
CondInst:性能和速度均超越Mask RCNN的实例分割模型
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!

对于实例分割来说,主流的做法还是基于先检测后分割的流程,比如最流行的Mask RCNN模型就是构建在Faster RCNN基础上。目前基于one-stage的物体检测模型已经在速度和性能上超越two-stage模型,同样地,大家也希望能找到one-stage的实例分割模型来替换Mask RCNN。目前这方面的工作主要集中在三个方向:
Mask encoding:对2D mask编码为1D representation,比如PolarMask基于轮廓构建了polar representation,而MEInst则将mask压缩成一个1D vector,这样预测mask就类似于box regress那样直接加在one-stage检测模型上; 分离检测和分割:将检测和分割分离成两个部分这样可以并行化,如YOLACT在检测模型基础上额外预测了一系列prototype masks,然后检测部分每个instance会预测mask coeffs来组合masks来产生instance mask,BlendMask是对这一工作的进一步改进; 不依赖检测的实例分割:不依赖检测框架直接进行实例分割,TensorMask和SOLO属于此种类型,前者速度太慢,后者速度和效果都非常好;
对于mask encoding方法,虽然实现起来比较容易,但是往往会造成2D mask的细节损失,所以性能上会差一点;分离检测和分割,对于分割部分可以像语义分割那样预测global mask,分辨率上会更高(要知道Mask RCNN的mask分辨率只有28x28),但是这种方法需要一种好的方式来产生instance mask;不依赖检测而直接进行实例分割这可能是未来的趋势。这里介绍的CondInst,其实属于第二种,但是它与YOLACT不同,其核心点是检测部分为每个instance预测不同的mask head,然后基于global mask features来产生instance mask,思路非常简单,而且实现起来也极其容易(已经开源在AdelaiDet),更重要的是速度和效果上均超越Mask RCNN。
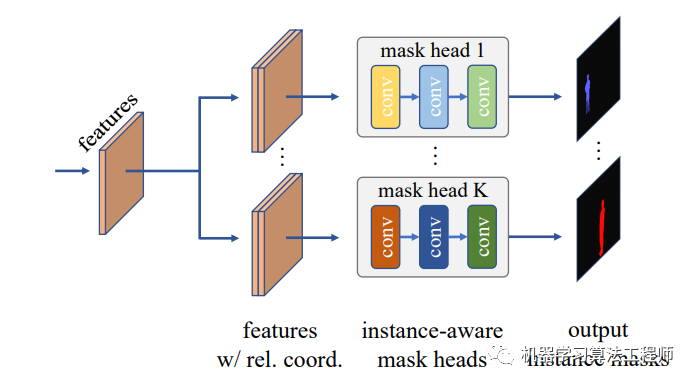
整体结构
CondInst是构建在物体检测模型FCOS之上的(CondInst和FCOS是同一个作者),所以理解CondInst必须先理解FCOS,可以参考之前关于FCOS的介绍文章(FCOS),但其实CondInst也可以依赖其他的one-stage模型,CondInst整体结构如下图所示:
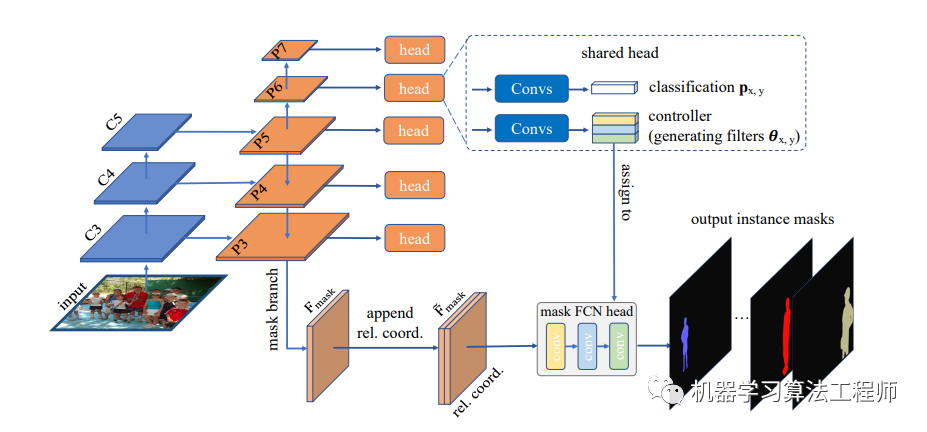
相比FCOS,CondInst多了一个mask branch,其得到的mask features将作为mask FCN的输入来生成最终的instance mask,这个mask features来自于P3,所以大小是输入图像的1/8。另外在FCOS的检测部分增加了controller head(实际上controller head是直接加在box head上的),用来产生每个instance的mask head网络的参数。这个思想其实是CondConv,传统的Conv训练完成后是固定的filters,但是CondConv的filters基于input和一个另外的网路来动态产生的。CondInst用来controller head生成instance-aware的mask FCN head,每个instance都有自己独有的mask head,instance的形状和大小等信息都编码在其中。所以当mask head作用在global mask features上时,就可以区分当前的instance和其它背景信息,从而预测出instance mask。
这样CondInst就可以实现实例分割了,CondInst的正负样本策略和FCOS一样,都是通过center region sampling方式来决定正负样本,其训练的loss相比FCOS增加intance mask的loss,这个loss也只计算正样本部分:
Mask Branch
CondInst的mask branch就和语义分割类似是一个FCN网络,包括4个channel为128的3x3卷积,然后最后接一个channel为8的1x1卷积。mask branch输入为FPN的P3特征,所以最终产生的特征为原始输入图像的1/8,特征channel为8,之所以用一个较小的channel是为了减少controller head所需生成的参数量,而且实验中发现采用较小的channel就够了,当channel为2时mask AP仅掉了0.3%。不过从开源的代码来看,mask branch的输入应该是来自于FPN的P3,P4和P5,具体实现上先将P4和P5的特征通过双线性插值,然后和P3加到一起作为mask branch的输入。就像YOLACT一样,mask branch产生的特征还可以额外加上语义分割的loss来进行辅助,这个不会影响inference过程,但是实验上mask AP大约可以提升1个点,具体实现上如下:
# 额外的语义loss,采用focal loss
if self.training and self.sem_loss_on:
logits_pred = self.logits(self.seg_head(
features[self.in_features[0]]
)) # 预测logits,区分class
# 计算语义分割的gt,这里的原则是合并instance的gt mask,但是当不同instance有重叠时,会取面积最小的instance的class作为gt
semantic_targets = []
for per_im_gt in gt_instances:
h, w = per_im_gt.gt_bitmasks_full.size()[-2:]
areas = per_im_gt.gt_bitmasks_full.sum(dim=-1).sum(dim=-1)
areas = areas[:, None, None].repeat(1, h, w)
areas[per_im_gt.gt_bitmasks_full == 0] = INF
areas = areas.permute(1, 2, 0).reshape(h * w, -1)
min_areas, inds = areas.min(dim=1)
per_im_sematic_targets = per_im_gt.gt_classes[inds] + 1
per_im_sematic_targets[min_areas == INF] = 0
per_im_sematic_targets= per_im_sematic_targets.reshape(h, w)
semantic_targets.append(per_im_sematic_targets)
semantic_targets = torch.stack(semantic_targets, dim=0) # [N, 1, H, W]
# 对gt进行降采样,为原始的1/8
semantic_targets = semantic_targets[:, None, self.out_stride // 2::self.out_stride, self.out_stride // 2::self.out_stride]
# one-hot gt
num_classes = logits_pred.size(1)
class_range = torch.arange(num_classes, dtype=logits_pred.dtype, device=logits_pred.device)[None, :, None, None]
class_range = class_range + 1
one_hot = (semantic_targets == class_range).float()
num_pos = (one_hot > 0).sum().float().clamp(min=1.0)
# 采用focal loss
loss_sem = sigmoid_focal_loss_jit(
logits_pred, one_hot,
alpha=self.focal_loss_alpha,
gamma=self.focal_loss_gamma,
reduction="sum",
) / num_pos
losses['loss_sem'] = loss_sem
return mask_feats, lossesController Head
前面说过,CondInst的核心就在于controller head,其用来产生mask head的网络参数,这个参数是每个instance所独有的,所以当输入为全局mask特征时,可以预测出instance mask。由于controller head会编码instance的形状和大小信息,所以它是直接加在FCOS的box head上的,就和centerness head一样。
controller head的输出channel数为N,恰好是mask head的网络参数量。mask head采用一个轻量级的FCN网络,包含三个channel为8的3x3卷积层,卷积之后接ReLU,最后一层卷积直接加上sigmoid(二分类)就可以预测instance mask。所以mask head的参数量N为169:(#weights = (8 + 2) × 8(conv1) + 8 × 8(conv2) + 8 × 1(conv3) and #biases = 8(conv1) + 8(conv2) + 1(conv3))。这里的输入channel是8+2,而不是8,是因为送入mask head的输入除了包括,还包含relative coordinates maps,即相对于当前instance的位置(x,y)的相对位置坐标,在实现上只需要把x,y的relative coordinates maps与拼接在一起即可,如果去掉相对位置maps,CondInst性能下降比较厉害,其实也合理,因为controller head产生的mask head参数是由CNN得到的,它虽然可以编码instance的shape信息,但是不能准确地学习到instance在图像中的位置,所以加上relative coordinates maps对准确地分割当前instance比较重要。另外论文中的一个有趣的实验是mask head只输入relative coordinates maps就可以得到31.3%的mask AP值,这或许说明controller head产生的mask head足够强大。下面是对controller head的输出进行结构化解析的代码:
def parse_dynamic_params(params, channels, weight_nums, bias_nums):
assert params.dim() == 2
assert len(weight_nums) == len(bias_nums)
assert params.size(1) == sum(weight_nums) + sum(bias_nums)
num_insts = params.size(0)
num_layers = len(weight_nums)
params_splits = list(torch.split_with_sizes(
params, weight_nums + bias_nums, dim=1
))
weight_splits = params_splits[:num_layers]
bias_splits = params_splits[num_layers:]
for l in range(num_layers):
if l < num_layers - 1:
# out_channels x in_channels x 1 x 1
weight_splits[l] = weight_splits[l].reshape(num_insts * channels, -1, 1, 1)
bias_splits[l] = bias_splits[l].reshape(num_insts * channels)
else:
# out_channels x in_channels x 1 x 1
weight_splits[l] = weight_splits[l].reshape(num_insts * 1, -1, 1, 1)
bias_splits[l] = bias_splits[l].reshape(num_insts)
return weight_splits, bias_splits由于输入的是1/8图片大小,所以产生的instance mask也是1/8图片大小,为了产生高质量的mask,采用双线性插值对预测的instance mask上采样4x,那么最终输出的instance mask就是1/2图片大小。mask部分的loss采用的是dice loss,它和focal loss一样可以解决正负样本不均衡问题,在计算时将gt mask下采样2x以和预测mask达到同样的大小。
Inference
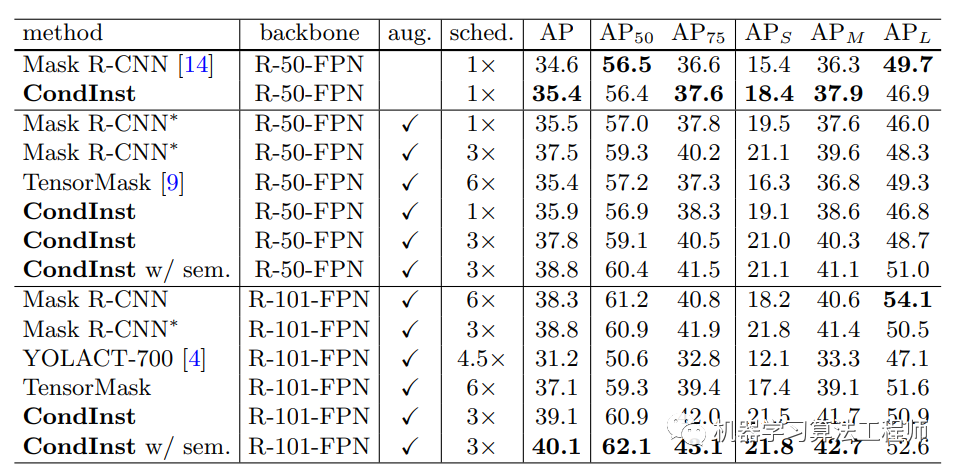
CondInst的inference就比较直接了,首先是检测部分得到检测的结果,然后采用box-based NMS来去除重复框,最后选出top 100的检测框,只有这部分instances会进行instance mask的预测。由于产生的mask head非常小,所以100个instance的mask预测时间只需要4.5ms,那么CondInst的预测时间仅比原始的FCOS增加了约10%。这里额外要说的一点是CondInst的box预测主要用于NMS,但不会参与instance mask的预测中,而Mask R-CNN是需要box来进行ROI croping。CondInst和其它实例分割在COCO上的效果对比如下:
此外,CondInst的作者近期又发布了一篇新的不错的工作:BoxInst,只用box级别的标注就可以训练出一个不错的实例分割模型,这个模型也是构建在CondInst上,只不过设计了两个新的loss来进行半监督式的训练。最后放一个BoxInst的一个分割视频demo:
参考
Conditional Convolutions for Instance Segmentation AdelaiDet BoxInst: High-Performance Instance Segmentation with Box Annotations
推荐阅读
mmdetection最小复刻版(十一):概率Anchor分配机制PAA深入分析
MMDetection新版本V2.7发布,支持DETR,还有YOLOV4在路上!
无需tricks,知识蒸馏提升ResNet50在ImageNet上准确度至80%+
不妨试试MoCo,来替换ImageNet上pretrain模型!
mmdetection最小复刻版(七):anchor-base和anchor-free差异分析
mmdetection最小复刻版(四):独家yolo转化内幕
机器学习算法工程师
一个用心的公众号
