
ViLT:最简单的多模态Transformer
之所以用这一篇作为多模态的开篇是因为这篇清楚的归纳了各种多模态算法,可以当成一个小综述来看,然后还提出了一种非常简单的多模态Transformer方法ViLT。
先阐述一下4种不同类型的Vision-and-Language Pretraining(VLP),然后归纳2种模态相互作用方式和3种visual embedding方式,最后讲一下ViLT的设计思路。
01
Taxonomy of VLP
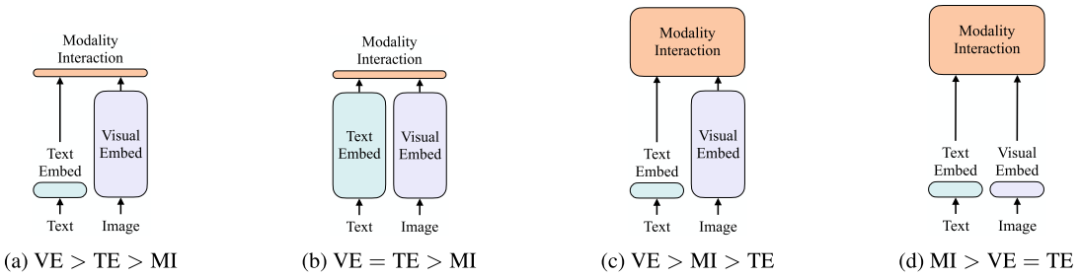
上图是4种不同类型的VLP模型示意图。其中每个矩形的高表示相对计算量大小,VE、TE和MI分别是visual embedding、text embedding和modality interaction的简写。
作者提出这4种类型的主要依据有两点:
1.在参数或者计算上,两种模态是否保持平衡。
2.在网络深层中,两种模态是否相互作用。
VSE、VSE++和SCAN属于(a)类型。对图像和文本独立使用encoder,图像的更重,文本的更轻,使用简单的点积或者浅层attention层来表示两种模态特征的相似性。
CLIP属于(b)类型。每个模态单独使用重的transformer encoder,使用池化后的图像特征点积计算特征相似性。
ViLBERT、UNTER和Pixel-BERT属于(c)类型。这些方法使用深层transformer进行交互作用,但是由于VE仍然使用重的卷积网络进行特征抽取,导致计算量依然很大。
作者提出的ViLT属于(d)类型。ViLT是首个将VE设计的如TE一样轻量的方法,该方法的主要计算量都集中在模态交互上。
Modality Interaction Schema
模态交互部分可以分成两种方式:一种是single-stream(如BERT和UNITER),另一种是dual-stream(如ViLBERT和LXMERT)。其中single-stream是对图像和文本concate然后进行交互操作,而dual-stream是不对图像和文本concate然后进行交互操作。ViLT延用single-stream的交互方式,因为dual-stream会引入额外的计算量。
Visual Embedding Schema
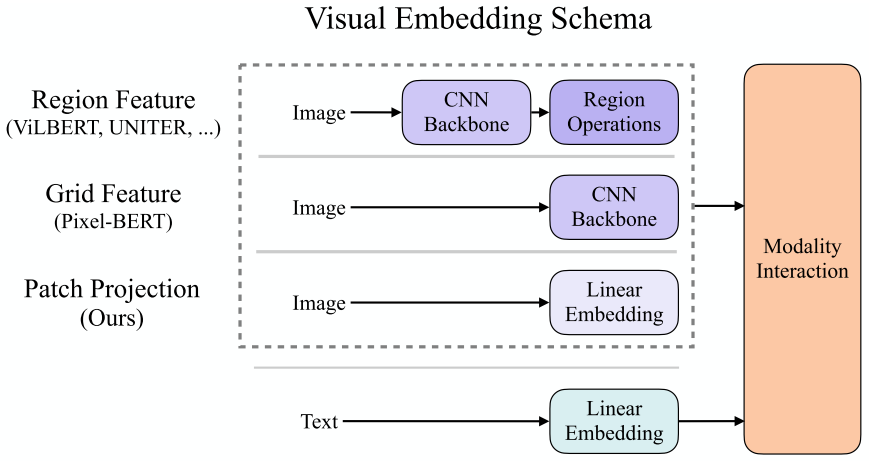
现有的VLP模型的text embedding基本上都使用类BERT结构,但是visual embedding存在着差异。在大多数情况下,visual embedding是现有VLP模型的瓶颈。visual embedding的方法总共有三大类,其中region feature方法通常采用Faster R-CNN二阶段检测器提取region的特征,grid feature方法直接使用CNN提取grid的特征,patch projection方法将输入图片切片投影提取特征。ViLT是首个使用patch projection来做visual embedding的方法。
02
ViLT
Model Overview
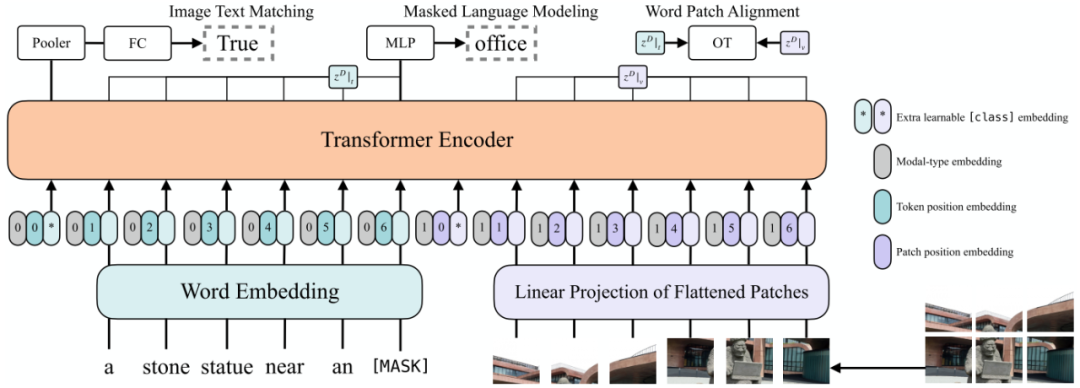
作者提出的ViLT可以认为是目前最简单的多模态Transformer方法。ViLT使用预训练的ViT来初始化交互的transformer,这样就可以直接利用交互层来处理视觉特征,不需要额外增加一个视觉encoder。
文本特征输入部分,将文本看成一个词序列,通过word embedding matrix转化成word embedding,然后和position embedding进行相加,最后和modal-type embedding进行concate。
图像特征输入部分,将图像切块看成一个图像块序列,通过linear projection转化成visual embedding,然后和postion embedding进行相加,最后和modal-type embedding进行concate。
其中word embedding和visual embedding通过可学习的modal-type embedding标志位来区分,其中0标志位表示word embedding部分,1标志位表示visual embedding部分。
wrod embedding和visual embedding分别都嵌入了一个额外的可学习[class] embedding,方便和下游任务对接。
Pretraining Objectives
ViLT预训练的优化目标有两个:一个是image text matching(ITM),另一个是masked language modeling(MLM)。
ImageText Matching:随机以0.5的概率将文本对应的图片替换成不同的图片,然后对文本标志位对应输出使用一个线性的ITM head将输出feature映射成一个二值logits,用来判断图像文本是否匹配。另外ViLT还设计了一个word patch alignment (WPA)来计算teextual subset和visual subset的对齐分数。
Masked Language Modeling:MLM的目标是通过文本的上下文信息去预测masked的文本tokens。随机以0.15的概率mask掉tokens,然后文本输出接两层MLP与车mask掉的tokens。
Whole Word Masking:另外ViLT还使用了whole word masking技巧。whole word masking是将连续的子词tokens进行mask的技巧,应用于BERT和Chinese BERT是有效的。比如将“giraffe”词tokenized成3个部分["gi", "##raf", "##fe"],那么可以mask成["gi", "[MASK]", "##fe"],模型使用[“gi”,“##fe”]来预测mask的“##raf”,而不使用图像信息。
03
实验结果

如图所示,ViLT相比于region feature的方法速度快了60倍,相比于grid feature的方法快了4倍,而且下游任务表现出相似甚至更好的性能。
从table2、table3和table4中可以看出,相对于region和grid的方法,ViLT在下游任务表现出相似甚至更好的性能。
可视化

通过可视化可以看出,ViLT学到了word和image patch之间的对应关系。
04
总结
BERT和ViT给多模态Transformer提供了基础,通过巧妙的proxy task设计,ViLT成功将BERT和ViT应用于多模态Transformer。总体上来看基于patch projection的多模态方法速度优势非常大,但是整体上性能还是略低于region feature的方法,期待未来会有更强的基于patch projection的多模态方法出现。
Reference
[1] ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision

觉得有用给个在看吧 