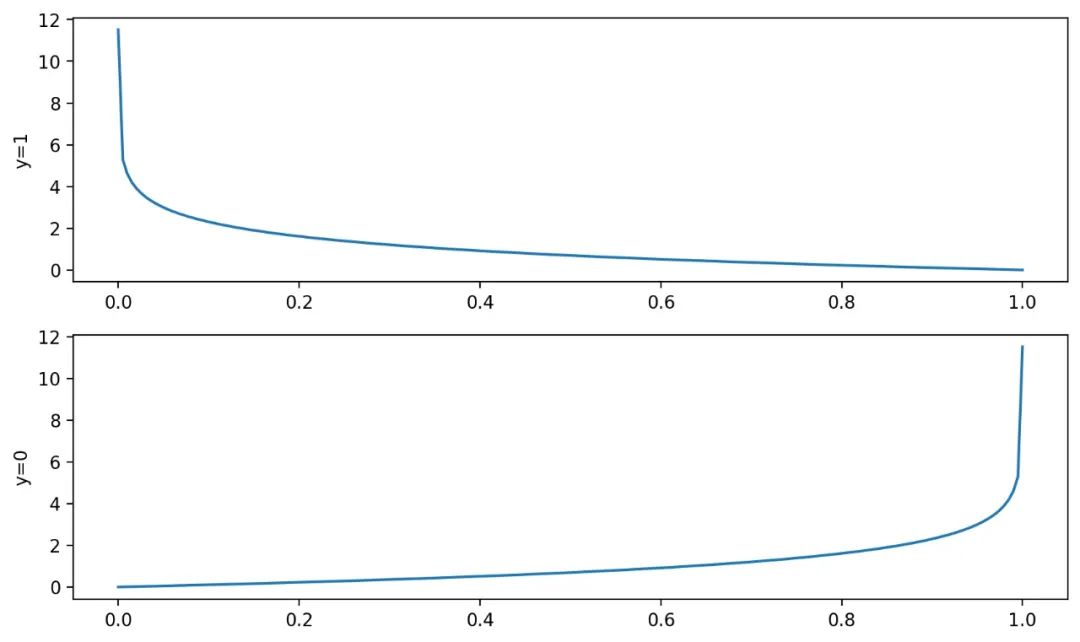
我们想要的函数应该是,能接受所有的输入并且预测出类别,比如二分类中的0或者1、正或者负,这种性质的函数被称为海维赛德阶跃函数,图像如下: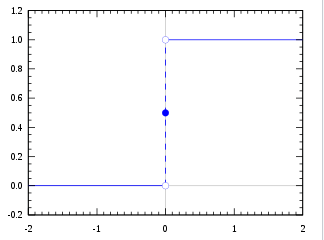
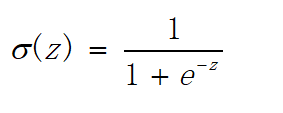
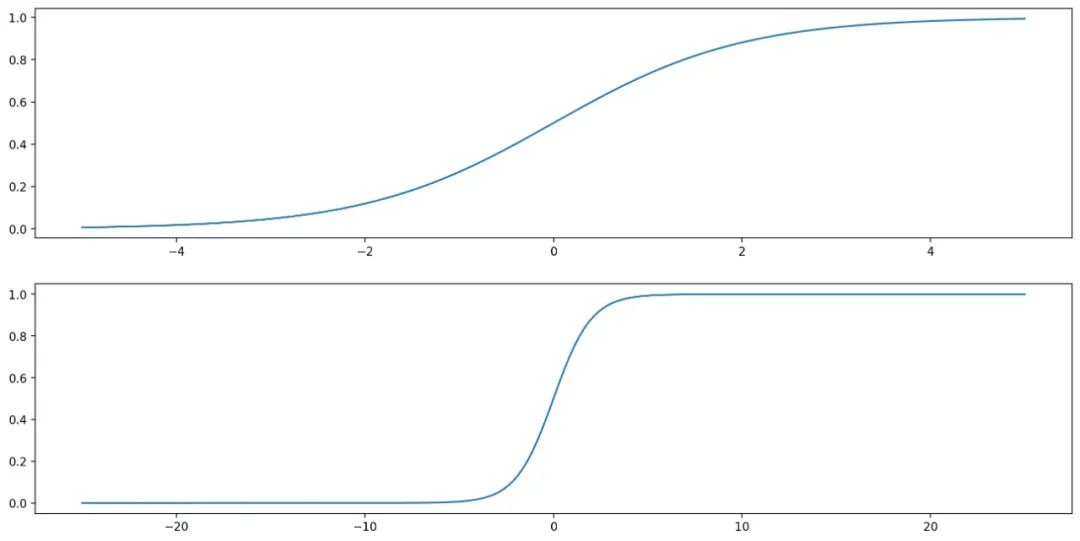
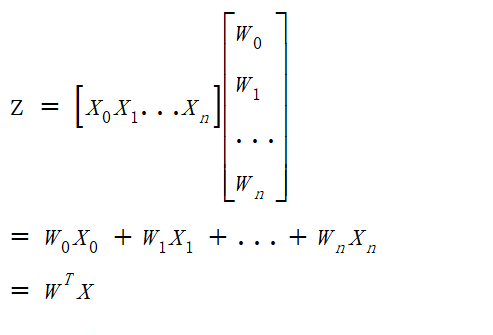
它表示将这两个数值向量对应元素相乘然后全部相加起来得到z值,其中向量x是分类器的输入数据,向量w就是我们要找到的能使分类器尽可能准确的最佳参数。
由上述公式就可得:
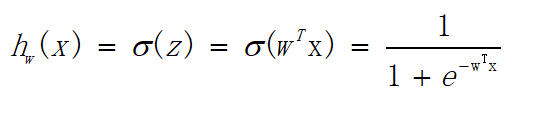
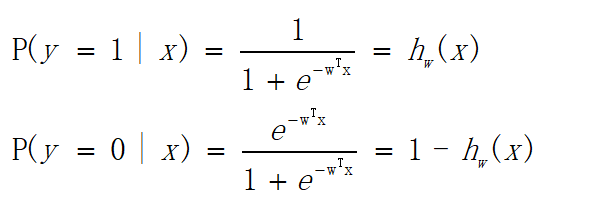
为了运算便捷,我们将其整合为一个公式,如下:
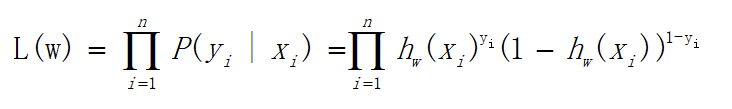
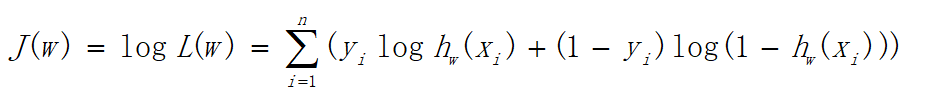 可以看出当y=1时,加号后面式子的值为0;当y=0时,加号前面式子的值为0,这与上文分类式子达到的效果是一样的。L(w)称为似然函数,l(w)称为对数似然函数,是依据最大似然函数推导而成。此时的应用是梯度上升求最大值,如果梯度下降求最小值,可在公式之前乘以。为了学习嘛,这里再介绍一下另一种方式,利用损失函数推导应用于梯度下降的公式;损失函数是衡量真实值与预测值之间差距的函数,所以损失函数值越小,对应模型的效果也越好,损失函数公式如下:
可以看出当y=1时,加号后面式子的值为0;当y=0时,加号前面式子的值为0,这与上文分类式子达到的效果是一样的。L(w)称为似然函数,l(w)称为对数似然函数,是依据最大似然函数推导而成。此时的应用是梯度上升求最大值,如果梯度下降求最小值,可在公式之前乘以。为了学习嘛,这里再介绍一下另一种方式,利用损失函数推导应用于梯度下降的公式;损失函数是衡量真实值与预测值之间差距的函数,所以损失函数值越小,对应模型的效果也越好,损失函数公式如下: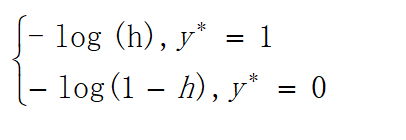
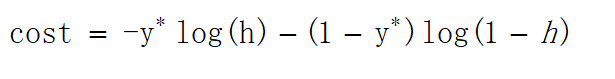
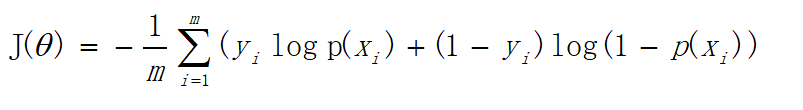
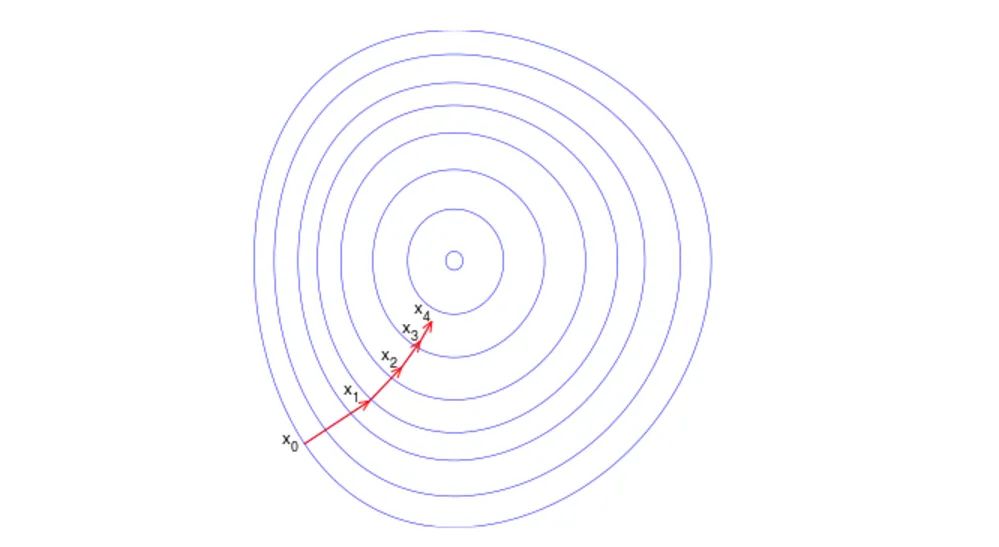
三、梯度
3.1梯度上升
上面已经列出了一大堆的公式,难道这又要开始一连串的大公式?
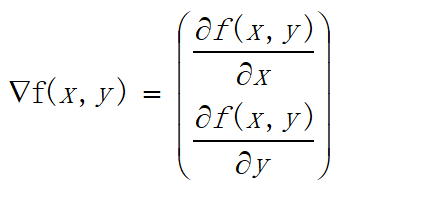
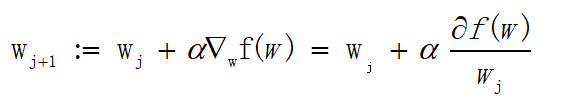
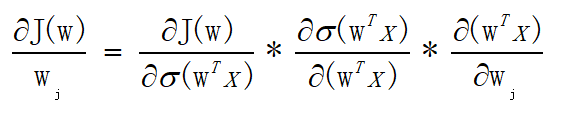
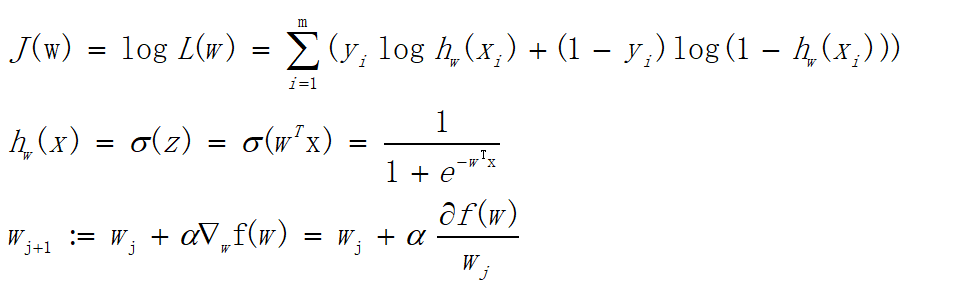
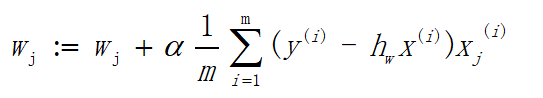
3.2梯度下降
如果利用将对数似然函数换成损失函数,则得到的是有关计算梯度下降的公式,如下: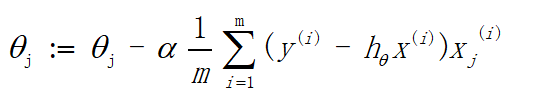
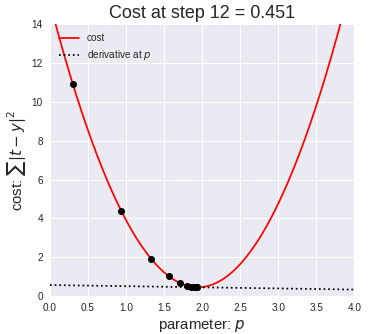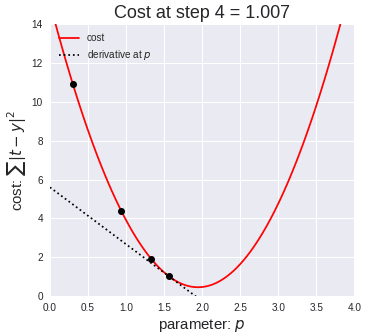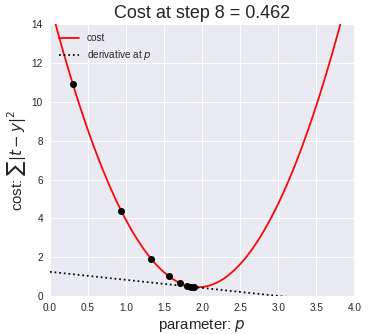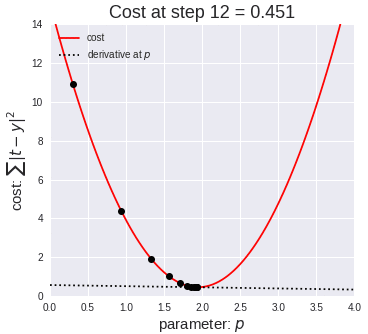

四、算法应用
4.1数据概览
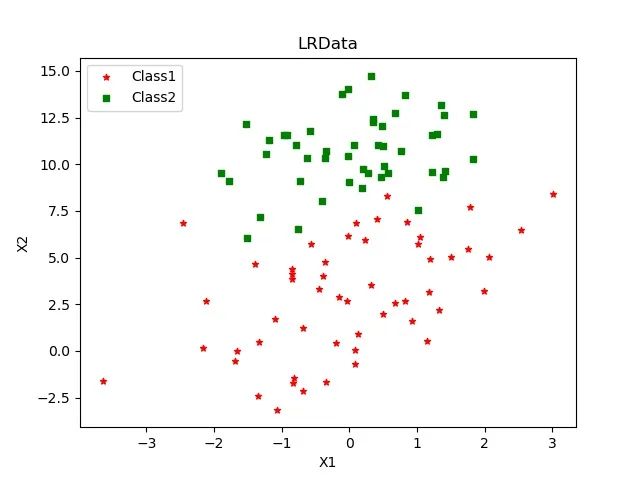
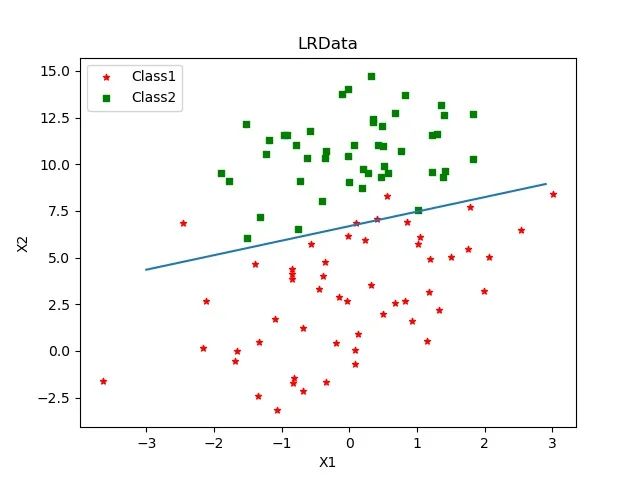
有这样一份数据集,共100个样本、两个特征(X1与X2)以及一个分类标签,部分数据和所绘制图像如下:| X1 | X2 | 类别 |
|---|---|---|
| 0.197445 | 9.744638 | 0 |
| 0.078557 | 0.059736 | 1 |
| -1.099458 | 1.688274 | 1 |
| 1.319944 | 2.171228 | 1 |
| -0.783277 | 11.009725 | 0 |
每个回归系数初始化为1
重复R次:
计算整个数据集的梯度
使用alpha*gradient更新回归系数的向量
返回回归系数
4.2加载数据集
def loadDataSet():
dataMat = [] # 创建数据列表
labelMat = [] # 创建标签列表
fr = open('LRData.txt','r',encoding='utf-8')
#逐行读取全部数据
for line in fr.readlines():
#将数据分割、存入列表
lineArr = line.strip().split()
#数据存入数据列表
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
#标签存入标签列表
labelMat.append(int(lineArr[2]))
fr.close()
return dataMat, labelMat
4.3训练算法
#sigmoid函数
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
def gradAscent(dataMatIn, classLabels):
