
当前最快的实例分割模型:YOLACT 和 YOLACT++

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
YOLACT
YOLACT: Real-time Instance Segmentation
https://arxiv.org/abs/1904.02689
这篇文章的目标是解决实例分割的实时性问题。通过在现有one-stage目标检测模型的基础上添加mask分支来解决这一问题。与Mask R-CNN等明显使用特征定位步骤(特征repooling)的方法不同,在YOLACT中并不存在这一步。
为了达到这一目的,作者将实例分割任务划分为两个更简单的平行任务,通过对这两个任务的结果进行融合来得到最终的实例分割结果。具体如下:
第一分支:使用全卷积网络(FCN)作为分支来产生一些具有整个图像大小的“prototype masks”,这些prototype masks不与任何实例相关;
第二分支:在目标检测分支的基础上添加额外的head,该head针对每一个anchor都预测一个掩膜系数(mask coefficients)。这些系数的作用是在prototype空间对某个实例的表示进行编码。
最后,在使用NMS得到所有的实例后,对其中的每一个实例都通过对上述两个分支的结果进行线性组合来得到所对应的掩膜。结构如下图所示:
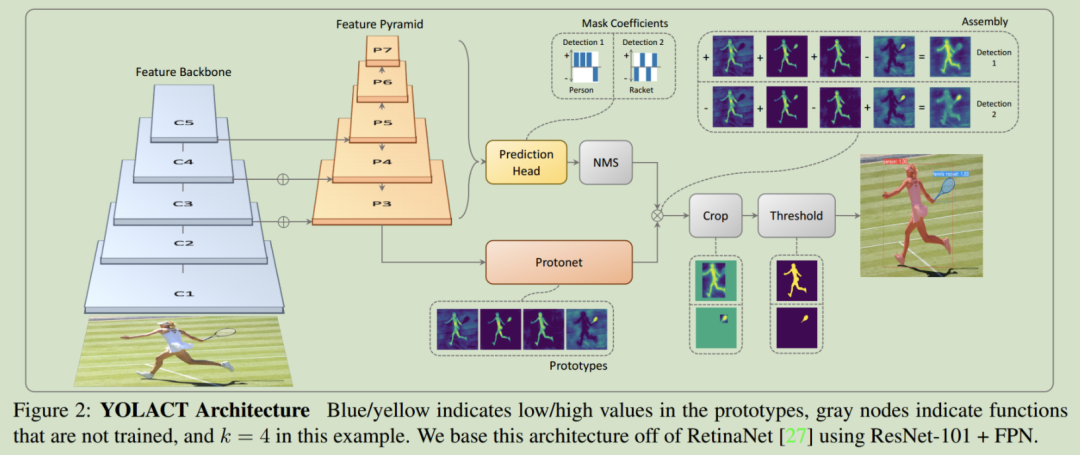
作者这么做的依据在于掩膜之间是空间相关的:例如相邻的两个像素更有可能属于同一个实例。卷积层很自然地利用了这一相关性,但全连接层没有。这会导致一个问题,对于one-stage目标检测器来说,其使用全连接层来针对每一个anchor输出类别预测和box系数,无法利用到掩膜的空间相关性;而类似于Mask R-CNN的two stages方法则使用额外的定位步骤(RoI-Align)来解决这一问题,定位步骤既保留了特征图中的空间相关性,也可以使用卷积运算得到掩膜输出。但是这一做法的代价是,定位层会引入额外的计算,降低算法的运行效率。
因而,将这一问题分为了两个平行的步骤:使用善于产生语义向量的全连接层来产生掩膜系数,而使用善于产生空间相关掩膜的卷积层来产生”prototype masks”。
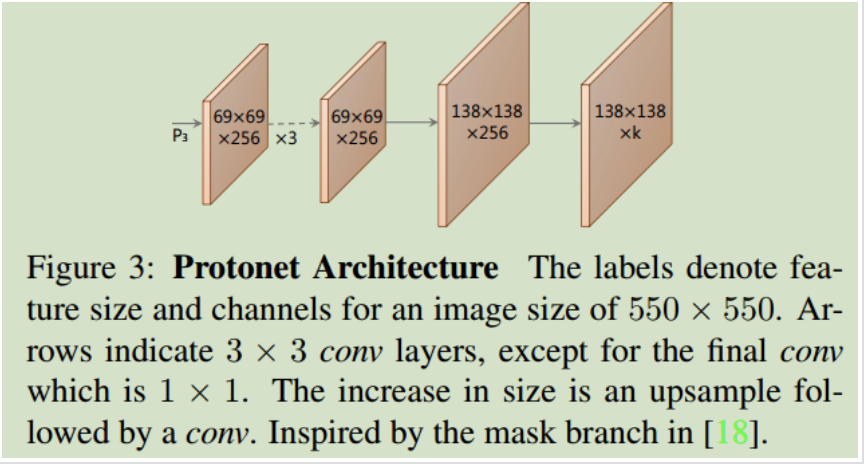
Protonet由FCN构成,其最后一层输出k个通道,每一个通道对应一个类别的prototype mask。结构如下所示。

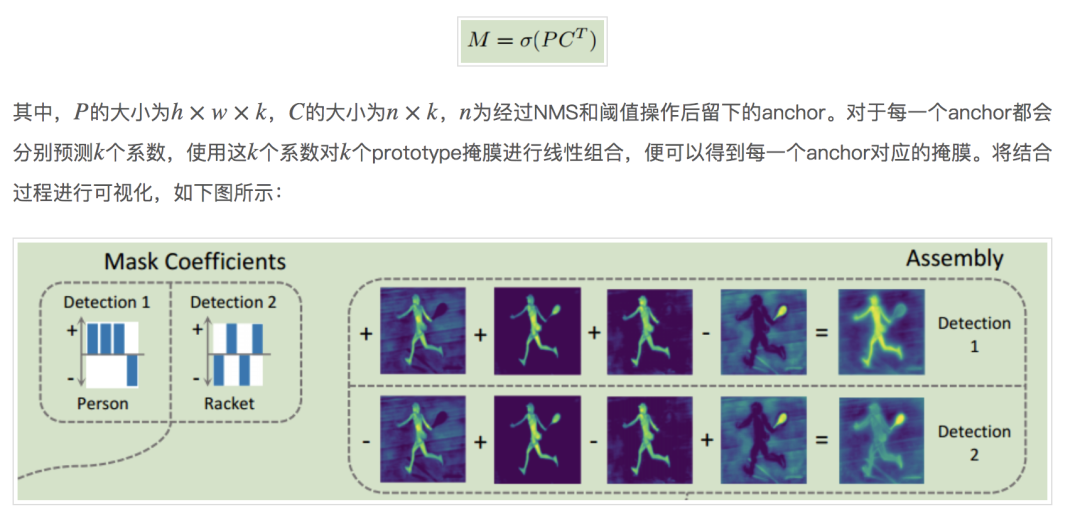
接着,将上述两个步骤得到的prototype mask和掩膜系数做矩阵乘法,并使用Sigmoid进行激活,便可以得到最终的实例掩膜。

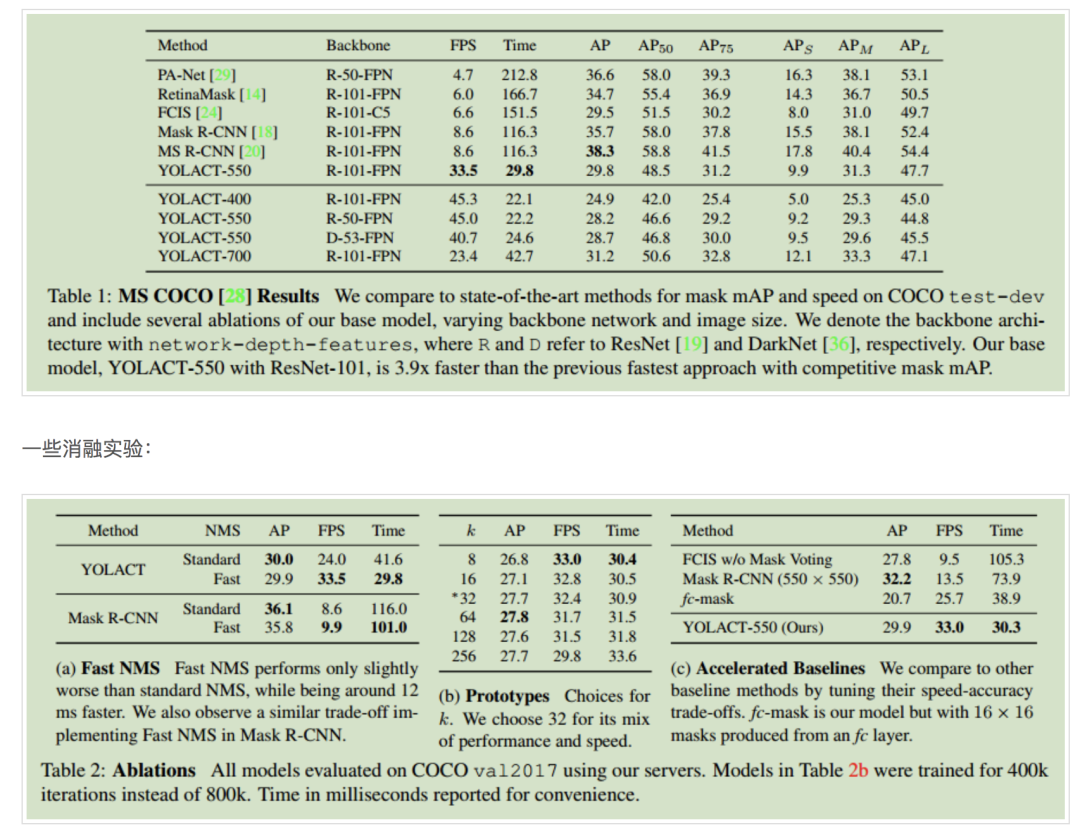
实验结果


在COCO上的对比结果:
总结
大多数错误来自于目标检测部分:误分类、边界框误对准。但是,除此之外,掩膜生成算法部分也有两个典型的错误:
定位失败:如果在一个场景中的某一个点上有着太多的目标,那么网络则无法在prototype中定位每一个目标。在这种情况下,网络将输出与前景掩膜更为接近的而不是这一组中的一些目标实例分割。
泄露:该算法的裁剪步骤是在掩膜集成后进行的,因而无法过滤裁剪区域之外的噪声。当边界框是准确的时候,这一方法有着较好的效果,但当边界框不准确的时候,噪声将被裁剪进实例的掩膜中,导致裁剪区域之外的掩膜的泄露。同时,当预测的边界框太大时,掩膜中也会包含一些离得很远的实例掩膜。
导致AP差距的原因:作者认为这一差距是由检测器相对差的性能所导致的,而不是产生masks的方法。
YOLACT YOLACT++ 获取方式:
关注微信公众号 datayx 然后回复 实例分割 即可获取。
YOLACT++
YOLOACT++ Better Real-time Instance Segmentation
https://arxiv.org/abs/1912.06218
在YOLACT的基础上,作者进一步进行了如下修改,来得到一个准确度更高的实例分割模型。
在backbonde网络中加入可变形卷积(deformable convolutions);
使用更好的anchor尺度和比例对prediction head进行优化;
加入新的mask re-scoring支路。
最终,在MS COCO上,YOLACT++可以获得34.1mAP和33.5fps的成绩,其精度已经非常接近SOTA模型。
Fast Mask Re-Scoring分支
对于模型来说,其分类置信度和预测的掩膜的质量之间是存在差异的。为此,作者引入了一个fast mask re-scoring分支,该分支依据所预测的掩膜与ground-truth的IoU对掩膜进行评分。具体来说,Fast Mask Re-Scoring网络由6层FCN组成,每一层卷积层之后跟一层ReLU,最后一层为全局池化层。该网络以YOLACT所输出的裁剪过的mask(未经过阈值)为输入,输出mask对于每一个目标种类的IoU。接着,将分类分支预测的类别所对应的mask IoU与相对应的类别置信度的乘积作为该mask最终的分数。
与Mask Scoring R-CNN相比,作者提出的方法有以下不同:
输入为全尺寸的图像的mask(预测框之外的区域值为0),而Mask Scoring R-CNN输入的是RoI repooled的掩膜与来自于掩膜预测分支的特征图所拼接得到的;
没有全连接层,因而本方法更快,加入Fast Mask Re-Scoring分支后时间仅增加了1.2ms。
可变形卷积
通过加入可变形卷积,mAP提高了1.8,速度慢了8ms。作者认为性能提升的原因有以下几点:
通过和目标实例进行对准,使得网络可以处理不同尺度、旋转角度和比例的实例;
YOLACT本身没有再采样策略,因而一个更好、更灵活的采样策略更重要。
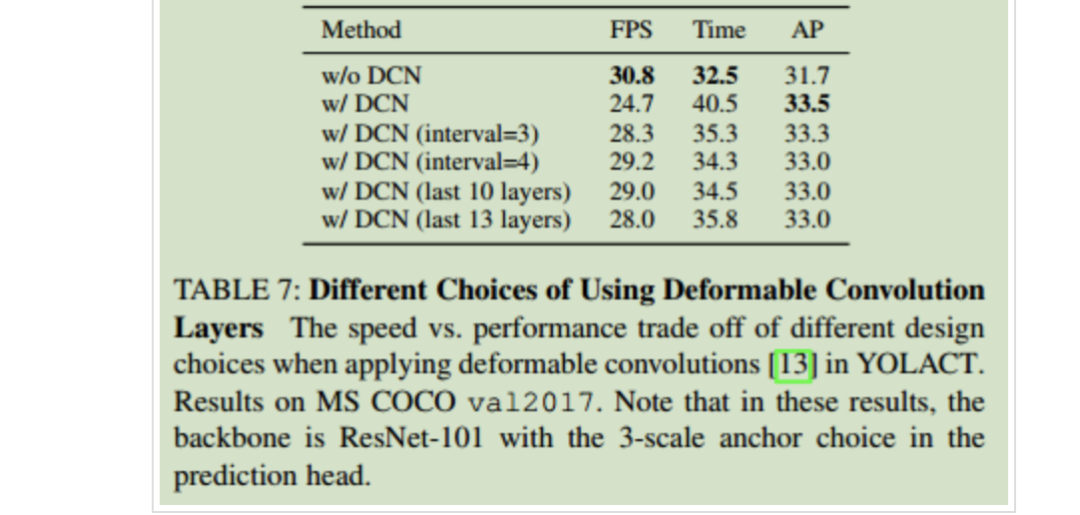
同时作者发现,在引入可变形卷积时需要选择合适的插入位置才能取得性能的提升。

实验结果
下图为YOLACT和YOLACT++的实验结果对比:

下表为加入改进措施后的性能提升:
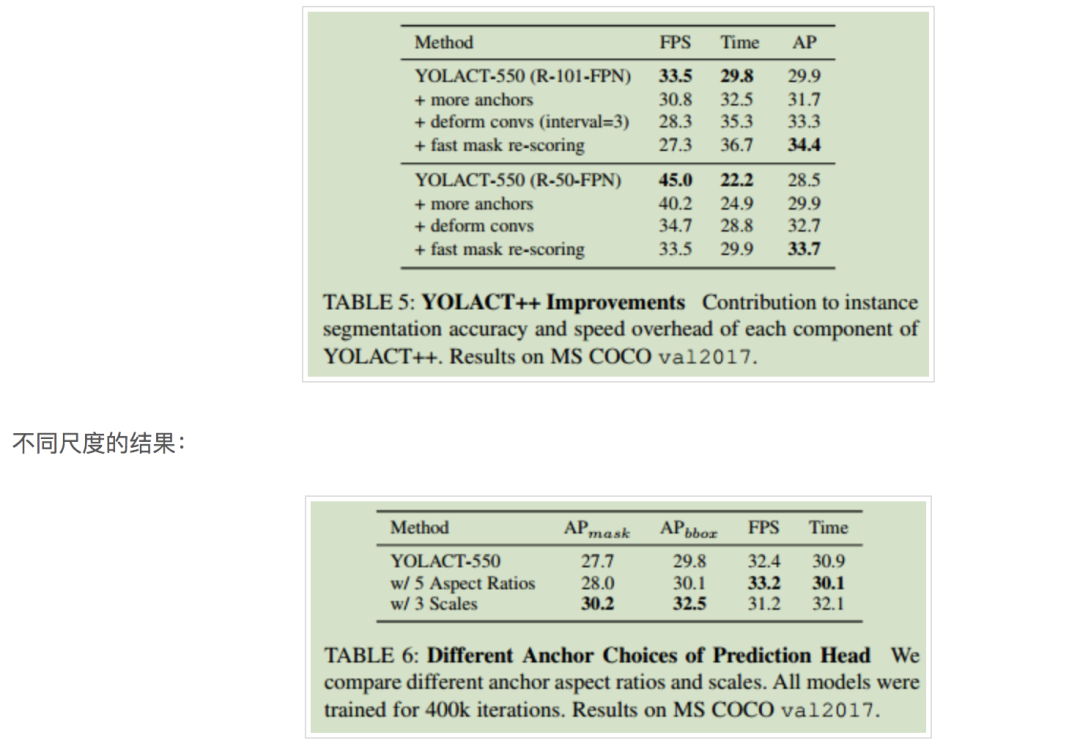
可变形卷积的不同插入位置的结果对比:
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx