
经典Transformer | CoaT为Transformer提供Light多尺度的上下文建模能力(附论文下载)
点击上方【AI人工智能初学者】,选择【星标】公众号
期待您我的相遇与进步

CoaT为Vision Transformer提供了丰富的多尺度和上下文建模能力,表现SOTA!性能优于T2T-ViT、DeiT、PVT等网络,在目标检测、实例分割等下游任务上也涨点明显,代码即将开源!
作者单位:加州大学圣地亚哥分校(UCSD)
1 简介
1.1 快读论文
在本文中介绍了Co-scale conv-attentional image Transformers(CoaT),这是一种基于Transformer的图像分类器,其主要包含Co-scale和conv-attentional机制设计。
首先,Co-scale机制在各个尺度上都保持了Transformers编码器分支的完整性,同时允许在不同尺度下学习的表示形式能够有效地进行彼此间的通信。同时,作者还设计了一系列的串行和并行块用来实现Co-scale Attention机制。
其次,本文通过一种类似于卷积的实现方式设计了一种Factorized Attention机制,可以使得在因式注意力模块中实现相对位置的嵌入。CoaT为 Vision Transformer提供了丰富的多尺度和上下文建模功能。
在ImageNet上,与类似大小的卷积神经网络和Visioon Transformer相比,相对较小的CoaT模型可获得更好的分类结果。CoaT Backbone的有效性在目标检测和实例分割上也得到了验证,证明了其对下游计算机视觉任务的适用性。
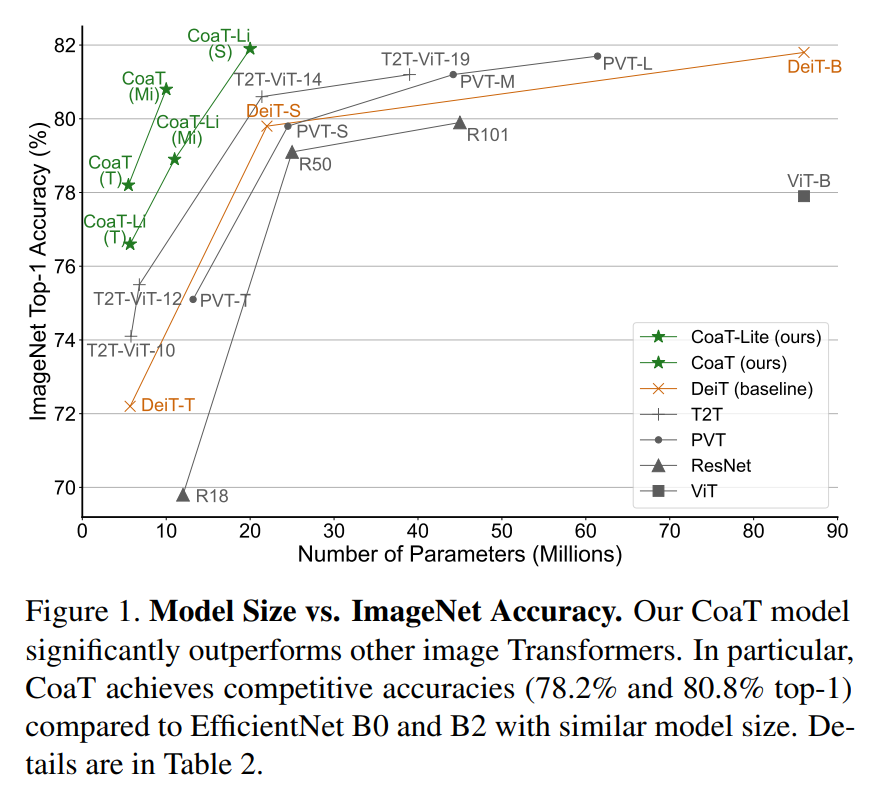
图1 ImageNet数据集精度对比
1.2 介绍工作
不管最近火起来的Vision Transformer模型还是之前的CNN模型,究其本质都是对于数据表征问题以及上下文建模问题的研究。只不过CNN是通过不断地加深网络的深度以增大感受野来进行特征的表征学习。而Attention机制与CNN运算不同:
Self-Attention中的每个位置或Token上的感受野很容易覆盖整个输入空间,因为每个Token都与包括它自己在内的所有Token“matches”;
对每1对Token的Self-Attention操作计算“query”和“key”之间的点积,然后与"value"进行加权(图2为Self-Attention计算流程图)。
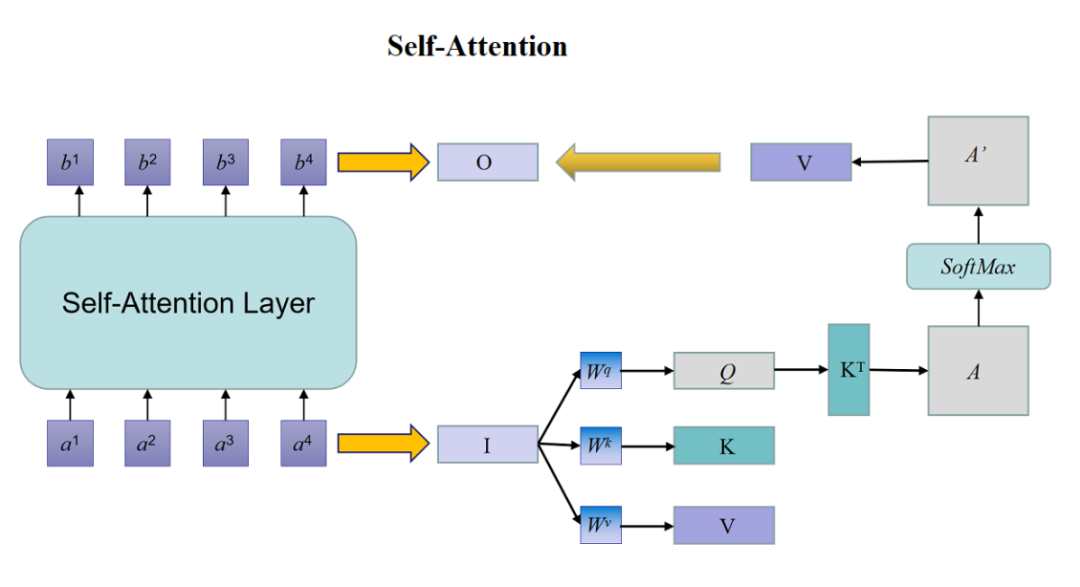
图2 Self-Attention计算流程图
此外,尽管CNN和Self-Attention操作都执行一个加权和,但它们的权值计算方式不同:在CNN中权值在训练过程中学习,但在测试过程中固定;而在Self-Attention中,根据每对Token之间的相似度或亲和度动态计算权重。因此,Self-Attention中的自相似操作提供了比卷积操作更具有潜在适应性和通用性的建模手段。此外,位置编码和位置嵌入的引入为Transformer建模提供了灵活性。
本文工作贡献总结如下:
引入了一种co-scale机制,开发了串行块和并行块2种co-scale块,实现了从细到粗、从粗到细和跨尺度的注意力图像建模。
设计了一个Conv-Attention模块,利用类似卷积的注意力操作,在Factorized Attention模块中实现相对位置嵌入。
2 观察与思考
2.1 观察
我们都知道ViT是一个从0到1的工作,它证明了从无到有构建基于Transformer的图像分类器的可行性,但如果不包含额外的训练数据,其在ImageNet上的性能是无法实现SOTA性能的;
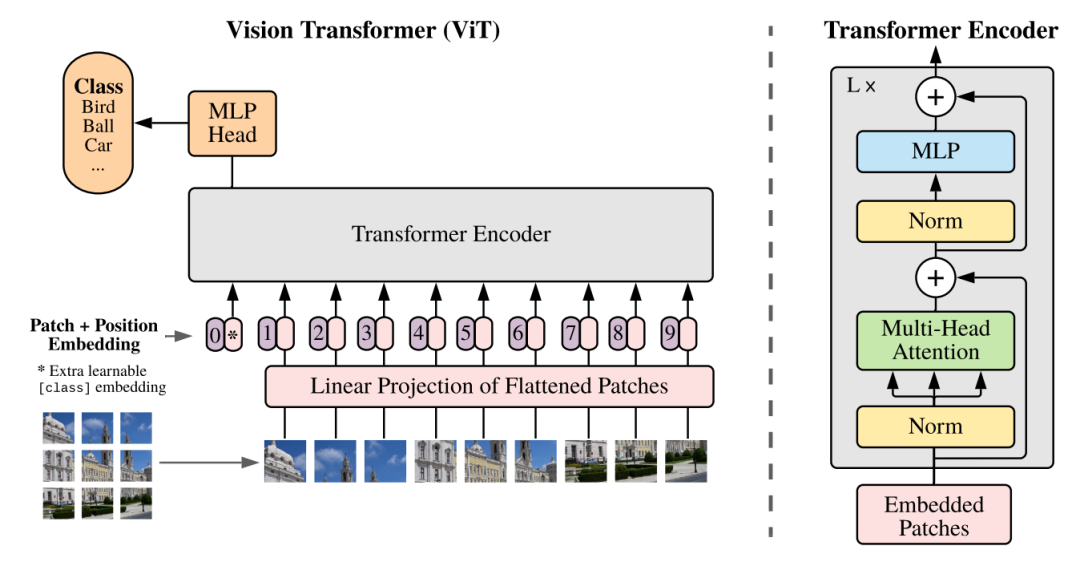
图3 ViT架构图
而DeiT通过使用有效的训练策略和模型蒸馏消除了ViT中对于数据的需求,获得了与基于卷积的分类器相当的结果。然而,ViT和DeiT都是基于单一固定Patch size的图像网格。
2.2 思考
co-scale conv-attentional transformers(CoaT)的开发主要基于以下2个方面:
多尺度模型增强了表征学习的能力;
相对位置编码与卷积之间的内在联系使得利用类conv运算进行有效的Self-Attention成为可能。
因此,在实验中显示的CoaT分类器的卓越性能来自于我们在transformer中的两个新设计:
允许跨层注意力的co-scale机制;
常规注意力模块,实现高效的Self-Attention操作。
接下来用标准的操作和概念来强调2个提议的模块的区别:
Co-Scale or Multi-Scale?
其实多尺度方法在CV领域有着悠久的历史。
比如U-Net除了标准的细到粗路径之外,还强制执行额外的粗到细路径;
HRNet通过在整个卷积层中同时保持细尺度和粗尺度,进一步增强了模型表征能力。
在Pyramid ViT就是一个类似的工作,将不同尺度层做相互融合,但Pyramid ViT只是执行一种从细到粗的策略。
这里提出的co-scale机制不同于现有的方法:CoaT由一系列高度模块化的串行和并行块组成,可以对标记化表示进行从细到粗、从粗到细以及跨尺度的关注。在co-scale module中,跨不同尺度的联合注意力机制提供了比现有多尺度方法中的标准线性融合更强的建模能力。
Conv-Attention or Attention?
其实注意力模型也很早就已经被引入视觉领域。LocalNet、Standalone Self-Attention等用Self-Attention模块代替类resnet架构中的卷积,更好地实现Local和Non-Local关系建模。而ViT和DeiT则直接采用Transformer进行图像识别。最近有研究通过引入卷积来增强注意力机制。LambdaNets引入了一种有效的Self-Attention替代方法用于全局上下文建模,并在局部上下文建模中采用3D卷积实现相对位置嵌入。CPVT将2D深度卷积设计为Self-Attention后的条件位置编码。
在conv-attention中:
采用 Lambdanetworks之后的高效因式注意力;
设计了一种深度基于卷积的相对位置编码;
将其扩展为卷积位置编码的一种替代情况。
3 Conv-Attention模块
在原始Transformer的点积问题上:
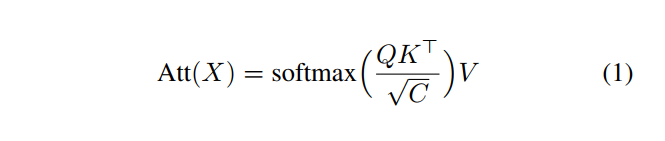
3.1 Factorized Attention机制
在公式1中,Softmax logits和Attention maps带来了
空间复杂度和
时间复杂度。本文通过使用2个函数
对其进行分解,并一起计算第2个矩阵乘法(key和value)来近似softmax attention map:
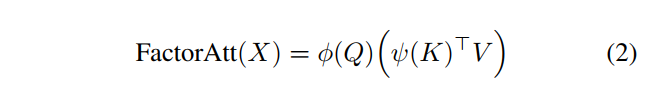
然而因式分解由于两者都是序列长度为N的线性函数,带来了
空间复杂度和
的时间复杂度,Performer在近似中使用随机映射,但代价相对较大。Efficient-Attention在视觉任务中应用了softmax函数,
和
都是有效的,但在视觉任务中会导致显著的性能下降。因此,在这里以
为恒等函数和softmax为LambdaNets开发了注意力分解机制:
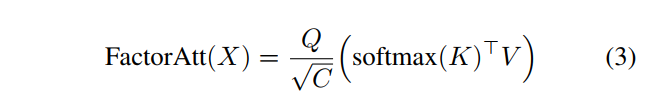
softmax(·)以element-wise方式在序列中的token和投影通道
上应用时,与LambdaNets不同的是,由于其归一化效果,作者将比例因子
添加回去,带来更好的性能。这种分解的注意力需要
空间复杂度和
时间复杂度。
值得注意的是,在LambdaNets之后提出的分解注意力并不是缩放后的点积注意的直接近似,但它仍然可以被视为一种利用query、key和value向量建模特征交互的广义注意力机制。
3.2 卷积作为位置编码
虽然因式分解的注意力模块减轻了原始点积注意力的计算负担。但是由于计算, 对于query映射Q中的每个特征向量L可以被视为一个global data-dependent linear transformation:这表明如果有2个来自Q的query
并且
,那么他们相应的self-attention输出就会是相同的:
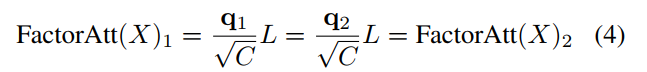
没有位置编码Transformer只是由线性层和self-attention模块组成。因此,token的输出依赖于相应的输入,而不知道其局部附近特征的任何差异。这一特性不利于视觉任务,如语义分割等。
卷积相对位置编码
为了实现视觉任务,ViT和DeiT在输入中插入绝对位置嵌入,这在建模局部token之间的相对关系时可能有一定的局限性。反之,如果将token视为一维序列,则可以将窗口大小为M相对位置编码
与relative attention map整合得到注意力公式中的相对注意力图
:
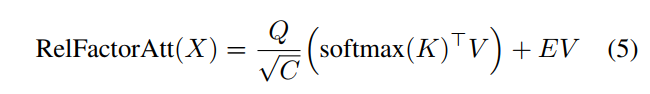
其中编码矩阵
包含元素:
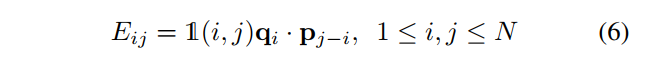
其中为指标函数。每个元素
表示从query
到window M中的value
的关系,并且
将所有相关的value向量与相应的value向量聚合起来以query
。但是EV项仍然需要
空间复杂度和
时间复杂度。在CoaT中将query中的每个通道、key向量和value向量视为internal heads,从而将EV项简化为EV。因此,对于每个internal head l有:
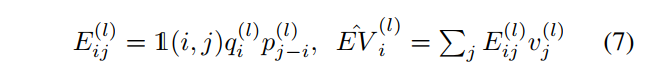
在实践中可以使用一维的深度卷积来计算
:

其中◦是Hadamard product。值得注意的是,在vision Transformers中有2种类型的token:类(CLS)token和图像token。因此,2-D深度卷积(窗口大小为M,kernel为P)仅可以应用于reshape后的图像token:
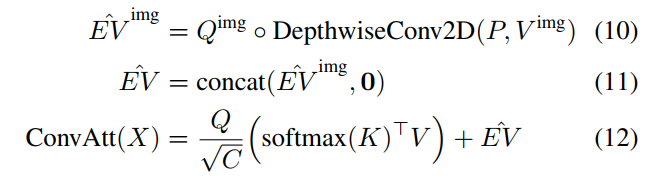
根据推导,深度可分离卷积可以看作是相对位置编码的一种特殊情况。
LambdaNets尝试直接使用3D卷积来计算EV,但它消耗了
空间复杂度和
时间复杂度,当通道大小C较大时计算量也会随之变大。相比之下factorized attention计算的
需要
空间复杂度和
时间复杂度,比lambdanet具有更好的效率。
卷积位置编码
这里将卷积相对位置编码的思想扩展到一般的卷积位置编码情况。卷积相对位置编码为query和value之间基于位置的局部关系建模。类似于大多数Image Transformer使用的绝对位置编码,可以直接将位置关系插入到输入图像特征中,以丰富相对位置编码的效果。
在每个常规注意力模块中向输入特征X插入一个深度卷积,并按照标准的绝对位置编码方案(见图4)将得到的位置感知特征连接回输入特征,这个操作类似于CPVT中条件位置编码。
这里CoaT和CoaT-lite共享同一尺度内串行和并行模块的卷积位置编码权值和卷积相对位置编码权值。对于卷积位置编码,作者设置卷积核大小为3。同时作者还设卷积核大小为3、5、7针对不同注意力head的图像特征进行卷积相对位置编码。
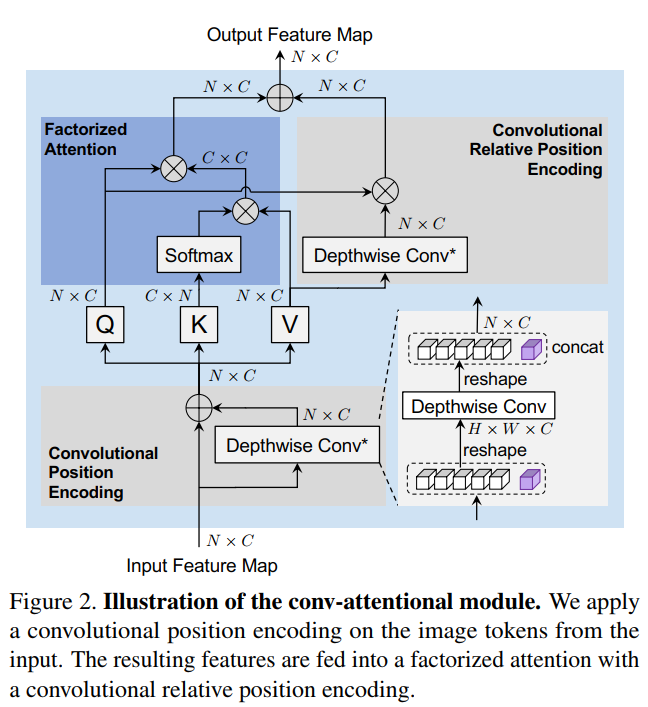
3.3 Conv-Attentional机制
最后的常规注意力模块如图4所示:对输入的图像token应用第1个卷积位置编码;然后,将其输入到ConvAtt(·)中,包括分解注意力和卷积的相对位置编码。得到的映射被用于后续的前馈网络。
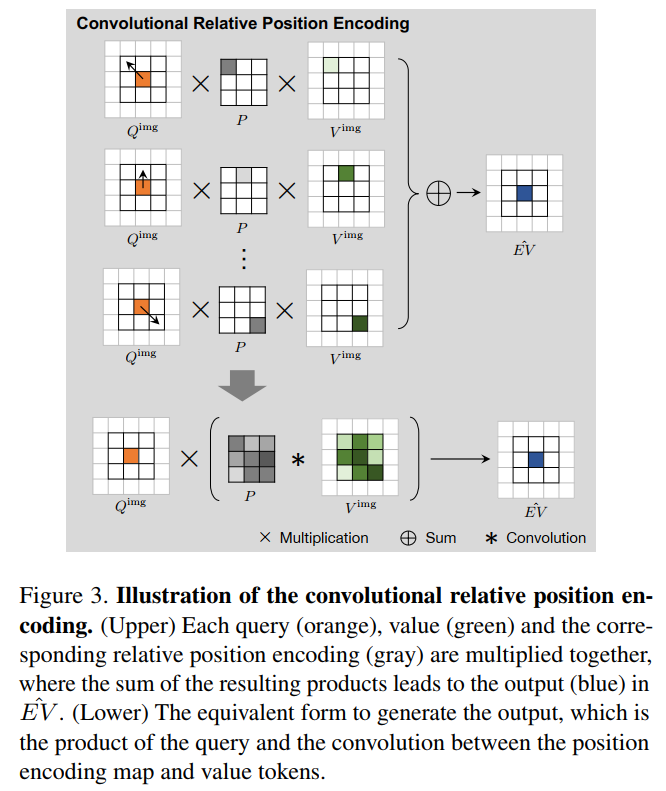
图5 convolutional relative position encoding.
在图5中image tokens
中的每个query都从value image tokens
中查找窗口中它附近的所有value。然后将query结果、每个获得的value与P中相应的相对位置编码的乘积求和,输出
。
为了减少计算量,将相对位置编码映射P作为卷积核,首先将其与图像token
的value进行卷积。然后,将query与卷积的结果相乘,生成输出
。
4. CoaT模型
4.1 Co-Scale机制
前面提到的co-scale mechanism是为了将跨尺度的注意力引入Image Transformer中。在这里,大致描述一下CoaT体系结构中2种类型的co-scale blocks,即CoaT Serial Block和CoaT Parallel Block。
CoaT Serial Block
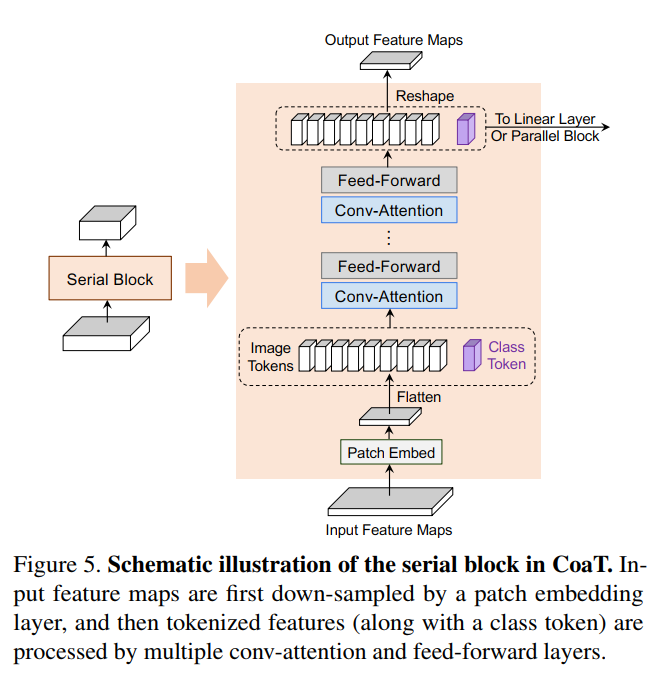
图6 CoaT中的串行模块示意图
在一个典型的serial block中:
首先,使用一个patch嵌入层(2D卷积层)按一定比例对输入特征映射进行下采样,并将缩减后的特征映射flatten为一系列图像token。
然后,将图像token与附加的CLS token连接起来,并应用到多个常规注意力模块来学习图像token和CLS token之间的内部关系。
最后,将CLS token从图像token中分离出来,并将图像token reshape为二维特征映射,用于下一个串行块。
CoaT Parallel Block
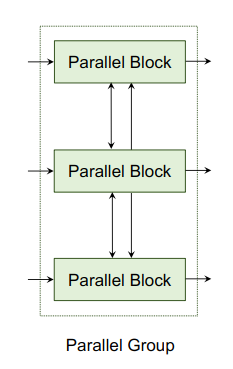
图7 CoaT中的并行模块示意图
在一个典型的parallel group中,我们有来自不同尺度的串行块的输入特征序列(图像token和CLS token)。为了实现从细到粗、从粗到细和跨尺度的attention,本文提出了2种策略:
direct cross-layer attention;
attention with feature interpolation。
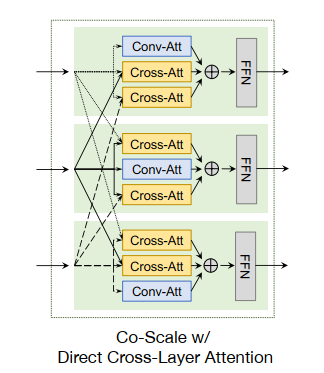
图8 direct cross-layer attention
Direct cross layer attention: 在直接跨层注意力中,从每个尺度的输入特征中形成query、key和value向量。对于同一层中的attention,使用常规attention和当前尺度的query、key和value向量。对于不同层次的attention对key向量和value向量进行下采样或上采样,以匹配其他尺度的分辨率。然后进行cross attention,通过对当前尺度的query和对另一尺度的key和value的query来扩展常规attention。最后,将常规注意力和交叉注意力的输出相加,并应用一个共享的前馈层(FFN)。
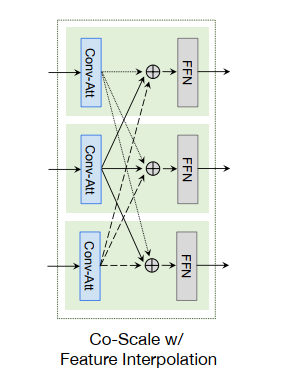
图9 Attention with feature interpolation
Attention with feature interpolation: 首先,利用independent conv-attention modules对不同尺度的输入图像特征进行处理。然后,对每个尺度的图像特征进行下采样或上采样,用双线性插值的方法匹配其他尺度的维数,或保持自身尺度的维数不变。属于同一尺度的特征在并行组中相加,并进一步传递到一个共享的前馈层。这样,下一步的常规注意力模块就可以通过当前步骤的特征插值来学习跨层信息。
4.2 Model Architecture
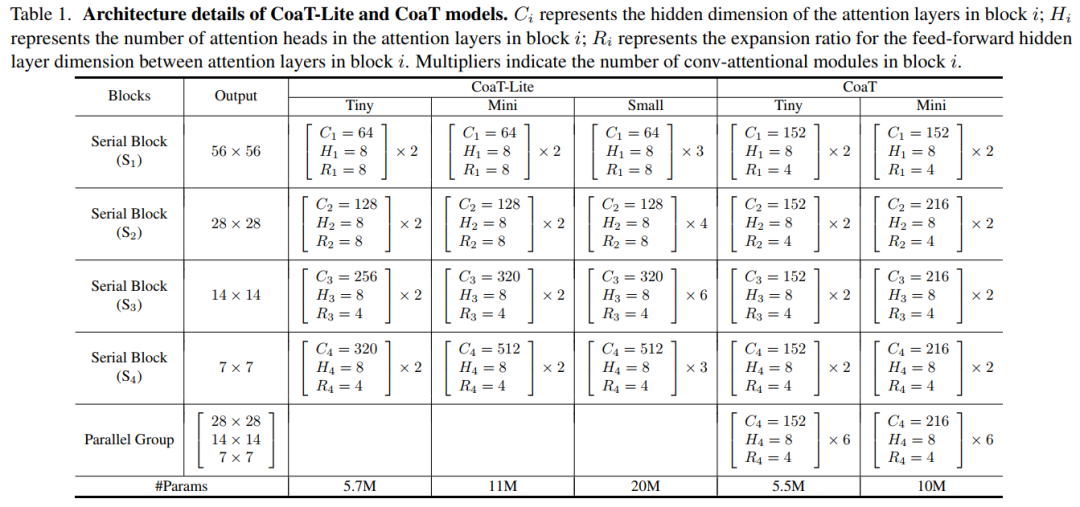
CoaT-Lite和CoaT 配置表
CoaT-Lite
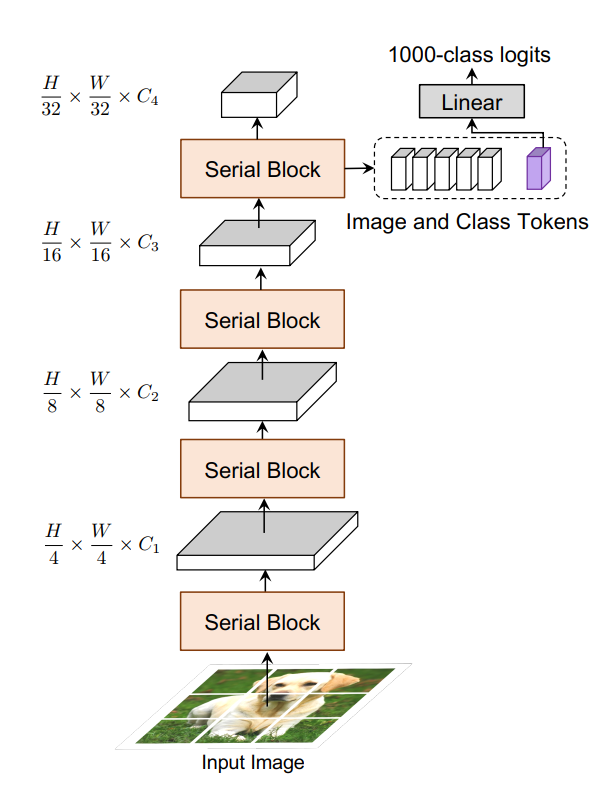
图10 CoaT-Lite
CoaT
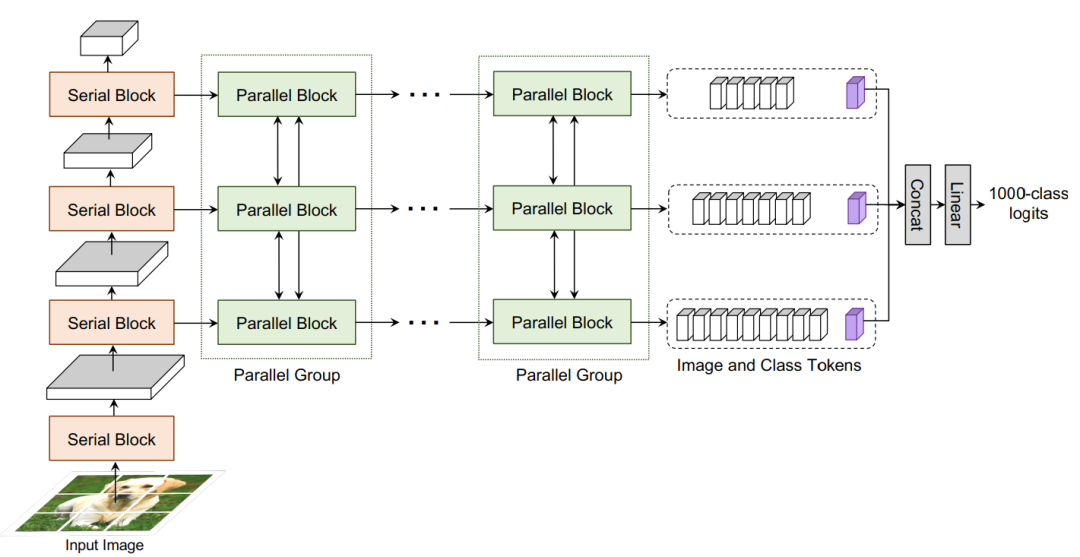
图11 CoaT
5 实验
5.1 图像分类
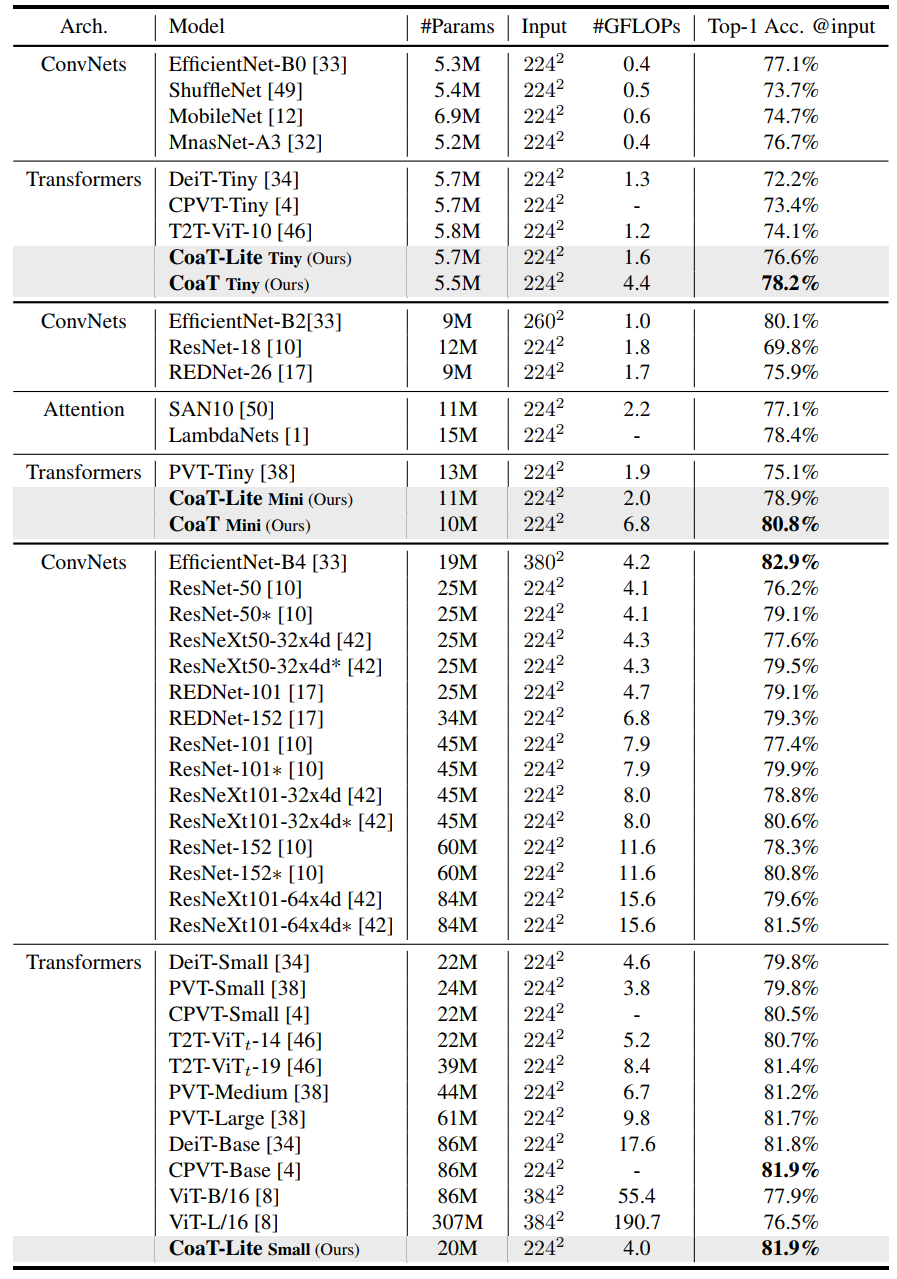
在大约5M、10M和20M的参数预算下,CoaT和CoaT-lite超过了所有的基于Transformer的架构。
5.2 目标检测与实例分割
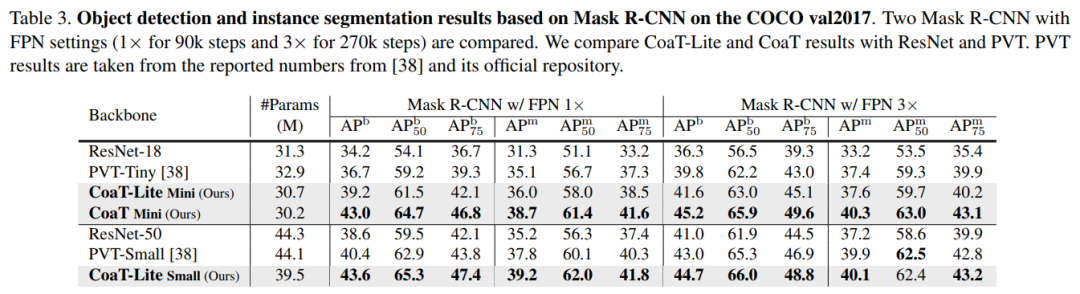
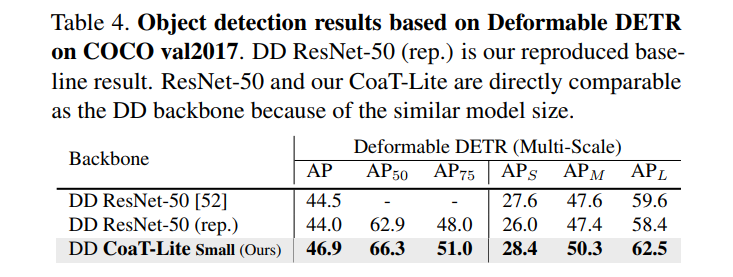
在1×和3× setting下,CoaT和CoaT-lite模型都显示出比ResNet和PVT Backbone明显的性能优势。
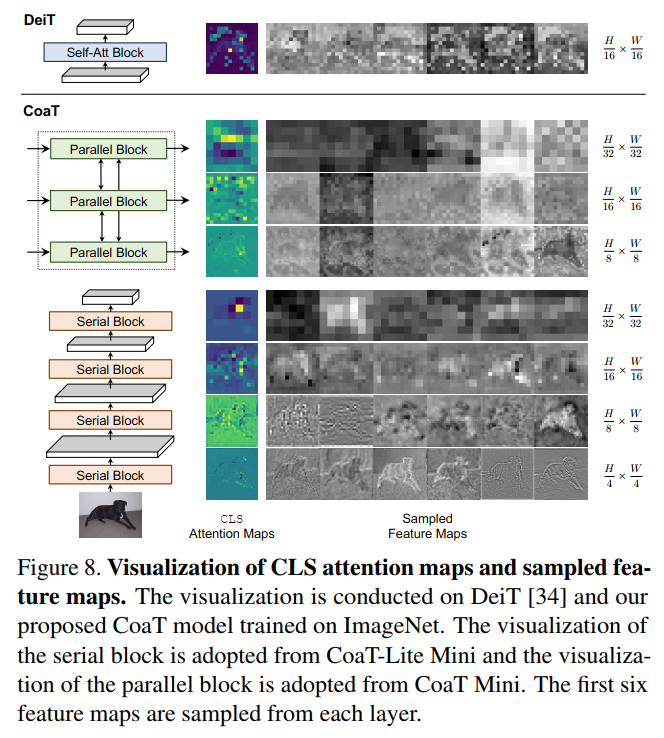
5.3 可视化
6 参考
[1].Co-Scale Conv-Attentional Image Transformers
7 推荐阅读
又改ResNet | 重新思考ResNet:采用高阶方案的改进堆叠策略(附论文下载)
VariFocalNet | IoU-aware同V-Focal Loss全面提升密集目标检测(附YOLOV5测试代码)
最强Vision Trabsformer | 87.7%准确率!CvT:将卷积引入视觉Transformer(文末附论文下载)
全新FPN | 通道增强特征金字塔网络(CE-FPN)提升大中小目标检测的鲁棒性(文末附论文)
本文论文原文获取方式,扫描下方二维码
回复【CoaT】即可获取论文与源码
长按扫描下方二维码加入交流群
声明:转载请说明出处
扫描下方二维码关注【AI人工智能初学者】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!!!
点“在看”给我一朵小黄花呗![]()