
深入理解逻辑回归及公式推导
导读
逻辑回归是一种线性模型,更确切的说是嵌套了一层sigmoid函数的线性模型。


写在滕王阁下的一篇文章
分类和回归是机器学习中两类经典的问题,而逻辑回归虽然叫回归,却是一个用于解决分类问题的算法模型,但确实跟回归有着密切关系——它的分类源于回归拟合的思想。
解释这个问题,得首先从回归和分类的特点说起。
回归,最简单的场景就是用身高拟合体重:给出一组身高数据,通过训练可以拟合获得期望下的体重与身高的线性关系。这里身高和体重都是连续数值,而且理论情况下这个拟合的算法模型并不限制输入输出范围——回归结果取值连续且无明确范围,这是一个明显有别于分类模型的特点。而分类则刚好相反:以最基本的二分类问题为例,其学习结果只有0和1两种,取值离散且结果有限。
进一步的,仍以身高拟合体重的回归问题为例,若此时想要得到一个关于体重是重或轻的结论,也就是给出一个二值判断,那么此时就变为一个二分类问题。最直接的思路是设定一个体重轻重的阈值:大于该值则判断为重,否则判断为轻——这也就是一个阶跃函数即可解决的问题。然而理想很美好,现实却并不合适:因为无法直接确定这个合理的阈值为多少,需要用算法训练得出;而在用算法模型计算和推导过程中又由于阶跃函数的不可导而使得这一问题变得困难。
既要求能尽可能实现阶跃函数的特性,又要在临界值附近可导,sigmoid函数应运而生,其几乎可以完美拟合阶跃函数的性质。记拟合结果为,则在阶跃函数中为,而在sigmoid函数中,。二者函数曲线对比如下图所示。
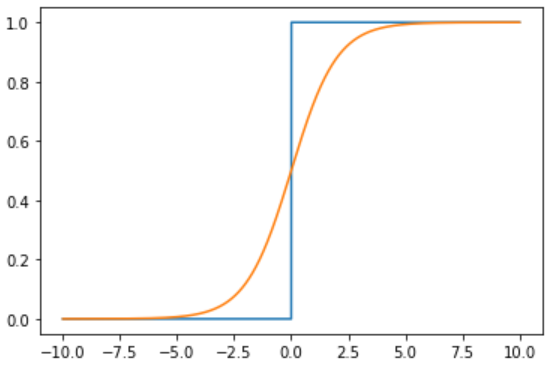
在前述体重轻重的判断问题中,由于横轴可理解成由身高数据拟合出的体重结果,纵轴则是关于该体重是重或轻的二值判断依据,显然随着体重的增加判断为重的概率越大。相较于用一个固定的阈值来硬区分轻重的方式,用这种概率的形式则有很多好处。
实际上,逻辑回归相当于首先执行一次线性拟合的回归问题,然后再通过sigmoid函数将拟合结果转化为二分类的概率问题:
稍微对二者变换一下形式,即可得到:
不同于线性回归中明确区分权重系数w和偏置b,逻辑回归中为书写方便,一般将b包含在w内,而统一写作f(x)=wx的形式。
这个形式就比较明朗了:通过f(x) = wx进行线性拟合,结果可以作为二分类中两类概率比的对数,概率比叫做几率,取对数就是对数几率,所以逻辑回归的本质就是线性回归对数几率的过程——即对数几率回归。而之所以叫逻辑回归,则是因为将线性拟合结果套一层sigmoid函数,这个函数又叫logistic函数,音译逻辑回归。
再解决了为什么叫逻辑回归的问题之后,第二个问题就是逻辑回归的损失函数。需要进行参数的优化的机器学习模型中,都需要定义相应的损失函数,例如SVM、线性回归等。那么逻辑回归的损失函数是什么呢?