# 将列表转换成numpy的matrix(矩阵)
dataMatrix = np.mat(dataMatIn)
# 将列表转换成numpy的mat,并进行转置
labelMat = np.mat(classLabels).T
# 获取dataMatrix的行数和列数。
m, n = np.shape(dataMatrix)
# 设置每次移动的步长
alpha = 0.001
# 设置最大迭代次数
maxCycles = 500
# 创建一个n行1列都为1的矩阵
weights = np.ones((n,1))
for k in range(maxCycles):
# 公式中hΘ(x)
h = sigmoid(dataMatrix * weights)
# 误差,即公式中y-hΘ(x)
error = labelMat - h
# 套入整体公式
weights = weights + alpha * dataMatrix.T * error
return weights

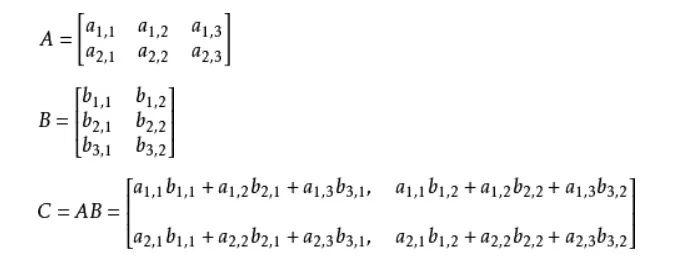
4.4绘制决策边界
def plotDataSet(weight):
#获取权重数组
weight = weight.getA()
# 加载数据和标签
dataMat, labelMat = loadDataSet()
# 将列表转换成numpy的array数组
dataArr = np.array(dataMat)
#获取样本个数
n = np.shape(dataMat)[0]
#创建4个空列表,1代表正样本、0代表负样本
xcord1 = []; ycord1 = []
xcord0 = []; ycord0 = []
# 遍历标签列表,根据数据的标签进行分类
for i in range(n):
if int(labelMat[i]) == 1:
# 如果标签为1,将数据填入xcord1和ycord1
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
# 如果标签为0,将数据填入xcord0和ycord0
xcord0.append(dataArr[i,1]); ycord0.append(dataArr[i,2])
#绘制图像
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s = 20, c = 'red', marker = '*',label = 'Class1')
ax.scatter(xcord0, ycord0, s = 20, c = 'green',marker = 's',label = 'Class2')
#绘制直线,sigmoid设置为0
x = np.arange(-3.0, 3.0, 0.1)
y = (-weight[0] - weight[1] * x) / weight[2]
ax.plot(x, y)
#标题、x标签、y标签
plt.title('LRData')
plt.legend(loc='upper left')
plt.xlabel('X1'); plt.ylabel('X2')
plt.savefig("E:\machine_learning\LR03.jpg")
plt.show()
五、文末总结
本文所讲的梯度上升公式,属于批量梯度上升,此外还有随机梯度上升、小批量梯度上升,而批量梯度上升每次计算都要计算所有的样本,所以程序计算过程是十分复杂的,并且容易收敛到局部最优,而随机梯度上升将会对算法进行调优,下一篇文章将会介绍随机梯度上升,并分析两者之间的区别。◆ ◆ ◆ ◆ ◆
长按二维码关注我们
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
评论