注:损失函数用于描述单样本预测结果与真实结果的偏差程度,代价函数是所有样本损失的统计值,而目标函数则是代价函数和模型复杂度的加和。
这里首先给出逻辑回归的损失函数形式:
一般存在以下两种理解:
1)基于极大似然估计的理解:
前面得出,逻辑回归实质上是拟合对数几率的回归过程,而为了最大化这个概率,也就是相当于y=1时,最大化h1(x),y=0时,最大化h0(x),将二者巧妙的合并一起可表达为:
考虑所有样本的联合概率最大化,那么等价于:
2)基于损失函数意义构造:
其实这是一种先有目标结果后有构造过程。既然损失函数是描述预测结果与真实值的差距,当y=1时,预测结果为h1(x),该值越大意味着越与真实值1相近,损失越小;反之,当y=0时,预测结果为h0(x)=1-h1(x),该值越大意味着越与真实值0相近,损失越小,那么仍然沿用上面的技巧,即先分别构造两种分类下的损失函数,而后再巧妙的结合在一起:
y=1时,h1(x)越接近1,意味着最终判为1的概率越大,越接近真实标签,损失越接近于0
y=0时,h1(x)越接近0,意味着最终判为0的概率越大,越接近真实标签,损失越接近于0
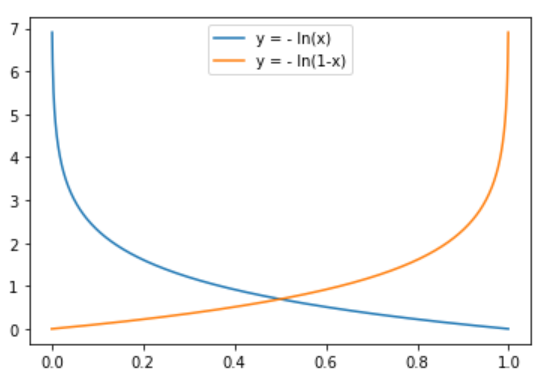
构造两种分类下的对数形式损失函数曲线
发现,对数形式的函数曲线刚好满足以上预期,所以就有了逻辑回归的损失函数,当然这里也分别用了各自情况下的损失函数与相应标签乘积的加和作为单样本的损失。
实际上,虽然关于逻辑回归的损失函数一直以来有这两种解读,但其实这是一个非常典型的分类损失函数,即交叉熵损失函数。
在明确了逻辑回归算法的损失函数后,那么剩下的就是如何迭代求解了。其实这个过程本身不难,重点是要搞清楚变量是如何传递求导的。当然,首先要知道这里要优化的参数实际上是系数向量W,更准确的说其中包含了偏置b的W。
这里首选给出一个辅助的求导中间过程,也是sigmoid函数的一个性质:
这个实际上就是权重系数w在更新过程中的梯度,进一步应用梯度下降法,可得到w的更新公式为:
此即为梯度下降法。其中,根据每次迭代更新过程中用到样本的数量,又进一步细分为批量梯度下降法(部分样本参与训练)、随机梯度下降法(随机抽取一个样本参与训练)。
逻辑回归虽然涉及到公式较多,但其实完整理解下来还是比较顺畅的,而且对于一些经典的二分类问题,也因其较强的可解释性、计算简单和不错的模型效果,而广为使用。进一步深入思考发现,逻辑回归的流程如下图所示:
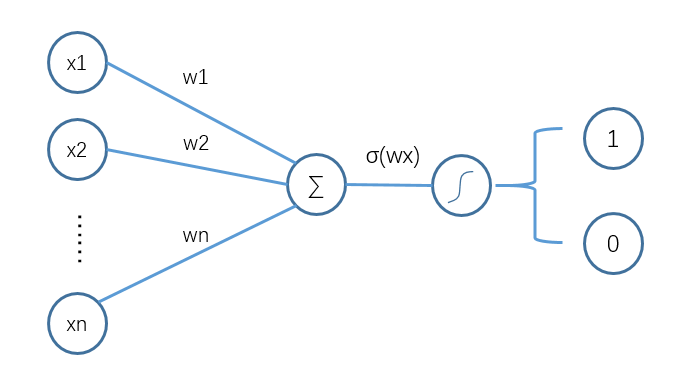
逻辑回归执行流程
巧了,这不刚好就是单层神经网络嘛!
相关阅读: